分布式系统是由 多个 独立的计算机或者节点组成的系统,这些计算机通过网络进行通信和协作,共同完成特定的任务或提供服务。
分布式系统的设计目标是:提高系统的性能、可伸缩性、可靠性和可用性,以及实现系统资源的有效利用。
接下来,主要围绕 如何学习分布式系统 来讨论
分布式系统解决了什么问题?
为什么要引入分布式系统?
在传统单体架构下,存在以下问题:
- 可用性低:一个机器挂了,整个服务就不可用了
- 扩展性成本高:单个机器的性能提升是比较有限的,升级成本高
因此,引入分布式系统,来解决单体架构下的 可用性问题 和 扩展成本问题
那么分布式系统是如何解决这两个问题的呢?
简单理解:就是通过网络,将许多物理机连起来,组成一个集群,对外提供服务,并通过在系统中提供冗余来保障可用性
分布式系统带来了什么问题
整个分布式系统具有多个物理节点,那么如何协调这些节点,就是一个比较重要的问题
我们将分布式系统分为两类:
- 分布式计算
- 分布式存储
分布式计算带来了什么问题
如何找到服务
在整个分布式系统中,物理节点间的身份可能不同
那么节点间如何发现彼此呢?
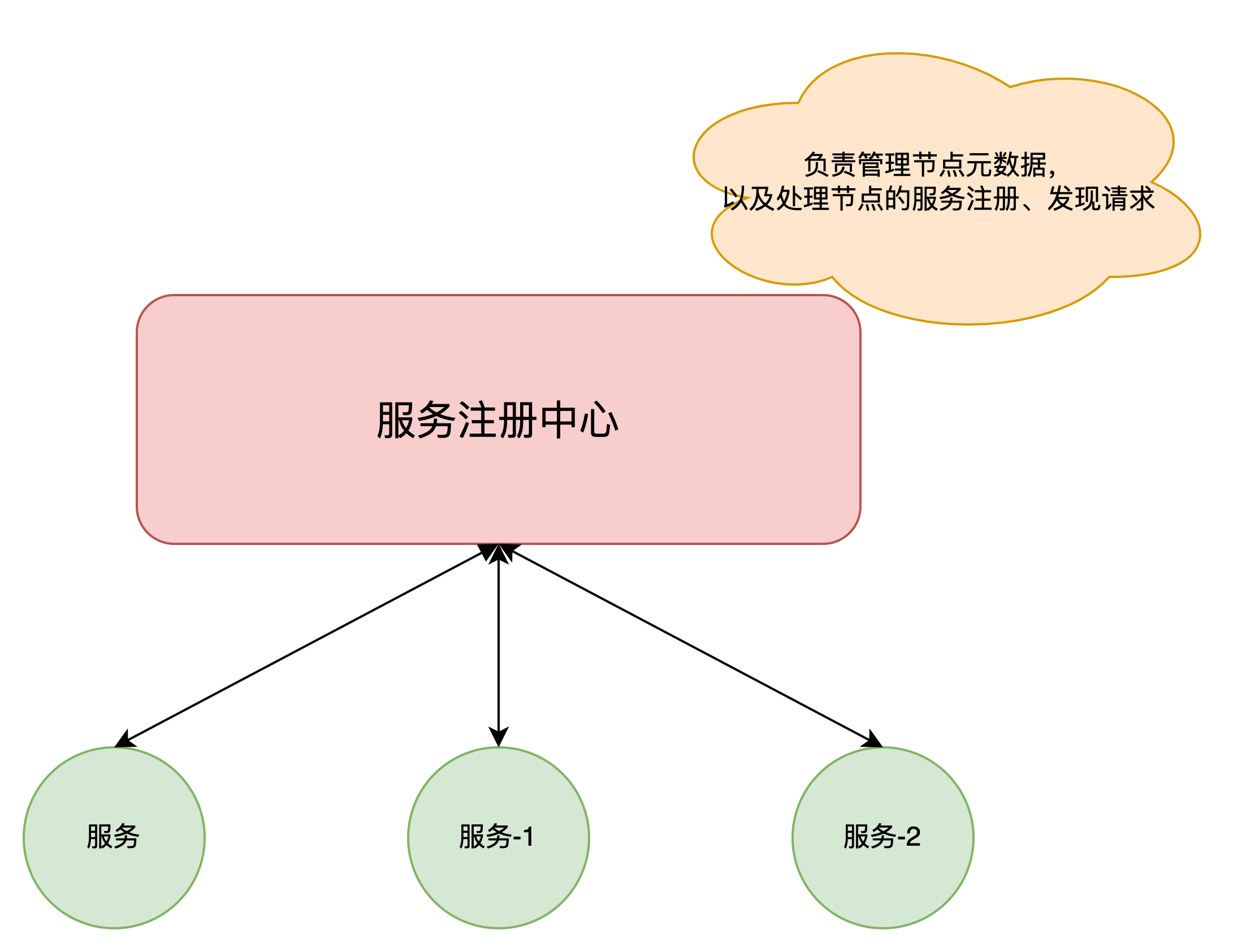
常见的解决方案是「服务注册与发现」
实现这个功能,通常需要一个「服务注册中心」
- 服务注册:当一个服务启动时,它会向服务注册中心注册自己的信息,包括服务名称、IP 地址、端口号等。注册中心会将这些信息保存起来,以便其他服务或客户端查询。
- 服务发现:当一个服务需要调用其他服务时,它会向服务发现组件发送查询请求,询问特定服务的位置信息。服务发现组件会从注册中心获取服务的信息,并将其返回给请求方,使得请求方能够直接与目标服务通信。
如何找到(实例)节点
确定了服务以后,如何确定将当前请求路由到哪个节点上呢?
