Lab3C 整体实现非常简单,实现 Raft 的持久化功能,帮助宕机重启的 Raft 实例快速恢复
持久化哪些内容
- Logs
- CurrentTerm
- VoteFor
怎么持久化
Raft 的测试程序无法真正让一个 Raft 实例宕机,而是一种模拟的方式
实现持久化时,只要 Logs、CurrentTerm、VoteFor 任意一个发生了变化,就做一次持久化
实现时需要注意持久化操作在 rf.mu 解锁之前进行,保证原子性
这种持久化方式合适吗?
很容易发现前面提到的持久化方式是不合理的,在实际生产环境显然不可用
因为无论哪个数据变化,都要做一次 整个数据 的持久化
为什么能通过测试?是因为 Lab 的持久化操作是在 内存 进行的,并不是磁盘
内存的 IO 很高,即使采用这种方式也不会产生太大的瓶颈
但实际应用,应该是将数据持久化到 磁盘 才对,而磁盘的速率很低,采取这种持久化方式,就会产生性能问题
那应该怎么持久化?
我们可以 参考 Redis 的持久化方式:
将持久化分为两个文件:
- metadata
- logs.aof
其中,metadata 用于持久化 CurrentTerm 和 VoteFor,因为这两个数据很小,每次更改持久化,也没什么问题
而 logs.aof 用于持久化 Logs,每次客户端追加 Logs 时,我们只需要向 Logs 追加一条数据即可,这个是顺序 IO,性能较高
并且,可以引入 批量写入 的机制,具体来说,每次追加 Logs 时,不需要立即写磁盘,而是写到内存(rf.Logs),然后后台启动一个 goroutine,做定时持久化操作,持久化的频率根据数据的可靠性来确定:
- 如果要求比较高的可靠性,那频率应该更高,甚至,放弃批量写入机制,而是直接写入磁盘(write+fsync)
此外,写入磁盘,通常使用的是 write 系统调用,不会立即将文件写入磁盘,而是在 OS 层面做了一个 buffer,还是有数据丢失的风险
我们还可以再启动一个 goroutine,定期调用 fsync,控制文件真正写入磁盘的频率
截断
上面提到的都是追加日志的情况,但是 Leader 可能会要求 Follower 截断本地日志
如果全局使用一个 aof 文件,可能不太好实现,我们可以拆分成多个 aof 文件,当一个 aof 文件大小达到设置的上限时,新建一个新的 aof 文件
如果要截断本地日志,除了截断内存的 Log 以外,只需要删除部分 aof 文件即可
快照
此外,Redis 有一个 AOF 重写机制
实际上 Lab3D 部分要求实现的快照机制,就和 AOF 重写非常类似,这里不再过多描述
总结
Lab 3C 实现的持久化非常简单,生产上不可用,如果要实现一个生产可用的 Raft,可以参考 Redis AOF 的实现
正确性验证
使用如下脚本进行测试:
#!/bin/bash
# 定义执行次数
runs=100
# 循环执行命令
for (( i=1; i<=$runs; i++ )); do
echo "Running test $i"
go test -run 3C -v -count=1 > log.log # 将日志输出重定向到 log.log
if [ $? -ne 0 ]; then
echo "Error: Test failed. Exiting..."
exit 1
fi
done
echo "All tests passed successfully."
结果如下:
踩的坑
Lab3C 无法通过测试,基本上都是 3A、3B 的代码有 bug 导致的,而不是持久化本身
在真正编写 Lab3C 的代码之后,我发现自己之前的代码有很多小 bug,导致 3C 的测试一直过不去,可以看看在我提交 3C 部分代码前,修改了多少 bug。。。
Sky_Lee@SkyLeeMacBook-Pro 6.5840 % git log --oneline
27a3090 fix: Fixed a bug that caused nextIndex and matchIndex to be updated incorrectly due to out-of-order RPC responses.
8dae858 fix: Fixed an issue where network instability caused a single AE request to take too long
5543b60 fix: Fixed an election bug: candidate's LastLogTerm parameter was wrong
ba8ad08 fix: leader can only submit logs for its own term(Figure8)
1a1b879 fix: rf.matchIndex should start from -1, not 0
73d7edc fix: any goroutine with a long-running loop should call killed() to check whether it should stop.
