MapReduce
MapReduce 是一种分布式编程模型,用于大规模数据处理。它由 Google 开发,用于处理 Google 搜索引擎索引的网页数据。
MapReduce 利用了 分布式计算 的优势,将大规模数据分成小的块(分治思想),然后在每个块上应用一个 Map 函数和一个 Reduce 函数,最后将结果合并。
架构
直接引用 MapReduce 论文 的一张图片:
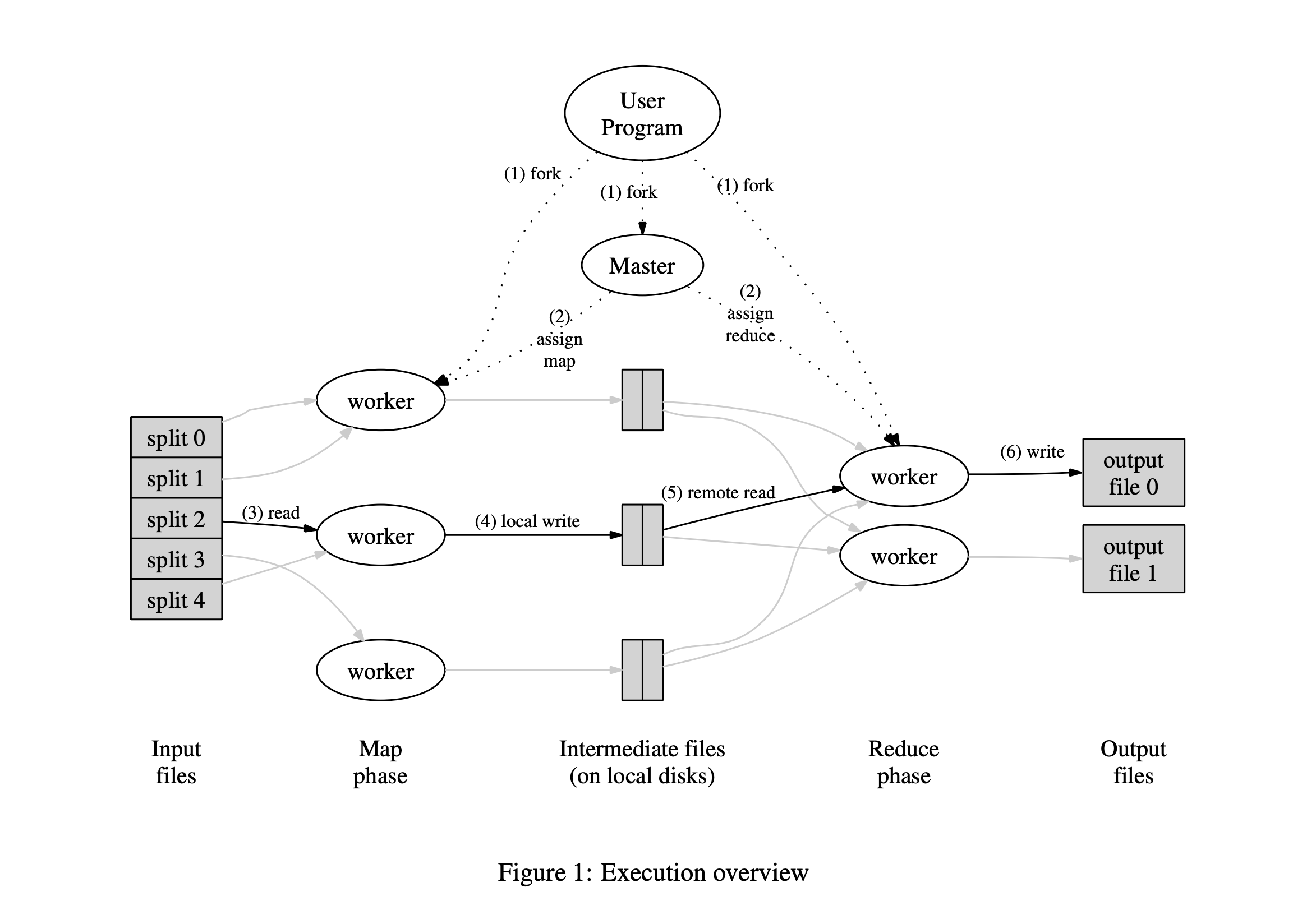
整体有两个角色:
- Coordinator(图中的 Master)
- Worker
Coordinator 负责分布式协调,将任务分发给不同的 Worker
而 Worker 负责执行 Coordinator 分发的任务即可
值得一提的是,这里的 MapReduce 实现是基于本地文件系统的
然而在更常见的分布式情况下,使用的一般是分布式文件系统(例如 GFS)
下文的 Lab 实现是基于 Local File System 的
Map
Map 阶段主要是根据用户提供的 map 方法,将大规模的数据分割成一个 K-V List(分治),定义如下:
type KeyValue struct {
Key string
Value string
}
func Map(filename string, contents string) []mr.KeyValue {
}
每一个分割得到的 K-V List 会被一个 worker 写到 若干个 中间文件中(intermediate file)
分布式体现在哪里?
