作为传统关系型数据库,MySQL 的分布式倾向于存储方面:将数据分散存储到各个节点,减少单个节点的读写压力、存储压力
同时,MySQL 原生支持了主从复制,实现了数据的冗余存储,保障了可用性
结构
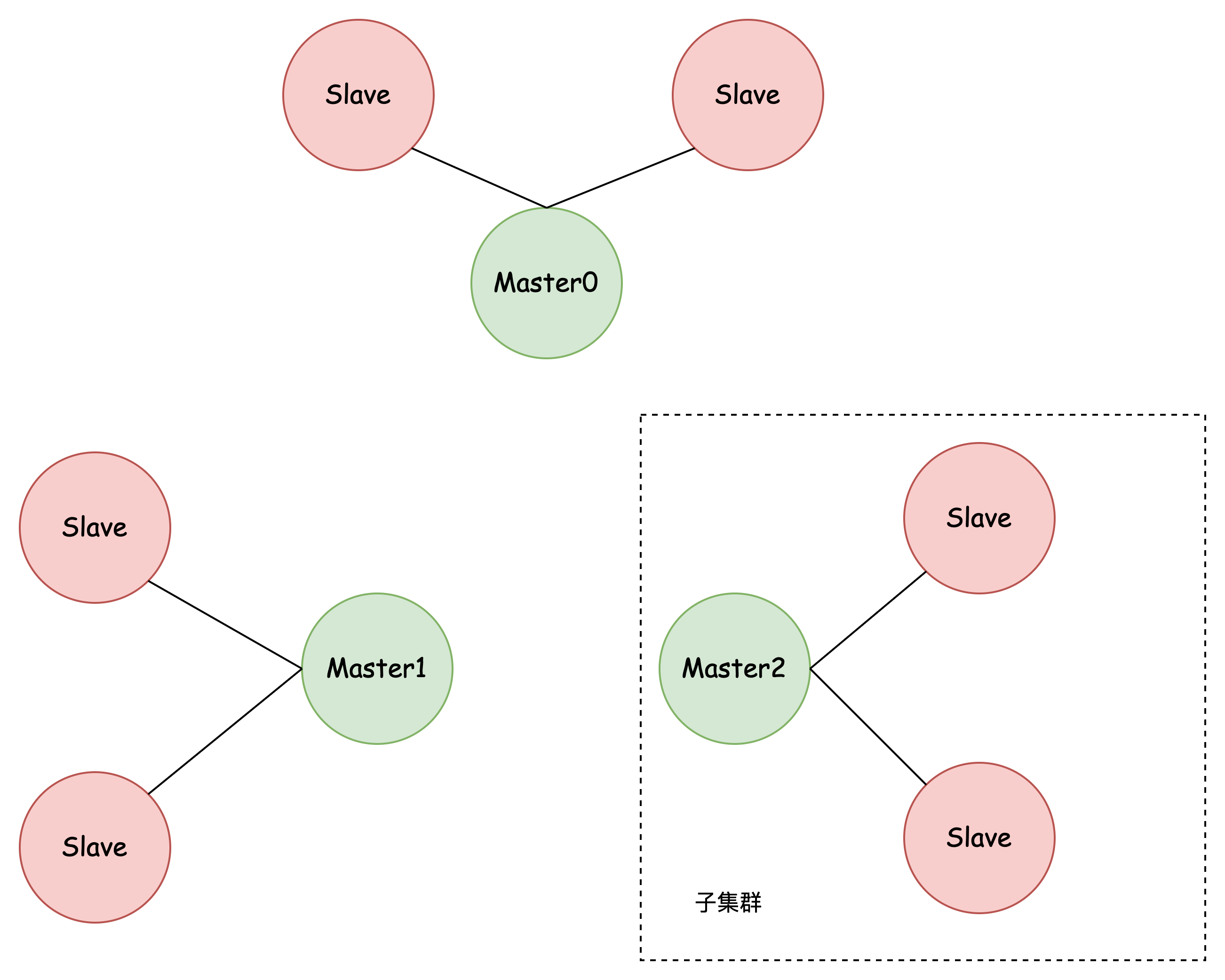
- 数据分散存储到各个主节点,减少单个节点的读写压力、存储压力
- 从节点冗余存储主节点数据,保障了可用性,还可以实现读写分离,进一步减少主节点读压力
- 子集群之间没有直接关联,需要应用层实现
如何实现服务注册、服务发现
假设有一个主节点,我们要想为这个主节点添加从节点,需要在从节点上 手动 指定主节点的位置:
CHANGE MASTER TO
MASTER_HOST=$host_name
MASTER_PORT=$port
MASTER_USER=$user_name
MASTER_PASSWORD=$password
master_auto_position=1 -- 指定使用 GTID 确定位点
指定以后,从节点就知道了主节点的位置,同样的,主节点也会知道从节点的位置