97aa9fb fix: Fixed an election bug: candidate's LastLogIndex parameter was wrong
c9b2239 refactor: change struct field to be exported
问题 1: 忘记调用 killed
测试文件无法「真正」杀掉一个 Raft 实例,而是通过调用 Kill 方法
在实现时,对于任何一个无限循环的 goroutine,都应该在循环入口检查当前实例是否被杀掉,如果被杀掉,退出循环
这个问题在 Lab3C 的 Figure8 测试中会被暴露出来:Figure8 会通过杀掉一个 Raft 实例模拟宕机的情况
发现这个问题,主要是在看 Log 时,发现了一些「不正常」的日志,遂想起自己是不是忘记调用 Killed 来检查当前 Raft 的状态
问题 2: rf.matchIndex 应该从 -1 开始,而不是 0
因为我在实现 Raft 时,Index 是从 0 开始的,因此,如果 rf.matchIndex 从 0 开始,意味着 Index=0 这个日志已经被提交,这是错误的
当然,也可以在初始化 Logs 切片时,Append 一个 「哨兵」 日志,这样实际的第一条 Log 的 Index 就是 1 开始,与 Raft 论文表述一致,方便测试,也不用编写 if 语句判断 Logs 切片为空的情况,代码更加简洁
问题 3: Leader 只能提交自己 Term 内的日志
在 Lab3B 中,提到了数据不一致的问题
当时的解决方案是通过限制 Follower 更新 CommitIndex 的条件
但是在 Figure8 的测试中,仅仅限制「更新 CommitIndex 的条件」已经无法满足了,而是需要限制 Leader 更新 CommitIndex 的条件:
Leader 不能提交之前任期的日志,只能通过提交自己任期的日志,从而间接提交之前任期的日志。
具体来说,Leader 在更新 CommitIndex 时,目标 CommitIndex 对应的 Log.Term 必须 与当期 Term 一致,如果不一致,那么就不能使用这个 CommitIndex;如果一致,那么更新 CommitIndex,相当于「间接」提交了之前的所有 Log
为什么要这样限制?主要还是为了避免新的 Leader 提交的 Log(index=i) 与旧 Leader 提交的 Log(index=j) 的 Command 不一致的问题
来看看 Figure8 描述的问题:
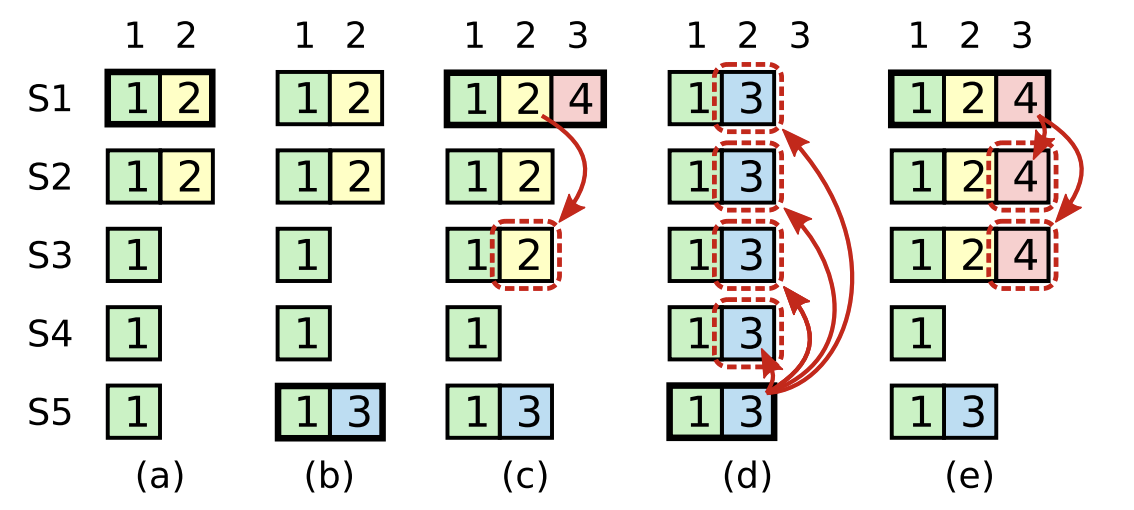
- a:初始状态
- b:S1 在将
Term=2的日志复制到大半节点前,宕机了,S5 选举成为新的 Leader,并接受了客户端的请求 - c:S5 宕机,S1 重新选举为新的 Leader,并成功将
Term=2的日志复制到大半节点
接下来,由于 Term=2 的日志已经复制到大半节点,如果我们 不遵循前文提到的限制,那么这里 S1 就可以提交 Term=2 的日志
假设,S1 提交了 Term=2 的日志,考虑后续两种情况:
情况 d
