分布式事务主要由两部分组成。第一个是并发控制(Concurrency Control)第二个是原子提交(Atomic Commit)。
为什么要有分布式事务
之所以提及分布式事务,是因为对于拥有大量数据的人来说,他们通常会将数据进行分割或者分片到许多不同的服务器上。假设你运行了一个银行,你一半用户的账户在一个服务器,另一半用户的账户在另一个服务器,这样的话可以同时满足负载分担和存储空间的要求。对于其他的场景也有类似的分片,比如说对网站上文章的投票,或许有上亿篇文章,那么可以在一个服务器上对一半的文章进行投票,在另一个服务器对另一半进行投票。
如果执行事务时,涉及到的数据存放在不同的服务器上面,那么这个事务就上升为「分布式事务」了
先后原子性(Before-or-After Atomicity)
我们用一个「转账」案例来描述 先后原子性 的定义
定义「转账」的过程如下:
# TRANSFER(A, B, 10): A 向 B 转 10 元
procedure TRANSFER (reference debit_account, reference credit_account, amount)
debit_account ← debit_account - amount
credit_account ← credit_account + amount
假设 debit_account 和 credit_account 被分片,即存放在不同的服务器上
此时,有两个客户端分别执行(A 初始值为 300,B 初始值为 100):
TRANSFER (A, B, $10)
和
TRANSFER (B, C, $25)
那么,最终结果可能有以下几种:

上图展示了可能发生的几种时间序列,容易发现,case1 和 case2 是合法的,剩下的几个 case 都是不合法的
我们的目标是确保前两个时间序列之一实际发生。实现这一目标的一种方法是使步骤 1-1 和 1-2 具有原子性,步骤 2-1 和 2-2 同样具有原子性。在原始程序中
也就是说:当执行 TRANSFER 操作时,我们希望它是一个 事务,因为我们不希望将 debit_account、credit_account 的中间值暴露给其它任何人看到
先后原子性 是一种更为普遍的约束,即 同时 操作 相同 数据的多个动作 不应相互干扰
Concurrent actions have the before-or-after property if their effect from the point of view of their invokers is the same as if the actions occurred either completely before or completely after one another.
由于我们对先后原子性的定义是每个先后动作的行为就像它在其他先后动作之前或之后完全运行一样,因此先后原子性直接导致了这种正确性概念。
换句话说,先后原子性的效果是 将动作串行化,因此先后原子性保证了协调的正确性。
另一种表达这一思想的方式是说,当并发动作具有先后属性时,它们是可串行化的:存在某种串行顺序,如果遵循该顺序,将导致相同的最终状态。 因此在图 9.2 中,case1 和 case2 的顺序可以从串行顺序得到,但 case3 到 case6 的动作不能。
并发控制
数据库的事务处理系统会使用锁,在事务使用任何数据之前,它需要获得数据的锁。
如果一些其他的事务已经在使用这里的数据,锁会被它们持有,当前事务必须等待这些事务结束,之后当前事务才能获取到锁。
下面讨论一种很常见的锁:两阶段锁(Two-Phase Locking)
两阶段锁分为两个阶段:
- 获取锁
- 事务结束前一直持有锁
当一个事务开始后,在访问任何数据前,都要获取该数据对应的锁(可能是行锁,也可能是粒度更大的锁)
在事务执行中,必须持有锁,直到事务提交或终止
例如对于之前提到的转账案例:
// thread-1
Begin()
// 阶段一
GetLock(A)
Read(A)
GetLock(B)
Read(B)
Write(B)
Write(A)
Commit()
// 阶段二
Unlock(A)
Unlock(B)
// thread-1
Begin()
GetLock(B)
Read(B)
GetLock(C)
Read(C)
Write(B)
Write(C)
Commit()
Unlock(C)
Unlock(B)
两阶段锁的本质实际上就是「迫使」事务 串行 执行,以满足「先后原子性」
为什么要提交或终止事务以后,才释放锁?
假设读取或写入一条数据 A 以后,接下来不会读取或写入 A,为什么不能立即释放 A 的锁?
这样并发能力不是更强吗?