但是主节点之间是无法发现彼此的,此外,对于应用层来说,MySQL 原生并不支持服务注册、服务发现,通常需要手动实现,或者引入一个 Proxy 层
如何将请求路由到正确的节点
我们将请求分为两类:
- 读请求
- 写请求
假设我们做了数据分片(分库分表),那么在执行读写请求前,就要先确定数据存储的位置
实现方式有两种:
- 应用层代码手动实现
- 引入 Proxy 层
应用层代码手动实现
应用程序主动做负载均衡,这种模式下一般会把数据库的连接信息放在客户端的连接层。也就是说,由客户端来选择后端数据库进行查询。
这种方式的性能较好,缺点就是需要对已有代码进行修改
基于 Proxy(代理层)实现
这个方式就是在 Client 到 Server 之间引入一个代理,自动分发客户端的请求:
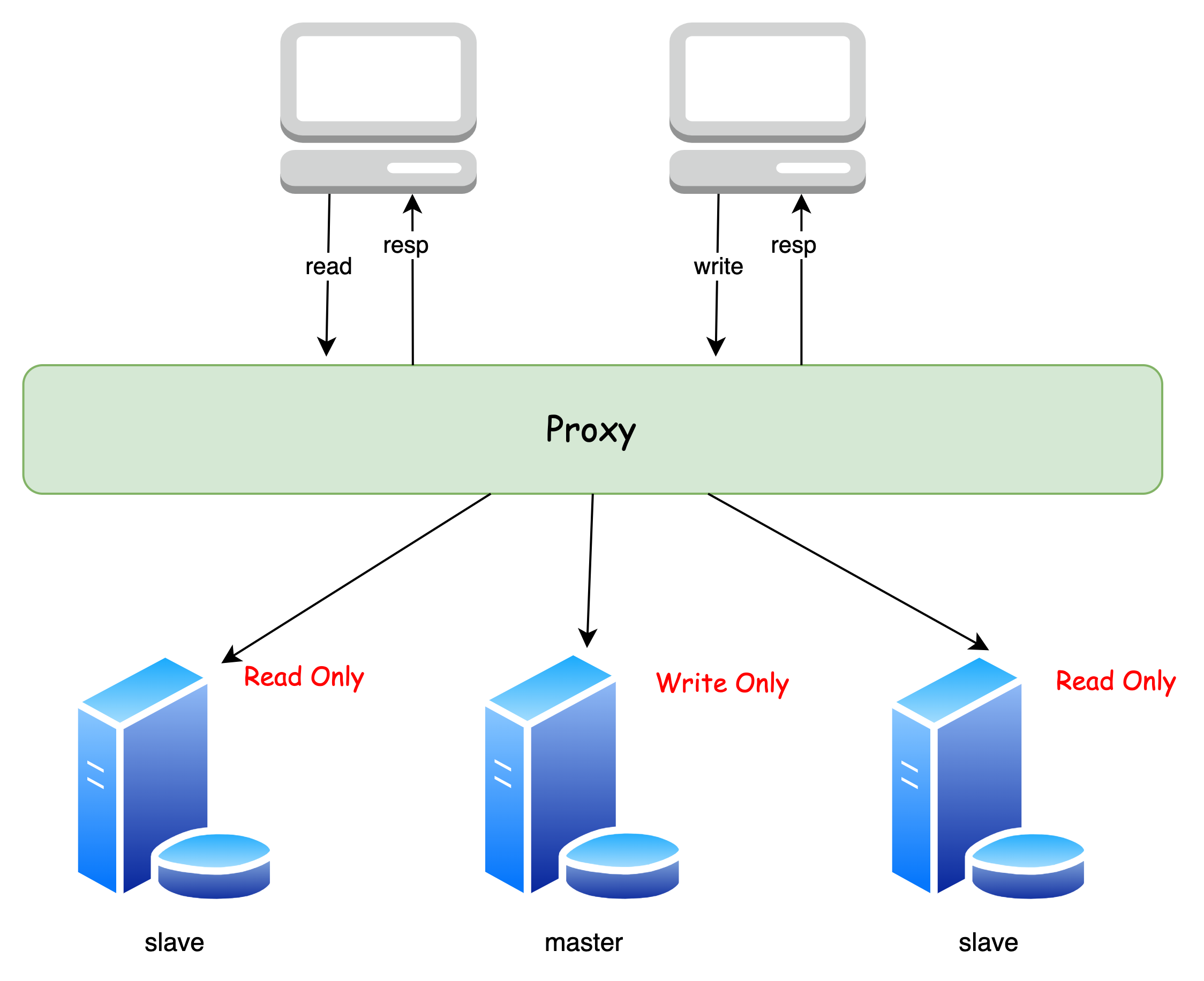
Proxy 会负责请求的分发与负载均衡
这种方式的优点就是不用修改已有代码,但是有一定的性能损耗
如果要实现读写分离,同样的,也是上面两种方式
C、A 如何做权衡(trade-off)
这里讨论的主要是读写分离的情况