这里指 S1 又宕机,并且没有来得及将 Index=3, Term=4 的日志复制到大半节点,于是 S5 可能选举成新的 Leader(S2、S3、S4 都可以投票给 S5),S5 将自己的 Index=2, Term=3 的日志成功复制到 S2、S3、S4
由于 Index=2, Term=3 日志已经复制到大半节点,S5 自然可以放心提交该日志,然而,Index=2 这个位置的日志已经被 S1 提交过了,这里发生了 数据不一致 的问题
情况 e
这里指 S1 在宕机前,成功将 Index=3, Term=4 的日志复制到大半节点,这样即使 S1 宕机,S5 也拿不到大多数节点的投票,自然不会出现情况 d 的数据不一致问题
为了避免情况 d 的发生,Leader 不能提交之前任期的日志,只能通过提交自己任期的日志,从而间接提交之前任期的日志。
加上限制条件后,在 c 阶段,S1 就无法提交 Index=2 的日志
no-op 日志
加上限制条件后,在情况 4,S5 的 Term >= 5,无法提交 Index=2, Term=3
如果没有客户端继续发起新的请求,那么这个日志永远无法得到提交,给上层 Service 的感觉就是 Raft「卡住了」
因此,新的 Leader 当选后,可以发送一条 cmd 为空的日志给全体 Follower,这个日志就叫做 no-op 日志
只要 no-op 日志 被复制到绝大多数节点,新的 Leader 就可以更新 CommitIndex 到 no-op 日志的位置,间接提交 no-op 日志之前的所有日志,避免客户端请求被阻塞
问题 4: AE 请求,同步还是异步发送?
在 3B 部分,startReplica 函数中,发送 AE 请求是同步发送的,因为涉及到 offset 的处理,多个 goroutine 操作 offset,边界情况太多
当时还能通过测试,只不过平均耗时较长,大概 50s,勉强符合「提示」中的小于 1min
但是在 3C 的 Figure8:Unreliable 中,这个问题就暴露出来了:经常出现 “One(xxx) failed to reach agreement.” 错误
通过阅读 Figure8:Unreliable 的源码,发现该部分模拟的是网络不稳定的情况,让集群认为某个节点宕机了(实际上并没有,这也是常说的分布式的网络分区问题),这里网络不稳定包括两个场景:
- 延迟响应单个 RPC 请求
- 断开某个 Server 与集群的连接
第一种情况,如果同步发送 AE RPC,假设该 RPC 等待了 5s 才响应,或者干脆不响应,那么 RPC 库会等「很久」才会将执行结果返回给我们的 startReplica 函数,这样,整个 Replica 的频率就异常的低,之前设置的频率根本就没起作用
解决方式有两种:
- 缩小 RPC 超时时间
- 异步发送 RPC
实际采用的是第二种,伪代码如下:
for !rf.Killed() {
time.Sleep(getReplicaTimeout())
// init...
// send AE(async)
go func() {
ok := sendAERequest(args, reply)
// other op...