一般来说,会传给 Coordinator 多个 file,这些 file 就可以被分发到不同的 worker 上去执行
Reduce
当 Map 阶段结束后,可以开始执行 Reduce 阶段
Reduce 更像是一个「聚合」操作,将刚才生成的 K-V List 聚合起来
具体来说,每一个 worker 会负责处理,某一个 Map 之后,得到的若干个 intermediate file
worker 会根据 Key 来整合这些 intermediate file:一个 Key,对应多个 Value
Reduce 操作的定义如下:
func Reduce(key string, values []string) string {
}
这样,我们就可以得到巨大文件中,某一个 Key Reduce 之后的结果了
分布式体现在哪里?
Map 阶段,每一个 file 都会按照 key 的哈希值,分成若干个 reduce 部分
例如,假设 Map 处理了 5 个 file,那么在 Reduce 阶段,就可以有 5 个 worker 并行处理这 5 * nReduce 个 intermediate file
瓶颈
如果是基于分布式文件系统实现的 MapReduce,瓶颈主要在:
- 节点性能
- 网络性能
下面用 Lecture1 学生提的一个问题来解释:

这里的箭头代表什么意思?
下文引用自 Robert 教授,翻译自 肖宏辉
通常情况下,如果我们在一个例如 GFS 的文件系统中存储大的文件,你的数据分散在大量服务器之上,你需要通过网络与这些服务器通信以获取你的数据。在这种情况下,这个箭头表示:
- MapReduce 的 worker 需要通过网络,与存储了输入文件的 GFS 服务器通信
- 通过网络将数据读取到 MapReduce 的 worker 节点,进而将数据传递给 Map 函数。
这是最常见的情况。并且这是 MapReduce 论文中介绍的工作方式。但是如果你这么做了,这里就有 很多网络通信。 如果数据总共是 10TB,那么相应的就需要在数据中心网络上移动 10TB 的数据。而数据中心网络通常是 GB 级别的带宽,所以移动 10TB 的数据需要大量的时间。在论文发表的 2004 年,MapReduce 系统最大的限制瓶颈是网络吞吐。如果你读到了论文的评估部分,你会发现,当时运行在一个有数千台机器的网络上,每台计算机都接入到一个机架,机架上有以太网交换机,机架之间通过 root 交换机连接(最上面那个交换机)。
如果随机的选择 MapReduce 的 worker 服务器和 GFS 服务器,那么至少有一半的机会,它们之间的通信需要经过 root 交换机,而这个 root 交换机的吞吐量总是固定的。如果做一个除法,root 交换机的总吞吐除以 2000,那么每台机器只能分到 50Mb/S 的网络容量。这个网络容量相比磁盘或者 CPU 的速度来说,要小得多。所以,50Mb/S 是一个巨大的限制。
在 MapReduce 论文中,讨论了大量的 避免使用网络的技巧。其中一个是 将 GFS 和 MapReduce 混合运行在一组服务器上。所以如果有 1000 台服务器,那么 GFS 和 MapReduce 都运行在那 1000 台服务器之上。当 MapReduce 的 Master 节点拆分 Map 任务并分包到不同的 worker 服务器上时,Master 节点会找出输入文件具体存在哪台 GFS 服务器上,并把对应于那个输入文件的 Map Task 调度到同一台服务器上。
所以,默认情况下,这里的箭头是 指读取本地文件,而不会涉及网络。虽然由于故障,负载或者其他原因,不能总是让 Map 函数都读取本地文件,但是几乎所有的 Map 函数都会运行在存储了数据的相同机器上,并因此节省了大量的时间,否则通过网络来读取输入数据将会耗费大量的时间。
我之前提过,Map 函数会将输出存储到机器的本地磁盘,所以存储 Map 函数的 输出不需要网络通信,至少不需要实时的网络通信。但是,我们可以确定的是,为了 收集 所有特定 key 的输出,并将它们传递给某个机器的 Reduce 函数,还是需要网络通信。
实现
Worker
Worker 只需要执行 Coordinator 分配的任务:
//
// main/mrworker.go calls this function.