由于主从复制会存在延迟,在读写分离的情况下,我们就需要在 C、A 之间做 trade-off,通常有以下几种实现方式
强制走主库
一些对数据一致性要求很高的业务(如金融),可以采取这种方式,保证绝对的数据一致性,纯粹的 C
缺点就是:如果很多业务都有很高实时性要求,都走主库,会 对主库造成很大压力
强制走从库
一些对数据一致性要求不高的业务(如互联网应用),可以采取这种方式,保证可用性,纯粹的 A
Sleep
既然同步需要时间,那我们可以「sleep」一下,等它同步完了再去访问不就好了吗
例如,一个用户发布了一个商品,前端可以基于本地已有信息进行展示,就好像获取到了最新的数据一样
用户待会刷新页面,其实已经过了一段时间,也就达到了 sleep 的目的,只要等待时间内同步完成,访问的就是最新的数据
这种方式适用于对数据实时性要求低的业务,就算访问到过期数据也影响不大
缺点就是:我们无法保证在规定时间内主从同步完毕,还是 有访问到过期数据的可能性
判断主从无延迟方案
这种方式比较折中
- 在访问数据之前,判断主从是否同步完毕:
- 如果同步完毕,那么走从库,获取的是最新数据
- 如果没有,可以等待一段时间,重复第一个步骤