如果在提交或终止事务前,释放锁,这种方式类似 MySQL 的 Read Uncommitted 事务隔离级别,会读取到其它事务没有提交的数据,不满足「先后原子性」
两阶段锁很容易死锁,怎么解决?
例如:
// thread-1
Begin()
GetLock(A)
Read(A)
GetLock(B)
Read(B)
Commit()
Unlock(A, B)
// thread-2
Begin()
GetLock(B)
Read(B)
GetLock(A)
Read(A)
Commit()
Unlock(A, B)
如果 thread1 持有锁 A,thread 2 持有锁 B:
- 当 thread1 想要获取锁 B 时,发现已经被占用,等待
- 当 thread2 想要获取锁 A 时,发现已经被占用,等待
陷入死锁,怎么解决?
一般来说,数据库都会「识别」到死锁的情况,通常的解决方案是:让其中一个事务回滚(后面重试即可),这样另一个事务就能获取到锁,打破局面
原子提交
单个机器上的事务提交很简单,但是扩展到多个机器,也就是分布式事务的提交,就比较麻烦了
因为在分布式的环境下,一些机器可能出现故障,或者网络出现问题等等
如何保证即使出现错误,也能保证我们的 事务提交操作也是原子的,是分布式事务的一大挑战
常用的解决方案是:两阶段提交(2PC)
角色
在 2PC 中,有两种角色:
- 参与者(worker)
- 协调者(coordinator)
参与者是实际的事务执行者,负责执行协调者发来的事务请求
阶段
两阶段提交,分为:
- 事务准备阶段
- 事务提交阶段
执行过程
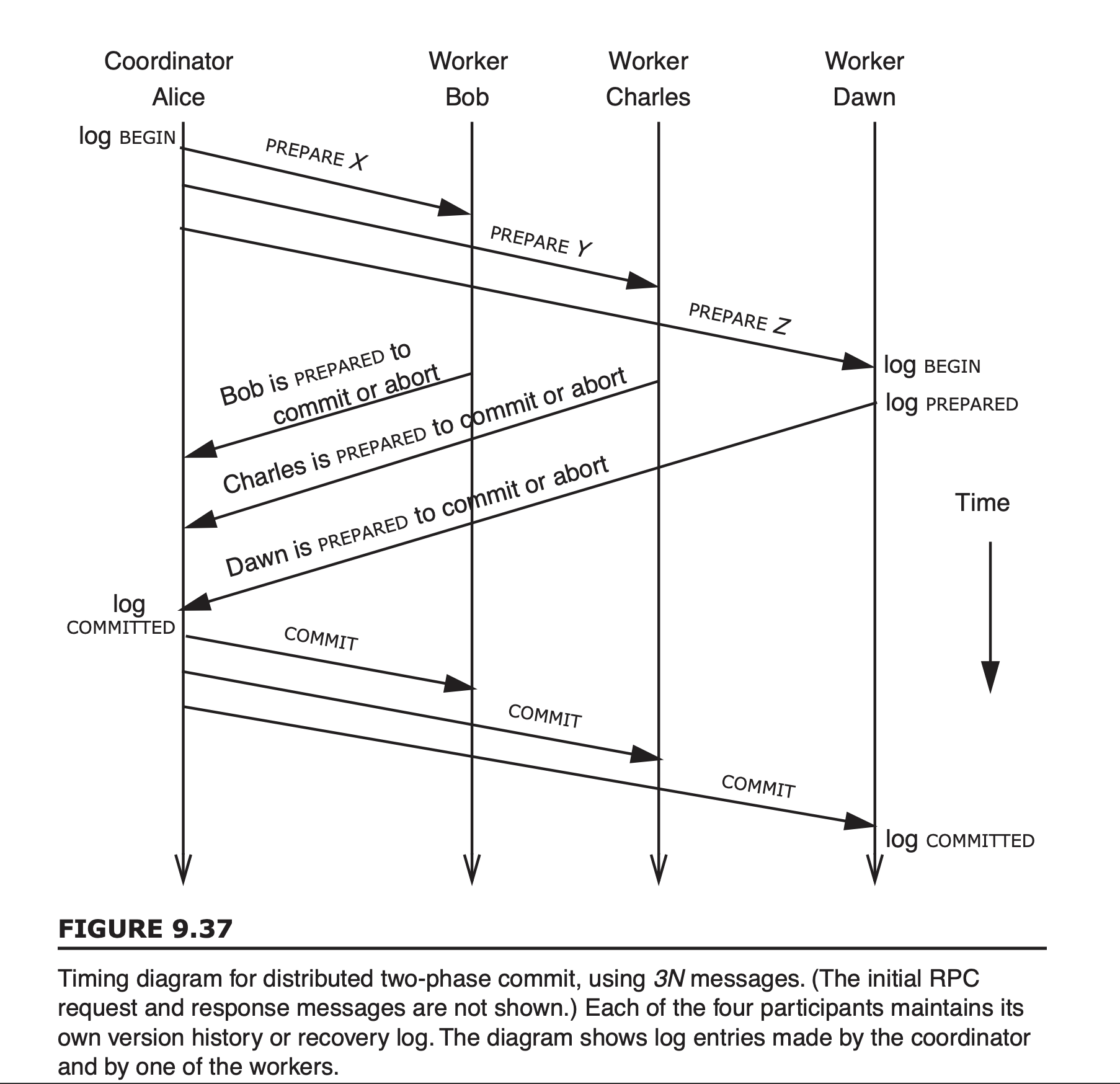
假设多事务由协调者 Alice 请求 Worker Bob、Charles 和 Dawn 分别执行组件事务 X、Y 和 Z。
首先,客户端开启一个新的事务,对 X、Y、Z 执行读取或者写入操作
这会要求协调者 Alice 向 Bob 发送:
From:Alice
To: Bob
Re: my transaction 271