//
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
// Your worker implementation here.
lastTaskID := -1
for {
reply := CallFetchTaskHandler(lastTaskID)
if reply == nil { // call failed
return // just return
}
var err error
switch reply.Type {
case MapTask:
err = doMapTask(reply.TaskID, reply.FileName, reply.NReduce, mapf)
case ReduceTask:
err = doReduceTask(reply.TaskID, reply.NMap, reply.NReduce, reducef)
case WaitTask:
time.Sleep(time.Second)
case ExitTask:
return
default:
log.Println("Unexpected task type")
}
if err != nil {
// this round of work failed
log.Println(err.Error())
lastTaskID = -1
} else {
lastTaskID = reply.TaskID
}
}
// uncomment to send the Example RPC to the coordinator.
// CallExample()
}
然后分别实现 Map 和 Reduce 的逻辑即可
Coordinator
Coordinator 是 MapReduce 的控制中心,负责协调所有 Worker 的运行。
我们可以使用两个队列来分别维护处于等待状态的任务和处于运行状态的任务:
waittingTaskQueue []Task
runningTaskQueue []Task
finnishTask map[int]struct{} // 记录已经完成的 task_id
Task 的定义如下:
type Task struct {
ID int
StartTime time.Time
Type TaskType
FileName string
}
任务分配
处理该 Worker 上一次任务的执行结果
Worker 会发来自己上一次执行的 task_id,这样,Coordinator 就知道哪些任务已经完成,哪些任务没有完成
尝试从 runningTaskQueue 中获取任务
- 如果 runningTaskQueue 队头的任务执行完毕(使用 finnishTask 判断),移除,重新执行第一步
- 如果 runningTaskQueue 队头的任务执行超时(可以根据 StartTime 判断),我们认为之前的 Worker 挂了,将这个任务分配给当前 Worker
- 否则,没有超时,获取任务失败
尝试从 waitingTaskQueue 中获取任务
如果从 runningTaskQueue 获取任务失败,就尝试从 waitingTaskQueue 中获取任务
注意:如果获取成功,需要将任务移到 runningTaskQueue,并设置开始时间
判断获取状态
如果成功获取到了任务,那么直接返回,否则:
- 如果 runningTaskQueue 为空,说明当前阶段任务全部执行完毕,进入下一阶段
- 否则,说明还没有全部执行完毕,让当前 worker 等待
无锁编程
Coordinator 对 Worker 提供的 FetchTask 接口肯定是并发执行的,如果我们直接将上面的逻辑写在 FetchTask 中,会不可避免的加锁保护 Coordinator 的临界资源
怎么实现无锁编程?
「串行化」
如果只有一个 goroutine 处理上面的事情,不就可以避免加锁了吗
因此,在 Coordinator 刚启动时,启动一个后台 goroutine(即 scheduler),负责整体的调度
然后,让 rpc 接口与 scheduler 使用 channel 进行 goroutine 的通信
部分定义
type FetchMsg struct {
args *FetchTaskArgs
reply *FetchTaskReply
done chan struct{}
}
const MAX_TASK_ID = 1 << 31
type Coordinator struct {
// Your definitions here.
waittingTaskQueue []Task
runningTaskQueue []Task
finnishTask map[int]struct{}
nReduce int
nMap int
taskID int // next TaskID
fetchMsgChan chan FetchMsg
doneChan chan struct{}
done atomic.Bool
status StatusType
}
//
// create a Coordinator.
// main/mrcoordinator.go calls this function.
// nReduce is the number of reduce tasks to use.
//
func MakeCoordinator(files []string, nReduce int) *Coordinator {
c := Coordinator{}
// Your code here.
// ...
go c.schedule()
// ...
}
// Your code here -- RPC handlers for the worker to call.
func (c *Coordinator) FetchTaskHandler(args *FetchTaskArgs, reply *FetchTaskReply) error {
msg := FetchMsg{
args: args,
reply: reply,
done: make(chan struct{}), // no buffer
}
// notify c.schedule
c.fetchMsgChan <- msg
// block, until c.schedule done
<- msg.done
return nil
}
//
// Schduler
// Responsible for worker scheduling
//
func (c *Coordinator) schedule() {
for {
select {
case msg := <- c.fetchMsgChan:
c.doSchedule(msg)
msg.done <- struct{}{}
case <- c.doneChan:
// exit
c.done.Store(true)
return
}
}
}
正确性验证
执行 100 次 test-mr-many,全部通过:
总结
MapReduce 是一种分布式编程模型,用于大规模数据处理。它由 Google 开发,利用分布式计算的优势,将大规模数据分成小的块,然后在每个块上应用 Map 函数和一个 Reduce 函数,最后将结果合并。
MapReduce 的核心组件包括 Worker 和 Coordinator,Worker 负责执行 Map 和 Reduce 函数,Coordinator 负责协调所有 Worker 的运行。