- 如果等待时间 超过一定阈值,那么根据实际需求,看看是走主库,获取最新数据;或者走从库,获取过期数据
如何做数据分片
我们可以将数据分散存储到不同的主节点上
通常的实现方式有:
- 哈希分片
- 一致性哈希
- 范围分片
哈希分片
根据指定 key(比如 id) 的哈希值,算出这个数据在哪个库(表)中
哈希分片算法比较适合 随机 查询的场景,并能 一定程度避免单个库上的热点问题,不适合范围查询
范围分片
按照指定范围区间来分配数据,例如,将 id 为 1 ~ 10000 的存在第一个 DB,id 为 10001 ~ 20000 的存在第二个 DB
范围分片算法比较适合 范围 查询的场景,但有可能 存在 单个库上的 热点问题
数据如何同步(复制)到各个节点
这里讨论的是 MySQL 的主从复制
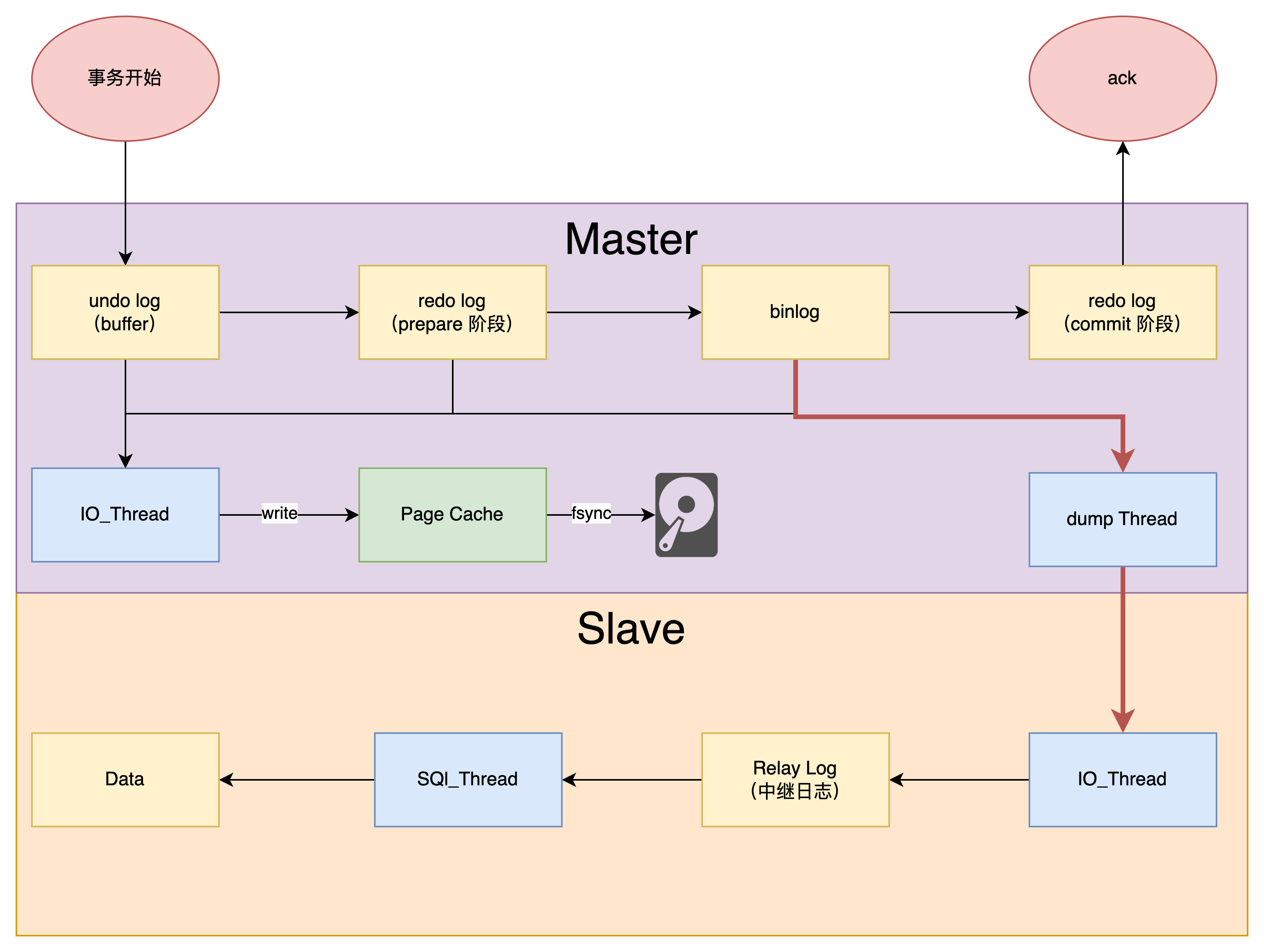
简单来说,就是从库的 IO_Thread 将主库发来的 binlog 写到本地的 relay log,然后由 SQL_Thread 负责拉取 relay log 完成主从复制
binlog 是主库主动推送,还是从库主动拉取?