Please do X as part of my transaction
类似的消息也发送给 Charles 和 Dawn,也提及事务 271,并请求他们分别执行 Y 和 Z。
像普通的 RPC 一样,如果 Alice 在合理的时间内没有收到一个或多个 Worker 的响应,她会向未响应的 Worker 重新发送消息,尽可能多次地 重新发送 以引起响应。
Worker 在收到这样的请求时,会 检查是否有重复请求,然后,它进行请求动作的预提交部分,向 Alice 报告这一部分已经顺利完成:
From:Bob
To: Alice
Re: your transaction 271
My part X is ready to commit.
假设客户端要执行的事务就这些,此时客户端 想要提交事务,于是客户端会告诉协调者 Alice,请帮我提交事务 271
Alice 收到客户端的请求后,开始事务提交过程,也就是 2PC 的第一阶段
协调者会给所有参与者发送一条 Prepare 消息:
Two-phase-commit message #1:
From:Alice
To: Bob
Re: my transaction 271
PREPARE to commit X.
参与者收到 Prepare 消息后,如果自己能够提交事务,那么会返回一个 YES 消息给协调者:
Two-phase-commit message #2:
From:Bob
To:Alice
Re: your transaction 271
I am PREPARED to commit my part. Have you decided to commit yet? Regards.
当协调者收到了所有参与者的响应后,进入 2PC 的第二阶段
协调者会给所有参与者发送一条 Commit 消息,要求各参与者提交自己部分的事务:
Two-phase-commit message #3
From:Alice
To:Bob
Re: my transaction 271
My transaction committed. Thanks for your help.