分两种情况:
- 无状态:同一个服务之间,每个(实例)节点完全一致,例如 Redis 集群,主从节点存储数据(几乎)一致
- 有状态:同一个服务之间,(实例)节点不完全一致,例如 Redis 集群,主节点之间存储的数据不一致
对于「无状态」这种情况,做好普通的负载均衡就 ok 了,例如:
- 简单的轮询机制
- 一致性哈希
- fair 公平调度
对于「有状态」这种情况,由于节点间不一致,这种情况通常需要一个「路由服务」,因提前确定要请求的数据在哪个节点上,然后再访问
如何避免服务雪崩
一个服务内,某个节点挂了,那么该节点负责的请求就会打到其它节点上
如果剩余节点中,有一个节点因为承受不了多的请求,挂了,那么该节点负责的请求又会打到其它节点上
如此循环,导致整个服务的节点依次挂掉,就像「雪崩」一样
如何避免?
整体分为两个思路:
- 快速失败与降级机制:服务降级、熔断机制、限流
- 弹性扩容:添加新的节点到服务中
快速失败会导致部分请求无法正确响应
而弹性扩容成本较高,并且扩容这个过程本身需要时间
如何监控告警
对于分布式系统,如果我们不知道整个系统的负载情况(状态),那么整个系统的可用性是无法得到保障的
可以监控某个接口的时延、成功响应数
也可以监控整个系统的负载,并在高负载时告警
分布式存储带来了什么问题?
CAP 理论
CAP 理论是分布式系统设计中的一个重要理论,描述了分布式系统中三个核心属性之间的冲突:
- 一致性(Consistency):即所有的节点在同一时间具有相同的数据视图。在一致性模型中,如果一个操作在一个节点上执行成功后,其他节点上的数据也应该立即变为一致。
- 可用性(Availability):即系统能够对用户的请求做出响应,即使系统中的一部分组件出现故障。在可用性模型中,系统在出现故障时仍然能够继续对外提供服务。
- 分区容错性(Partition Tolerance):即系统能够容忍网络分区(分布式系统中节点之间的通信可能出现故障),而不会导致系统的整体性能下降。在分区容错性模型中,系统能够在网络分区的情况下继续运行,并且不会受到太大影响。
一般来说,C 和 A 无法同时保障:
-
保证强一致性 C,那么在数据同步期间,整个服务无法读取(避免读到过期数据)
-
保证高可用性 A,那么即使数据未同步完毕,也要对外提供服务,弱一致性保障
-
对于银行这类系统,一致性非常重要,保障 CP;
-
对于互联网应用,可能不需要强一致性,最终一致就行,保障 AP
如何做数据分片
随着数据量的增加,单机肯定无法存储所有数据,因此需要将数据分配到多个节点存储
常见分片方式:
- 范围分片
- 哈希分片
- 一致性哈希分片
如何做节点间数据复制
为了保障可用性:即使一个节点挂了,它所负责的数据也要能获取到
可用性的保障,是基于数据的冗余存储的
那么如何将数据复制到其它节点呢?
- 中心化方案(主从复制、一致性协议比如 Raft)
- 去中心化方案
这两种方案,对外表现的一致性是不同的
如何实现分布式事务
要实现事务,首先需要有对并发事务进行排序的能力,这样在事务冲突的时候,确认哪个事务提供成功,哪个事务提交失败。
对于单机系统,只需要 时间戳 + TxID 即可
但是分布式系统,每个节点的时间肯定无法完全同步,这种方式就不太行了
不过可以 整体分布式,局部单体 来实现:用一台机器负责生成 时间戳 + TxID
这种方式在节点到中心节点的 距离较短 还可以,但是,如果节点到中心节点的距离较长,那么请求的 TTL 可能就不太能够接受了,时间成本太高
总结
学习分布式系统,可以从以下问题入手:
- 如何实现服务注册、服务发现
- 如何将请求路由到正确的节点
- 如何监控集群状态
- C、A 如何做权衡(trade-off)
- 如何做数据分片
- 数据如何同步(复制)到各个节点
- 如何实现分布式事务
进一步地,可以:
- 从实践出发:学习 MySQL(传统关系型数据库)、Redis(分布式缓存)、Kafka(分布式 MQ)的分布式实现方式
- 从理论出发:学习 MIT-6.824