一开始创建主备关系的时候,是由备库指定的。
比如基于位点的主备关系,备库说“我要从 binlog 文件 A 的位置 P”开始同步, 主库就从这个指定的位置开始往后发。
而主备复制关系搭建 完成以后,是 主库 来 决定“要发数据给备库” 的。
所以主库有生成新的日志,就会发给备库。
如何实现故障转移
主节点挂了,从节点怎么办?
MySQL 没有自动的故障转移,需要手动转移
大致步骤如下:
- 选择一个从库
- 将其设置为新的主库
- 修改剩余从库的 master 为新的主库
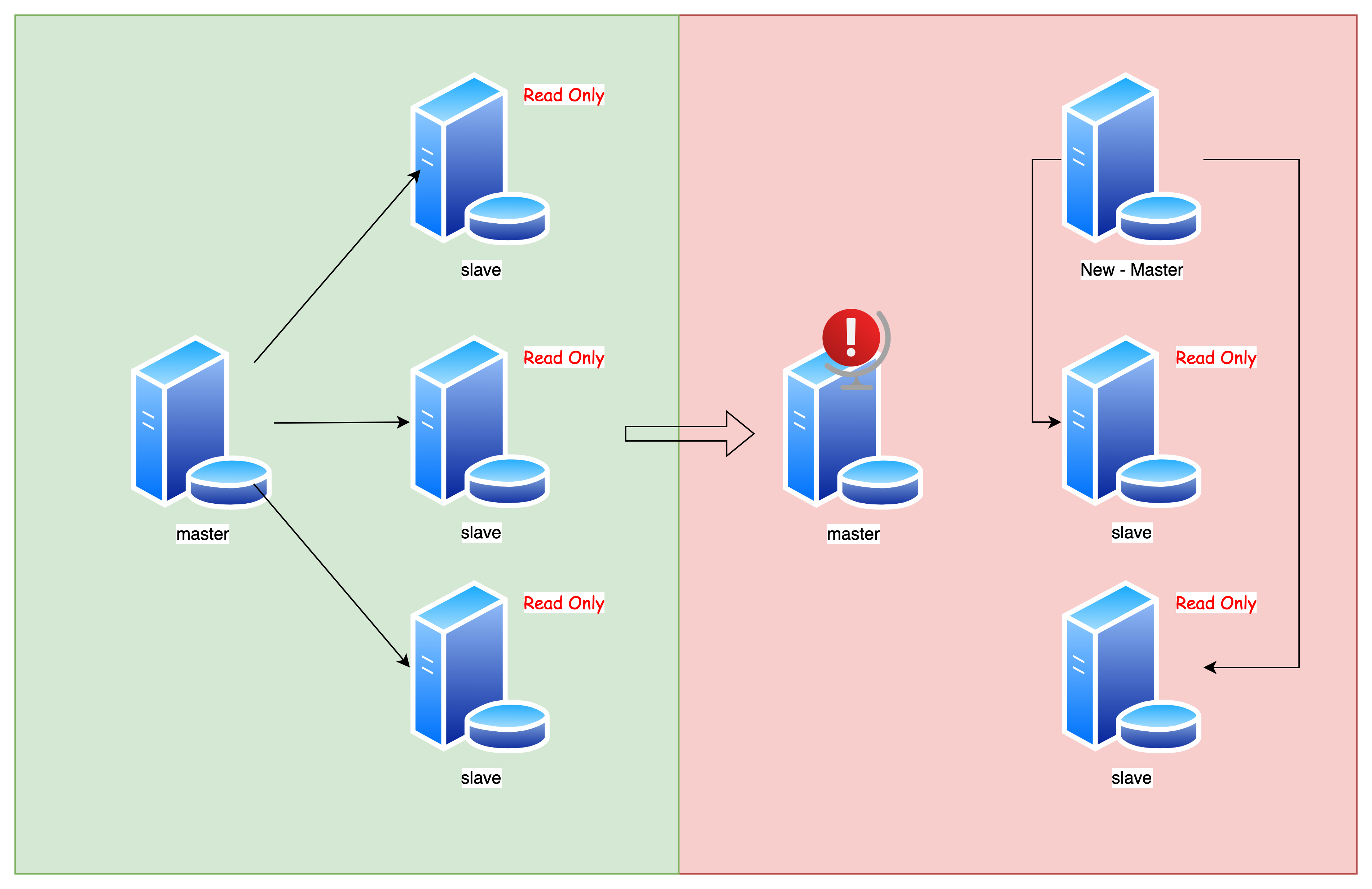
但问题是:其它从节点应该怎么去同步新的主节点的数据呢?
难点:从库去同步新的主库的数据,不是全量同步,而是增量同步,如何寻找这个同步的「起始点」?
MySQL 5.6 引入了 全局事务 ID(GTID),是一个事务的唯一标识
在 GTID 模式下,从库获取新的主库的位点这件事情就在 MySQL 内部做好了:
CHANGE MASTER TO
MASTER_HOST=$host_name
MASTER_PORT=$port
MASTER_USER=$user_name
MASTER_PASSWORD=$password
master_auto_position=1 -- 指定使用 GTID 确定位点
想要更深入的了解 GTID 的实现,可以看看这篇文章:27 | 主库出问题了,从库怎么办?
如何实现分布式事务
MySQL 使用两阶段提交(2PC)实现分布式事务:
两阶段提交将 事务提交过程 分为两个阶段,保证主从节点间数据的一致性:
