CR(Chain Replication)
CR 是一种分布式存储协议,具有与 Raft 不一样的特性
基本原理
从名字可以看出,CR 的网络拓扑就像一条「链」一样:
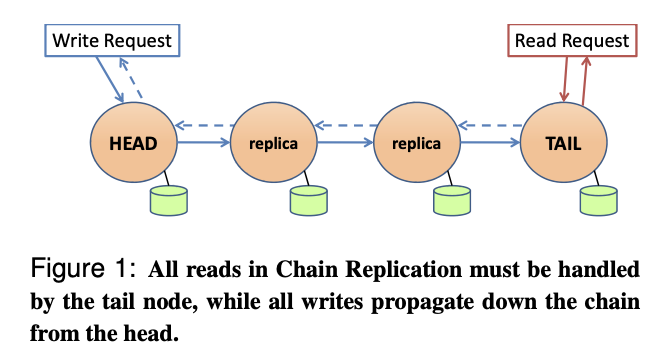
每个节点以「链」的方式排列,类似双向链表
写请求处理
客户端的写请求会发给 Head 节点处理
当 Head 节点收到一个写请求,会将这个写请求发送给后继节点,以此类推,最终到达 Tail 节点
Tail 节点收到了这个写请求后,会发送 ACK 给前驱节点,以此类推,最终到达 Head 节点
Head 节点收到 ACK 后,说明所有节点都完成了复制,于是 Commit 这条请求,并响应客户端
如果发生丢包,或者某个节点挂掉,导致 Head 没有收到 ACK,客户端请求超时怎么办?
一般来说,客户端请求超时会 重发 请求,这就要求 Head 节点具有 辨别重复请求 的能力,因为我们不希望重复执行请求
读请求处理
客户端的读请求会发给 Tail 节点处理
CR 这种方式,相当于将读写请求分离了,可以降低 Head 的压力,而 Raft 协议读写请求都在 Leader 进行,压力较大
一致性模型
CR 是 强一致性 保障的,读写请求均满足「线性一致」
对于读请求,只会由 Tail 节点处理,这意味着读取的数据肯定都是 Commit 的数据
对于写请求,只有 所有节点 都完成了复制,Head 节点才会收到 ACK,才会响应客户端
错误恢复
与 Raft 很多错误场景不同,CR 的错误恢复比较简单,只需要考虑三种场景:
- Head 挂了
- Tail 挂了
- 中间节点挂了
下面的话来自 Robert 教授 :
如果 HEAD 出现故障,作为最接近的服务器,下一个节点可以接手成为新的 HEAD,并不需要做任何其他的操作。对于还在处理中的请求,可以分为两种情况:
- 对于任何已经发送到了第二个节点的写请求,不会因为 HEAD 故障而停止转发,它会持续转发直到 commit。
- 如果写请求发送到 HEAD,在 HEAD 转发这个写请求之前 HEAD 就故障了,那么这个写请求必然没有 commit,也必然没有人知道这个写请求,我们也必然没有向发送这个写请求的客户端确认这个请求,因为写请求必然没能送到 TAIL。所以,对于只送到了 HEAD,并且在 HEAD 将其转发前 HEAD 就故障了的写请求,我们不必做任何事情。或许客户端会重发这个写请求,但是这并不是我们需要担心的问题。
如果 TAIL 出现故障,处理流程也非常相似,TAIL 的前一个节点可以接手成为新的 TAIL。所有 TAIL 知道的信息,TAIL 的前一个节点必然都知道,因为 TAIL 的所有信息都是其前一个节点告知的。
中间节点出现故障会稍微复杂一点,但是基本上来说,需要做的就是:将故障节点从链中移除。
或许有一些写请求被故障节点接收了,但是还没有被故障节点之后的节点接收,所以,当我们将其从链中移除时,故障节点的前一个节点或许需要重发最近的一些写请求给它的新后继节点。
假设第二个节点不能与 HEAD 进行通信,第二个节点能不能直接接管成为新的 HEAD,并通知客户端将请求发给自己,而不是之前的 HEAD?
