Server State
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (3A, 3B, 3C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
State RaftState // state of current Raft Node
currentTerm int // latest term server has seen (initialized to 0 on first boot, increases monotonically)
votedFor int // candidateId that received vote in current term (or null if none)
logs []*Entry // log entries; each entry contains command for state machine, and term when entry was received by leader (first index is 1)
electionTimer *time.Timer // election timer
heartbeatTimer *time.Timer // heartbeat timer
}
Server 需要维护:
- 当前的身份
- 当前的 term
- 当前 term 投票给谁
- 日志列表
- 选举计时器与心跳计时器
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me
// Your initialization code here (3A, 3B, 3C).
rf.State = StateFollower
rf.currentTerm = 0
rf.votedFor = -1
rf.logs = make([]*Entry, 0)
rf.electionTimer = time.NewTimer(getElectionTimeout())
rf.heartbeatTimer = time.NewTimer(getHeartbeatTimeout())
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
// start ticker goroutine to start elections
go rf.ticker()
return rf
}
State transition relationship
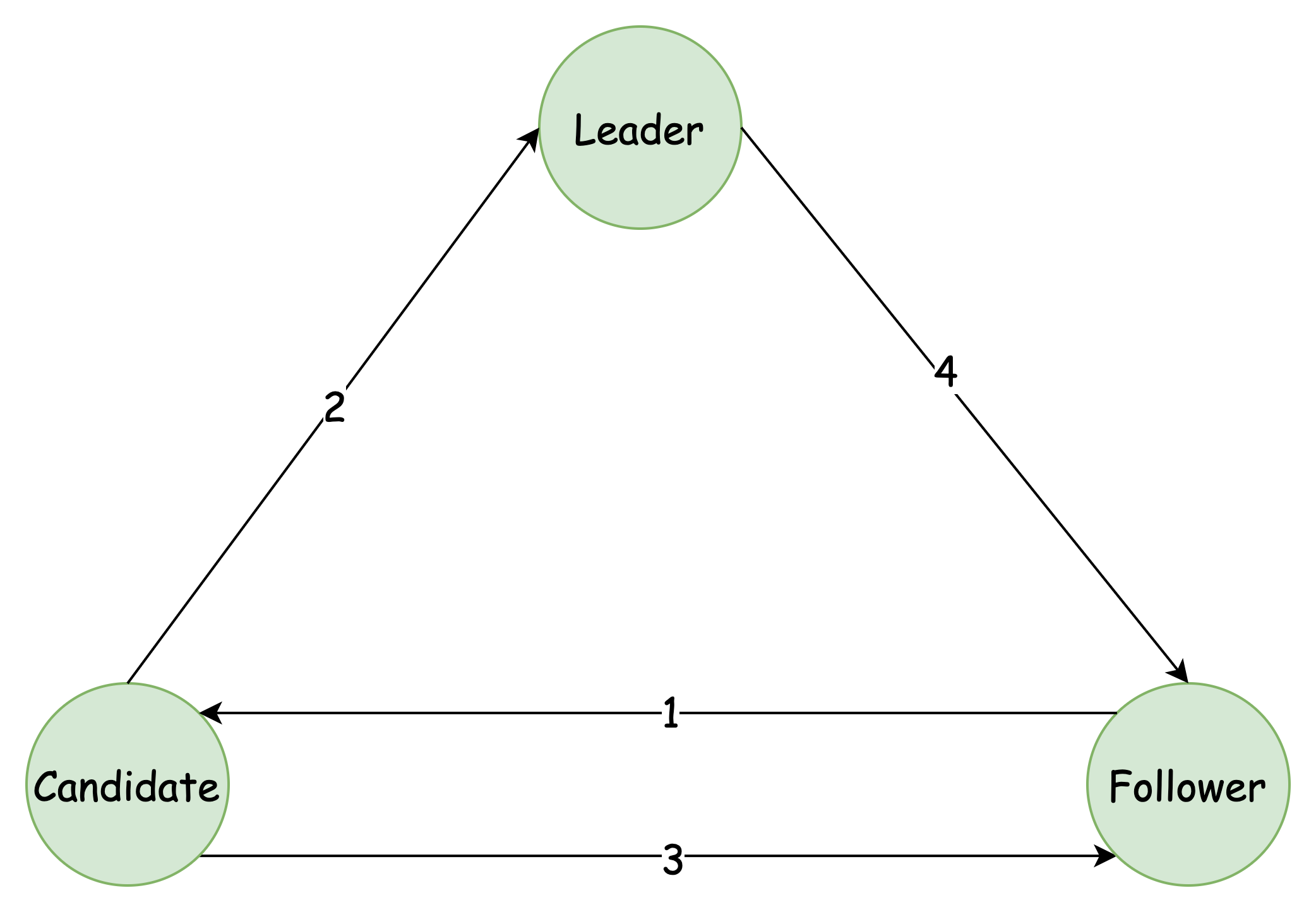
- 选举计时器超时(Leader 超时没有发送心跳)
- 选举成功(获得半数以上投票)
- 选举失败(投票数不够,或者有了新的 Leader)
- 有了比自己 term 更大的 Leader(通常发生在旧 Leader 网络分区问题恢复时)
RPC
AppendEntries RPC
type RequestAppendEntriesArgs struct {
Term int // leader's term
LeaderId int // leader's id
}
type RequestAppendEntriesReply struct {
}
// RequestAppendEntries RPC handler.