- 准备阶段(prepare)
- 提交阶段(commit)
使用两阶段提交时,MySQL 内部开启一个 XA 事务:
在 prepare 阶段,将 XID 写入 redo log,并 将 redo log 状态设置为 prepare,然后调用 write、fsync(类似于 innodb_flush_log_at_trx_commit = 1),将 redo log 持久化到磁盘
在 commit 阶段,将 XID 写入 binlog,然后调用 write、fsync(类似于 sync_binlog = 1),将 binlog 持久化到磁盘,并 将 redo log 状态设置为 commit
当然,上面所指的事务,涉及到的数据应该仅在同一个主库中,分布式体现在 一主多从
如果涉及到多个主库(多主多从),MySQL 原生就无能为力了,可以使用:
- 基于消息队列的异步处理:将事务操作写入消息队列,由消费者进行处理。这种方式可以利用 MQ 的事务机制实现跨多个数据库的分布式事务,但可能会引入一定程度的异步性和延迟。
- 分布式事务中间件:使用第三方的分布式事务中间件(如 Seata)来实现分布式事务。这些中间件通常提供了对分布式事务的原生支持,能够简化开发和管理复杂的分布式事务场景。
- 应用程序层面的解决方案:在应用程序层面实现分布式事务逻辑。例如,通过在应用程序中使用 分布式锁、分布式协调服务(如 ZooKeeper)、分布式一致性算法(如 Paxos 或 Raft)等技术来保证事务的一致性。
总结
MySQL 作为传统关系型数据库的代表,其在分布式上的实现 并不完善,原生仅支持主从节点的复制