}()
}
采取异步发送,可以控制整个 Replica 的频率,而不会受到单次 RPC 的影响
但是需要采取「新的方式」来应对 Follower 拒绝 AE 请求的情况
采取 Raft 论文提到的方法,下面的描述来自 Lab3C 的提示部分:
你可能需要一种优化,允许 nextIndex 一次后退多个条目。查看 Raft 论文扩展版,从第 7 页底部到第 8 页顶部(灰线标记处)。论文对细节描述模糊;你需要填补这些空白。一个可能的方案是让拒绝消息包括:
XTerm: 冲突条目的任期(如果有的话)
XIndex: 第一个具有该任期的条目的索引(如果有的话)
XLen: 日志长度
然后领导者的逻辑可以是这样的:
情况 1:跟随者的日志太短:nextIndex = XLen
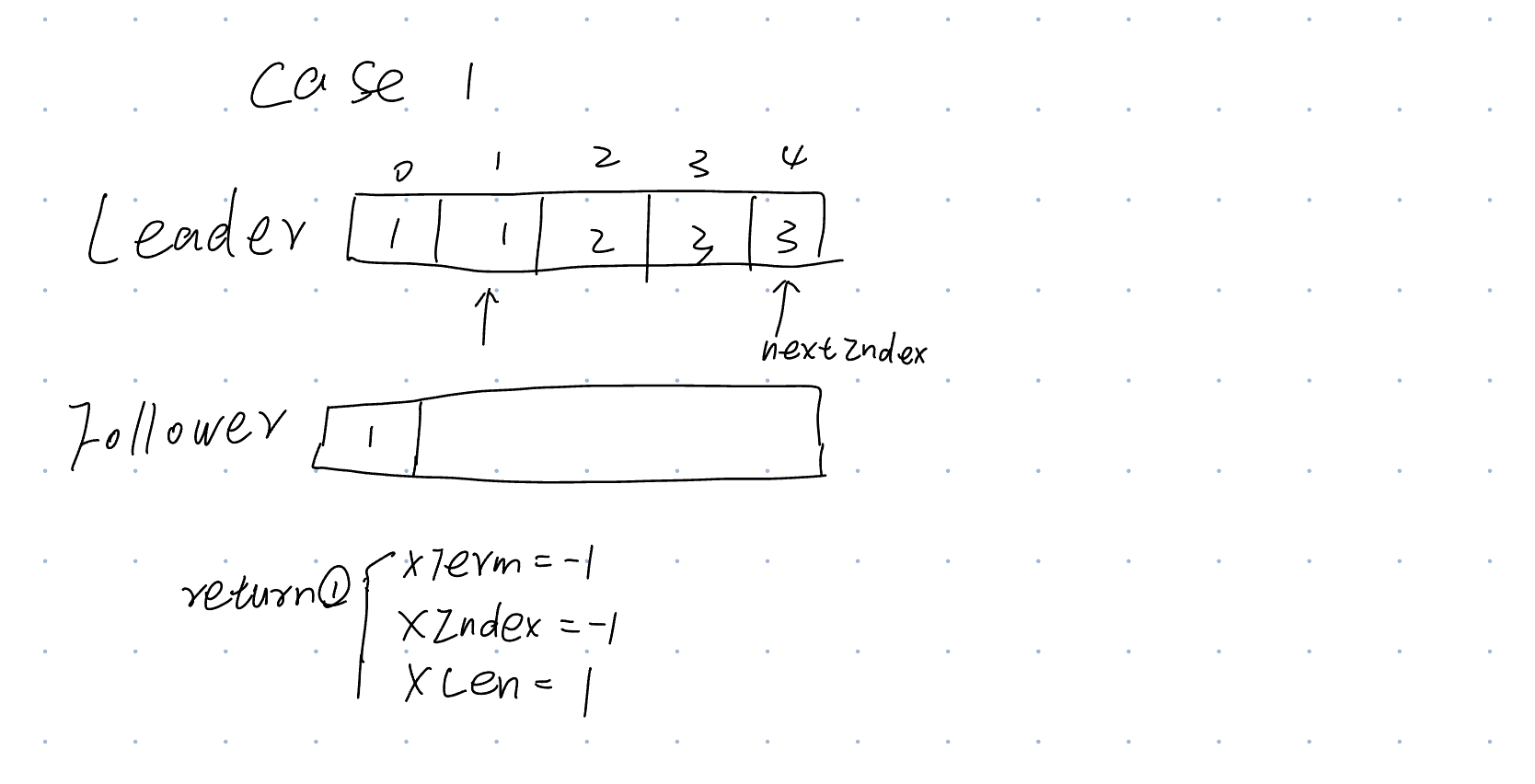
情况 2:领导者没有 XTerm:nextIndex = XIndex
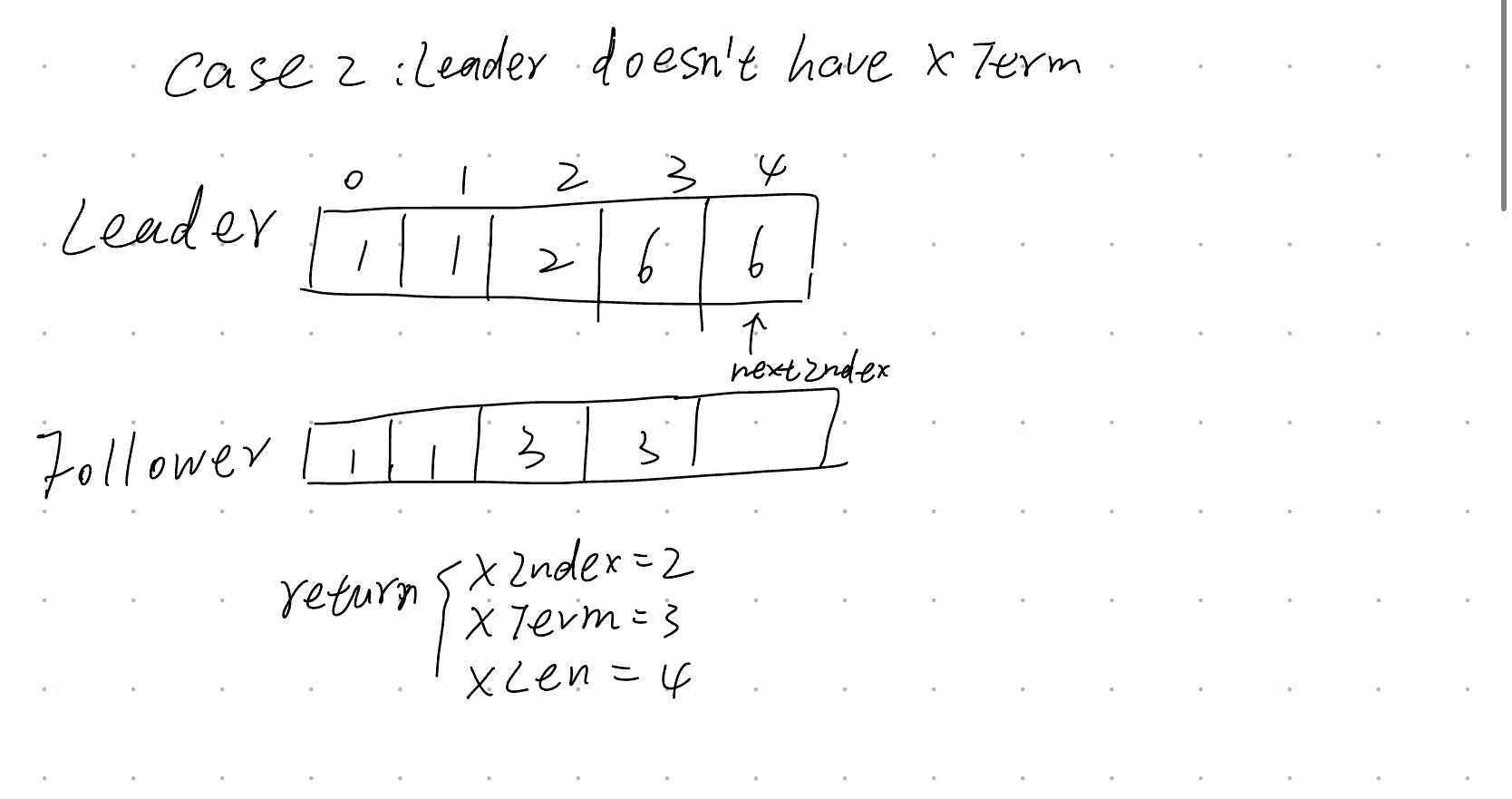
情况 3:领导者有 XTerm:nextIndex = 领导者最后一个 XTerm 条目的索引