这个问题描述的其实就是「网络分区」问题
如果采取这种方式,那么一条链上可能会存在 两个 Head,发生了「脑裂」
HEAD 还在正常运行,同时 HEAD 认为第二个节点挂了。然而第二个节点实际上还活着,它认为 HEAD 挂了。所以现在他们都会认为,另一个服务器挂了,我应该接管服务并处理写请求。因为从 HEAD 看来,其他服务器都失联了,HEAD 会认为自己现在是唯一的副本,那么它接下来既会是 HEAD,又会是 TAIL。第二个节点会有类似的判断,会认为自己是新的 HEAD。所以现在有了脑裂的两组数据,最终,这两组数据会变得完全不一样。
这肯定不是我们希望发生的,也就是说:原始的 CR 不具有应对「网络分区」和「脑裂」的能力
这意味着,CR 在实际应用中,不能单独使用
配置中心(Configuration Manager)
为了应对 CR 的「网络分区」和「脑裂」问题,一个可行的思路是:我们不能让 CR 链上的节点「自认为」某个节点挂了,而是需要一种「共识」
这种「共识」,需要依靠「外部的权威」(External Authority),来决定一个节点,到底是活的还是死的
我们将这种「外部的权威」称作「配置中心」(Configuration Manager)
配置中心本身必须是 容错 的,可以是 Raft,也可以是 Paxos
在 CR 的场景下,使用的是 ZooKeeper
ZooKeeper 在之前的文章也有提到,它基于 ZAB 协议,与 Raft 是类似的一种方案
Configuration Manager 通告给所有参与者整个链的信息,所以所有的客户端都知道 HEAD 在哪,TAIL 在哪,所有的服务器也知道自己在链中的前一个节点和后一个节点是什么。现在,单个服务器对于其他服务器状态的判断,完全不重要。假如第二个节点真的挂了,在收到新的配置之前,HEAD 需要不停的尝试重发请求。节点自己不允许决定谁是活着的,谁挂了。
这种架构极其常见,这是正确使用 Chain Replication 和 CRAQ 的方式。在这种架构下,像 Chain Replication 一样的系统 不用担心网络分区和脑裂,进而可以使用类似于 Chain Replication 的方案来构建非常高速且有效的复制系统。
缺点
写入速率受限
CR 同步写请求是以链的方式同步的,串行化,速度较慢
并且 CR 写入速率还会受到「慢」的节点的限制
因为 CR 需要等待 所有 节点复制完毕,才会 commit 一条写请求