// expired leader, follower and candidate use this
func (rf *Raft) RequestAppendEntries(args *RequestAppendEntriesArgs, reply *RequestAppendEntriesReply) {
}
在 3A 部分,AE Request 主要用于心跳请求,Follower 会在一段时间没有收到心跳请求后,开始选举过程
Server(Follower、Candidate、或者是 过期的 Leader),收到 AE 后,应该立即:
- 更新自己的状态为 Follower
- 重置选举计时器
RequestVote RPC
type RequestVoteArgs struct {
Term int // candidate’s term
CandidateId int // candidate requesting vote
LastLogIndex int // index of candidate’s last log entry (§5.4)
LastLogTerm int // term of candidate’s last log entry (§5.4)
}
type RequestVoteReply struct {
Term int // currentTerm, for candidate to update itself
VoteGranted bool // true means candidate received vote
}
// example RequestVote RPC handler.
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
}
参数需要包括:
- Candidate 的 term,用于 Receiver 判断此次投票请求是否过期
- Candidate 的 ID,用于 Receiver 记录投票对象,以及判断是否可以投票
- LastLogIndex、LastLogTerm:用于 Receiver 判断 candidate 的 Log 是否比自己新(如果 candidate 的日志比自己旧,不能让其成为 leader,否则会丢失较多数据,因为 Follower 会根据 Leader 来截断自己的 Log)
返回值包括:
- Receiver 的 Term:如果 Receiver 的 Term 比自己(Candidate)大,说明已经有了新的 Leader,本次选举失败,更新自己的 Term
- VoteGranted:Receiver 是否给自己投票
一个 Server 在收到 RV 请求后,需要判断自己是否可以给这个 Candidate 投票,主要考虑:
- Candidate 的 Term 是否比自己大(或者相等)
- Candidate 的 Log 是否比自己新
receiver 怎么判断 log 是否 up-to-date?
- curTerm < lastLogTerm(candidate’s term)
- curTerm == lastLogTerm && len(rf.log) < lastLogIndex(candidate’s last log idx)
无论哪个 RPC,只要 args 中的 Term 比自己大,就要修改自己的身份为 Follower
Background Task
主要有两个后台任务:
- 选举任务
- 发送心跳任务
func (rf *Raft) ticker() {
for rf.killed() == false {
// Your code here (3A)
// Check if a leader election should be started.
select {
case <-rf.electionTimer.C:
rf.mu.Lock()
if rf.State != StateLeader {
rf.currentTerm += 1
rf.startElection()
}
rf.electionTimer.Reset(getElectionTimeout())
rf.mu.Unlock()
case <-rf.heartbeatTimer.C:
rf.mu.Lock()
if rf.State == StateLeader {
rf.startHeartbeat()
}
rf.heartbeatTimer.Reset(getHeartbeatTimeout())
rf.mu.Unlock()
}
}
}
startElection
- 修改自己的状态为 Candidate
- 给自己投一票
- 异步 向所有 peer(除了自己)发送 RV 请求
发送 RV 请求的 goroutine 执行逻辑如下:
- 发送 RV 请求
- 判断是否发送成功:如果失败返回,否则:
- 判断返回的 Term 与自己的 Term 的关系:
- 如果比自己大,说明有新的 Leader,更新自己的 Term,修改状态为 Follower,放弃本次选举,否则:
- 如果 Receiver 给自己投票了,那么:
- 票数 ++
- 如果票数超过一半的 peer,说明选举成功
- 选举成功,立即向所有 peer 发送心跳,告诉 peer 自己是新的 leader
startHeartbeat
向所有 peer(除了自己)异步发送 AE 请求,忽略发送失败的情况即可
正确性验证
执行下面的 bash 脚本
#!/bin/bash
# 定义执行次数
runs=100
# 循环执行命令
for (( i=1; i<=$runs; i++ )); do
echo "Running test $i"
go test -timeout 30s -run "^TestInitialElection3A$" -count=1 6.5840/raft
if [ $? -ne 0 ]; then
echo "Error: Test failed. Exiting..."
exit 1
fi
go test -timeout 30s -run "^TestReElection3A$" -count=1 6.5840/raft
if [ $? -ne 0 ]; then
echo "Error: Test failed. Exiting..."
exit 1
fi
go test -timeout 30s -run "^TestManyElections3A$" -count=1 6.5840/raft
if [ $? -ne 0 ]; then
echo "Error: Test failed. Exiting..."
exit 1
fi
done
echo "All tests passed successfully."
结果如下:
踩的坑
大量使用原子操作(锁粒度太小)
例如使用原子操作读取和写入 Term、VoteFor
实际上就是将锁的粒度控制得 非常小,看起来可以提升并发,但是有可能会写入不符合预期的结果
可以将锁的粒度控制得比较大,实现时:
- 将整个 RPC 内的操作锁住,使 Handler 趋近于线性执行
- 将 startElection 和 startHeartbeat 锁住
即:全局使用同一个 mutex
同步发送 AE 和 RV
如果网络不稳定,单个发送操作比较耗时,可能导致选举时间太长,导致超时
同样的,如果同步发送 AE,某一个心跳发送的时间太长,会影响到下一次心跳
因此,发送过程应该是异步的
选举超时时间与心跳频率
实验要求 1s 内,最多发送 10 次心跳(100ms 一次)
这就相当于要求我们的选举超时时间 必须大于 100ms
考虑到 RTT,可以略大一些:
func getElectionTimeout() time.Duration {
ms := 200 + (rand.Int63() % 200)
return time.Duration(ms) * time.Millisecond
}
func getHeartbeatTimeout() time.Duration {
return time.Millisecond * 100
}
收到 RV 请求,没有重置自己的选举超时计时器
这可能会带来不必要的选举