参与者收到 Commit 消息后,会提交自己部分的事务,并 释放所有锁
为了遵循「两阶段锁」原则,参与者在开启子事务时,操作任何数据前都要获取锁
直到协调者发来一条 Commit 或者 Abort 消息,然后提交或者终止子事务后,才会释放所有锁
大部分 2PC 的实现要求参与者在 Commit 或 About 一个事务后,给协调者发送一条 ACK,进而让协调者 安全地删除部分数据(这部分数据是啥后面会讲)
故障恢复
来看看几个故障的场景:
Worker 崩溃
情况 1: Worker 在发送 YES 消息前崩溃
这种情况,Coordinator 会尝试 重发 Prepare 消息给 Worker,直到 Worker 响应,才能进入 2PC 的第二阶段
当 Worker 重启以后,收到了 Prepare 消息,但是自己却没有办法发送 YES,因为重启后,内存的数据被清除了
此时 Worker 被授予 单方面 Abort 事务的权限,可以直接返回一个 No 给 Coordinator
当然,一个 Worker 的重启可能会花费较长的时间,为了避免无限等待,Coordinator 也可以单方面 Abort 事务
情况 2: Worker 在发送 YES 消息后崩溃
这种情况,Coordinator 可以收到全部的 YES 消息,并进入 2PC 的第二阶段
Coordinator 给所有 Worker 发送 Commit 消息,但有一个 Worker 由于宕机正在重启,无法及时响应
Coordinator 必须 重发 Commit 消息给 Worker,直到 Worker 响应
当 Worker 重启以后,收到了 Commit 消息,此时 Worker 还能单方面 Abort 事务吗?
显然不能,因为其它 Worker 已经提交了子事务,宕机的 Worker 也必须提交自己的子事务
因此,Worker 必须 在发送 YES 消息前,将「事务的状态记录」持久化 到磁盘
情况 3: Worker 在发送 ACK 后崩溃
Worker 有可能在处理完 Commit 之后就崩溃了。但是这样的话,子事务已经提交。这样的话,故障重启就不需要做任何事情,因为事务已经完成了。
因为没有收到 ACK,事务协调者会再次发送 Commit 消息。当 Worker 重启之后,收到了 Commit 消息时,它可能已经将 Log 中的修改写入到自己的持久化存储中、释放了锁、并删除了有关事务的 Log。
所以我们需要关心,如果 Worker 收到了同一个 Commit 消息两次,该怎么办?
这里 Worker 可以记住事务的信息,但是这 会消耗内存,所以实际上 Worker 会完全忘记已经在磁盘上持久化存储的事务的信息。对于一个它不知道事务的 Commit 消息,Worker 会 无条件 ACK 这条消息
总结下来:
- Worker 必须 在发送 YES 消息前,将「事务的状态记录」持久化 到磁盘
- 一个 Worker 的重启可能会花费较长的时间,为了避免无限等待,Coordinator 也可以单方面 Abort 事务
- 为了及时释放内存和磁盘空间,当 Worker 提交了子事务后,需要删除磁盘上持久化存储的事务的信息
- 对于一个它不知道事务的 Commit 消息,Worker 会 无条件 ACK 这条消息
Coordinator 崩溃
情况 1: Coordinator 在发送 Prepare 时崩溃
这个情况又可以细分为:
- 发送 Prepare 前
- 发送了若干个 Prepare
- 所有 Prepare 均发送完毕
无论哪种情况,客户端在超时没有收到 Coordinator 响应,会尝试重发「事务提交」请求
当 Coordinator 重启后,收到了客户端的「事务提交」请求后,再发送 Prepare 就行
但这要求 Worker 具有辨别重复请求的能力
情况 2: Coordinator 在发送 Commit 后崩溃
这种情况会导致某个 Worker 一直收不到 Coordinator 的 Commit 消息
如果 Worker 收到了 Prepare 消息,并回复了 Yes,在等待了 10 秒钟或者 10 分钟之后还没有收到 Commit 消息,它能单方面的决定 Abort 事务吗?
不能
因为其它 Worker 有可能已经提交了自己的子事务,所以,Worker 在这里 必须无限等待,直到收到 Coordinator 的 Commit 消息
这种场景也被叫做 「Block」,是 2PC 最大的弊端,决定了 2PC 本身的可用性
这里的 Block 行为是两阶段提交里非常重要的一个特性,并且它不是一个好的属性。因为它意味着,在特定的故障中,你会很容易的陷入到一个需要等待很长时间的场景中,在等待过程中,你会一直持有锁,并阻塞其他的事务。所以,人们总是尝试在两阶段提交中,将这个区间尽可能快的完成,这样可能造成 Block 的时间窗口也会尽可能的小。所以人们尽量会确保协议中这部分尽可能轻量化,甚至对于一些变种的协议,对于一些特定的场景都不用等待。
也就是说,要想打破这个 block 的局面,只能等待 Coordinator 重启后重发 Commit 消息
因此,Coordinator 在开启 2PC 前,必须 持久化 事务相关元数据,发送 Commit 前,需要在磁盘中标记 “Commit 未完成” 状态(具体怎么实现我也不清楚,但应该有一个类似的步骤)
那什么时候,Coordinator 可以安全删除这部分持久化的元数据呢?