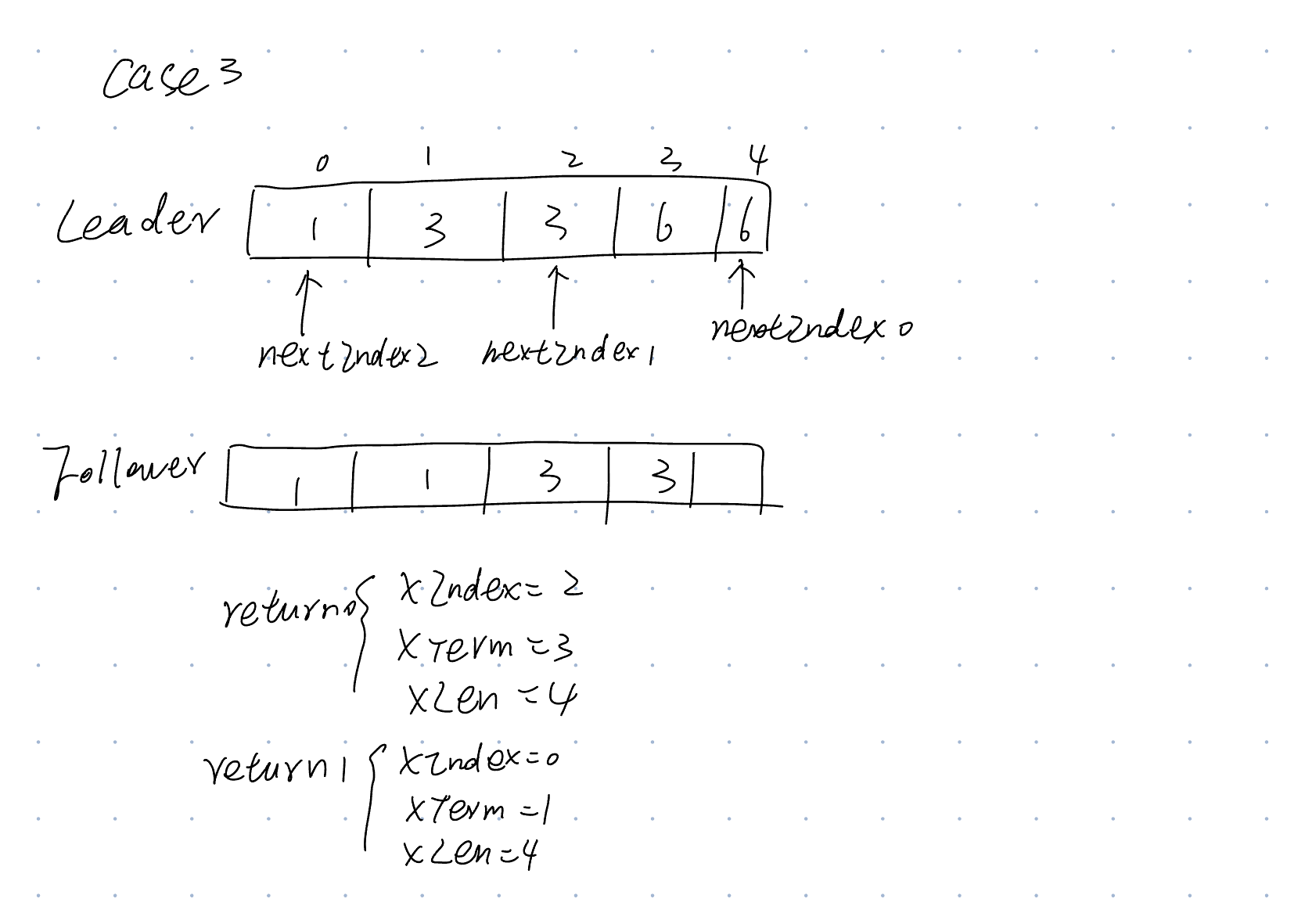
具体实现时:
- 每个日志条目需要维护 XIndex
- Leader 使用 二分查找 的方式确定自己是否具有 XTerm 的条目
问题 5: 乱序 RPC
解决前面的 4 个问题后,出现了数据不一致问题
前面提到了单个 RPC 的响应可能延迟,如果在此期间,Leader 接受了几个新的客户端请求,就会出现问题
这是之前的部分代码:
// Send AE request asynchronously
go func() {
DPrintf("{%v}%v: sending AE to follower{%v}\n", rf.CurrentTerm, rf.me, serverID)
reply := RequestAppendEntriesReply{}
if ok := rf.sendRequestAppendEntries(serverID, &args, &reply); !ok {
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
// 危险!rf.CurrentTerm 有没有改变?
if reply.Term > rf.CurrentTerm {
rf.State = StateFollower
return
}
// 危险!rf.logs 有没有改变?
// rf.nextIndex[serverID]、rf.matchIndex[serverID] 有没有被其它 goroutine 更新?
if reply.Success {
rf.nextIndex[serverID] = len(rf.Logs)
rf.matchIndex[serverID] = len(rf.Logs) - 1
} else {
DPrintf("{%v}%v: follower{%v} reject append Logs\n", rf.CurrentTerm, rf.me, serverID)
rf.matchIndex[serverID] = 0
// ...
}
}()
因此,当 RPC 响应时,需要判断 rf.CurrentTerm、rf.nextIndex[serverID]、rf.matchIndex[serverID] 是否改变,如果已经改变了,本次响应就当作过期响应,不做处理