而 Raft 这种使用「过半票决」的协议,就可以在一定程度上避免这个问题
无法独立使用
前面提到 CR 必须依靠「配置中心」,本身不具备应对网络分区和脑裂的能力
CRAQ(Chain Replication with Apportioned Queries)
CRAQ 是对 CR 的改进
基本原理
CRAQ 在 CR 的基础上增加了分摊查询(Apportioned Queries),即读请求不一定每次都在 Tail 节点进行,大幅提高读请求的处理能力
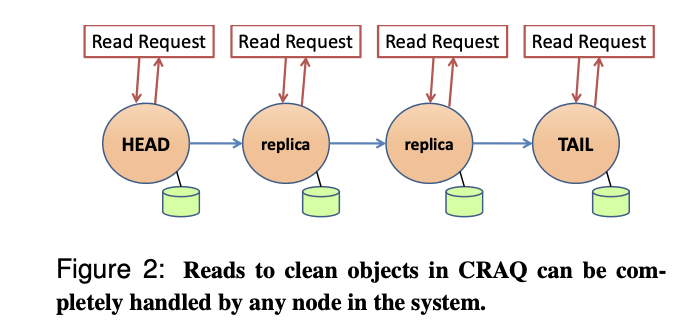
写入基本原理如下:
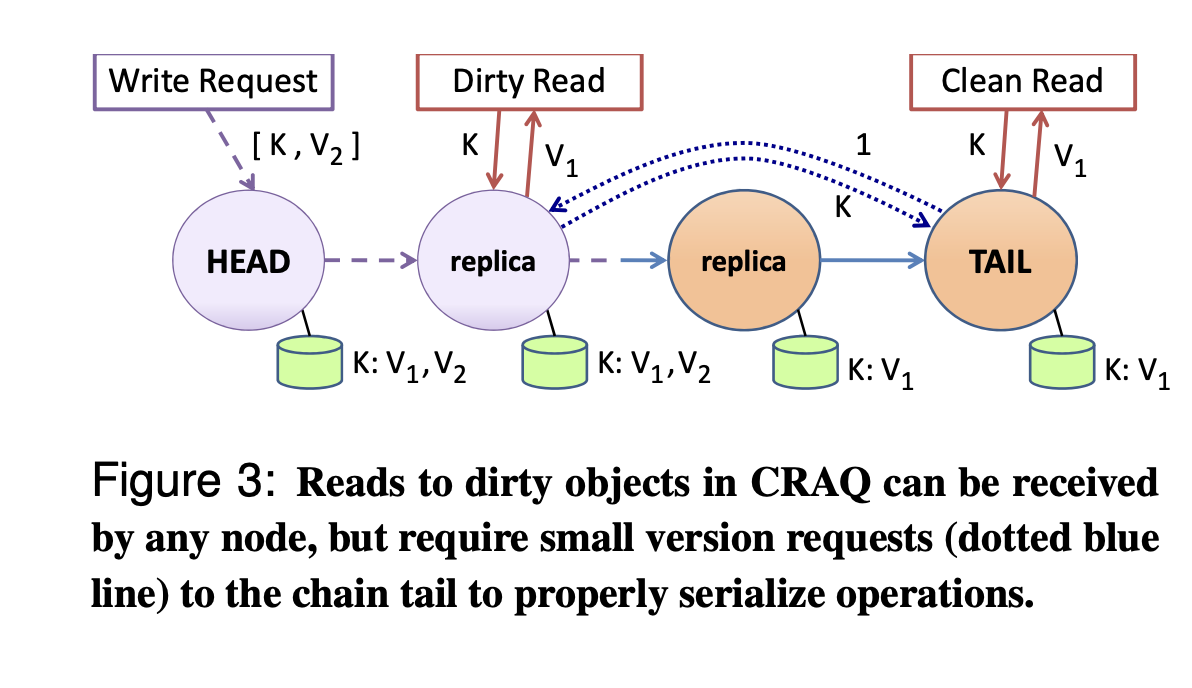
在 CR 的基础上,每个节点保存 多版本 的对象(有点类似 MySQL 的 MVCC),每个对象有一个版本号,以及标记(clean or dirty)
当一个节点收到写请求时,除了写入以外,还要处理标记:
- 如果本节点为 Tail 节点,那么标记为 clean
- 否则,标记为 dirty
当一个节点收到了 Tail 节点的 ACK 后,可以将 dirty 标记修改为 clean 标记
读取基本原理如下:
客户端可以在任意节点执行读请求
当一个节点收到了读请求,需要判断读取对象的标记:
- 如果是 clean,那么直接返回客户端结果,否则:
- 询问 Tail 节点,该对象的版本号
- 根据 Tail 节点返回的版本号,决定返回哪个对象给客户端
优势
读请求分发
从上面的分析可以看出,CRAQ 最主要的优势就是读请求分发,大幅提高读请求的吞吐
- 如果是 clean,直接返回
- 如果不是 clean,只会询问 Tail 版本号,而不是完整数据,降低了 Tail 的压力
广播降低写延迟
CR 节点间通信是「链式」的,串行化
而 CRAQ 相较于 CR,实现了 广播通信,并行化:
- 复制不需要串行沿链传播,而是广播到整个链
- 只有元数据才需要沿链传播
- 若节点没收到广播消息,它会从前驱节点拉数据(收到提交消息后,传播提交消息前)
- 尾节点也广播 ACK 消息给前面的节点,若前面的没收到,则会在下一次读时询问尾节点,从而让数据 clean
这种方式提高了写请求同步的效率,进一步提高写请求的吞吐,降低写延迟
一致性模型
容易发现,CRAQ 与 CR 一致,读写均满足线性一致性
这也是 CRAQ 最吸引人的地方:既能满足线性一致性,又能提供读请求的高吞吐