当 Coordiantor 收到所有 Worker 的 ACK 后,说明所有子事务均已提交,此时可以删除这部分元数据
为什么要 2PC?
为什么要两阶段提交?只使用一个阶段不行吗?
更具体的说:Coordinator 收到客户端的 Commit 请求后,不需要 Prepare 阶段,而是直接要求 Worker「提交」子事务不可以吗?
先来看看网上主流的说法:
2PC 保证了一致性和原子性:
一致性:2PC 的第一阶段(准备阶段)确保所有参与者都同意提交事务之前,协调者不会进行实际的提交操作。这确保了如果任何参与者不能提交事务(由于检查失败、资源不足等原因),整个事务将被回滚,从而保证了全局一致性。
原子性:通过两个阶段,2PC 能够确保事务的提交要么在所有参与者上成功执行,要么在所有参与者上回滚,没有中间状态。单独使用一个阶段无法实现这种全局原子性。
我个人认为,使用 2PC 而不是 1PC 的原因,主要是:降低 Block 的概率
Worker 可能由于各种原因(例如内存、磁盘空间不足,网络问题)导致 无法提交事务
假设采用 一阶段提交,即 Coordinator 直接给所有 Worker 发送 Commit 请求
- 如果某个 Worker 超时未响应,为了保证一致性和原子性,Coordinator 需要 阻塞 等待,直到该 Worker 响应(因为其它 Worker 已经提交子事务)
- 如果某个 Worker 由于某种原因返回 Abort,Coordinator 需要要求其它 Worker 回滚子事务,但是此前 Worker 已经提交(应用)了子事务,想要 回滚很困难
因此,需要使用两阶段提交,可以在 Prepare 阶段:
- 排除某个 Worker 的网络问题(如果一直没有响应,Coordinator 有权回滚整个事务)
- 排除某个 Worker 要求 Abort 的情况
这样,阻塞的可能性大大降低,性能自然得到提升
总结
使用 两阶段锁 + 两阶段提交,可以满足事务的「先后原子性」
两阶段提交实现了原子提交。它在大量的将数据分割在多个服务器上的分片数据库或者存储系统中都有使用。
两阶段提交可以支持读写多条记录,一些更特殊的存储系统不允许你在多条记录上支持事务。对于这些不支持事务中包含多条数据的系统,你就不需要两阶段提交。但是如果你需要在事务中支持多条数据,并且你将数据分片在多台服务器之上,那么你必须支持两阶段提交。
为什么 2PC 这么慢?
- 大量的网络请求:对于 N 个 Worker,一次事务提交,最理想的情况,也需要 4N 个 RPC call
- 磁盘写入:2PC 要求 Coordinator 和 Worker 需要 持久化 相关数据以实现错误恢复
- 存在 Block 的情况:如果发生 Block,只能等待 Coordinator 恢复
与 Raft 对比
下面的分析来自 Robert 教授的总结部分
两阶段提交的架构中,本质上是有一个 Leader(事务协调者),将消息发送给 Follower(事务参与者),Leader 只能在收到了足够多 Follower 的回复之后才能继续执行。这与 Raft 非常像,但是,这里协议的属性与 Raft 又非常的不一样。这两个协议解决的是完全不同的问题。
因为 Raft 的每个 Server 做的都是相同的事,存放的也是几乎相同的数据;而 2PC,每个 Worker 存放的数据是完全不同的
所以,Raft 通过复制可以不用每一个参与者都在线,而两阶段提交每个参与者都做了不同的工作,并且每个参与者的工作都必须完成,所以两阶段提交对于可用性没有任何帮助。Raft 完全就是可用性,而两阶段提交完全不是高可用的,系统中的任何一个部分出错了,系统都有可能等待直到这个部分修复。
怎么结合 Raft 实现 2PC 的高可用
一图胜千言:
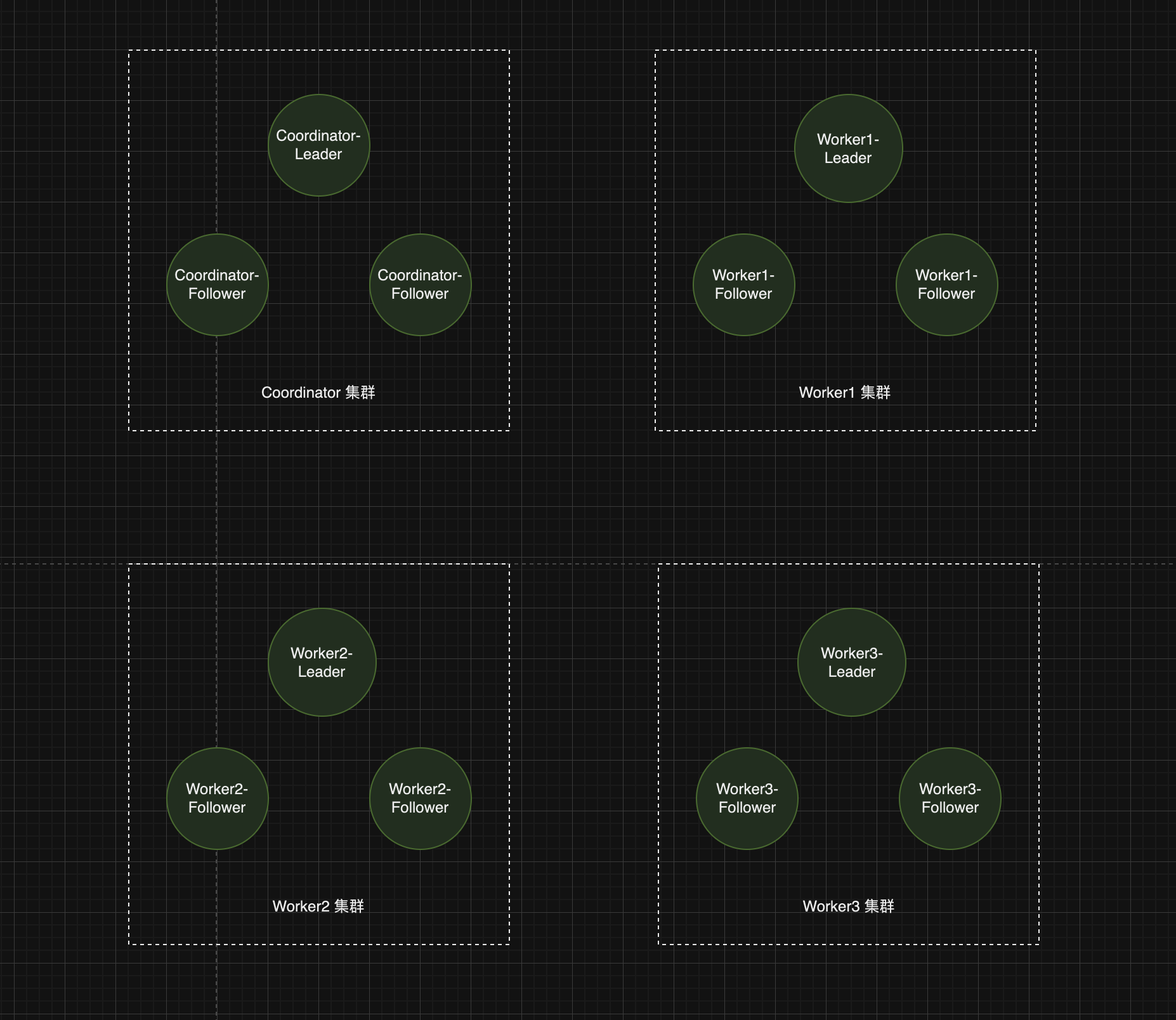
每个集群通过 Raft 实现冗余复制,保证可用性