Server State
type Raft struct {
snapshot []byte
}
Snapshot
依赖 Raft 的 Service 层会定期调用 Snapshot 方法,以要求 Raft 实例创建快照:
func (rf *Raft) Snapshot(index int, snapshot []byte) {
}
具体实现:
- 检查 index 是否合法,index 必须大于等于 rf.logs[0].Index
- 截断 rf.logs
- 持久化当前状态和快照
截断 rf.logs 时,截断的是 [0:index-rf.logs[0].Index-1],也就是说,rf.logs[index] 并没有截断,而是继续保留在内存中,这样做的好处是:
- 哨兵日志
- 相当于持久化了 lastIncludedIndex 和 lastIncludedTerm
InstallSnapshot RPC
在 Lab3B 中,提到了 startReplica 函数
Leader 向 Follower 同步数据时,需要先确定 nextIndex
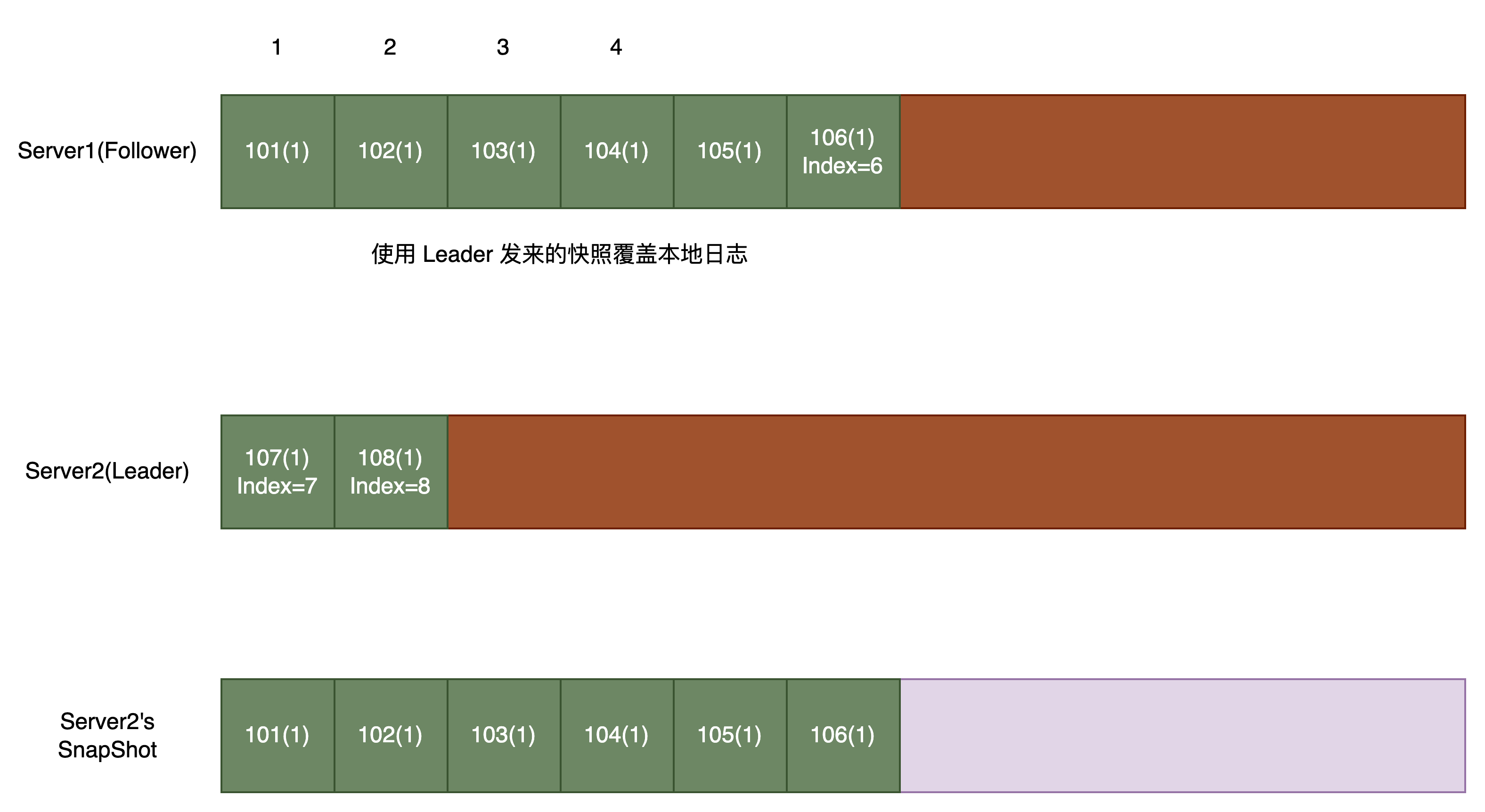
如果 Leader 发送 rf.Logs 的所有内容,Follower 还是拒绝了 Leader 的 AE 请求,说明 Follower 同步进度太慢,以至于 Leader 的 rf.Logs 中,没有 Follower 所需的日志(这部分日志由于快照的创建而被截断)

上面的图片展示了这种情况:
- Follower 的同步速度很慢,即使 Leader 的 nextIndex=7,也无法被 Follower 接受
此时,Leader 需要发送自己的「快照」给 Follower,让 Follower 使用快照来覆盖自己本地的 Logs:
当然还有一种特殊的情况,即 Follower 收到了描述自己日志前缀的快照:
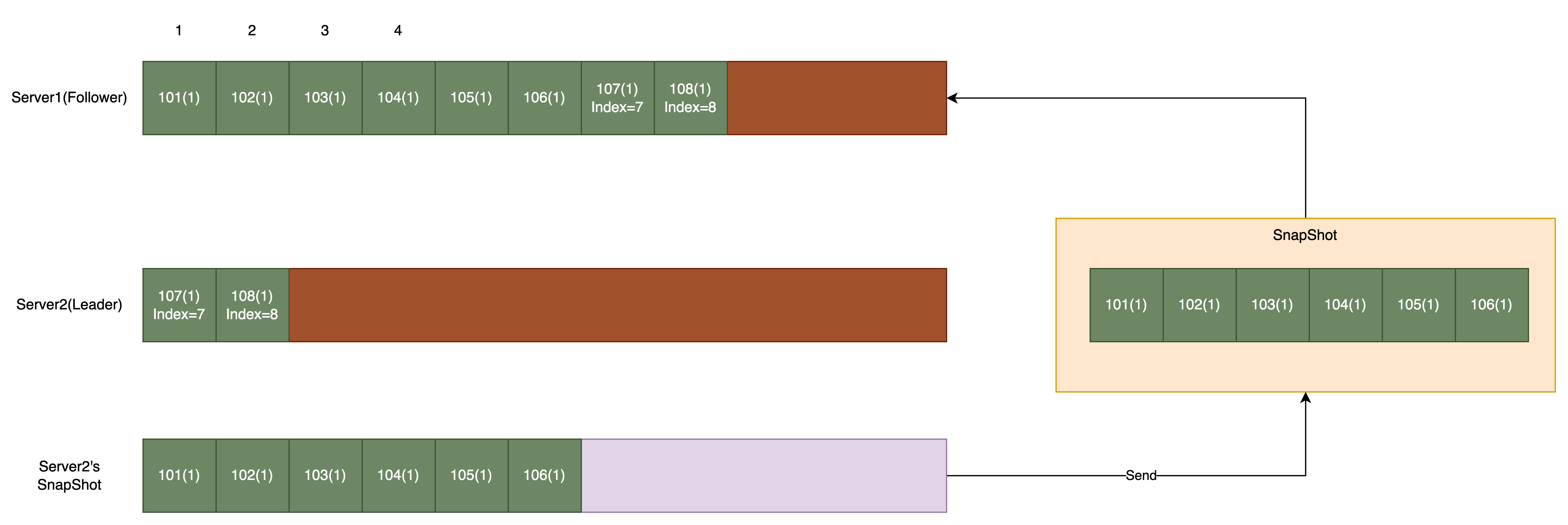
这通常是由于重传和错误产生的,对于这种「错误」的情况,Follower 需要:
- 截断 被快照覆盖部分的日志
- 使用该 Snapshot 作为自己的 Snapshot
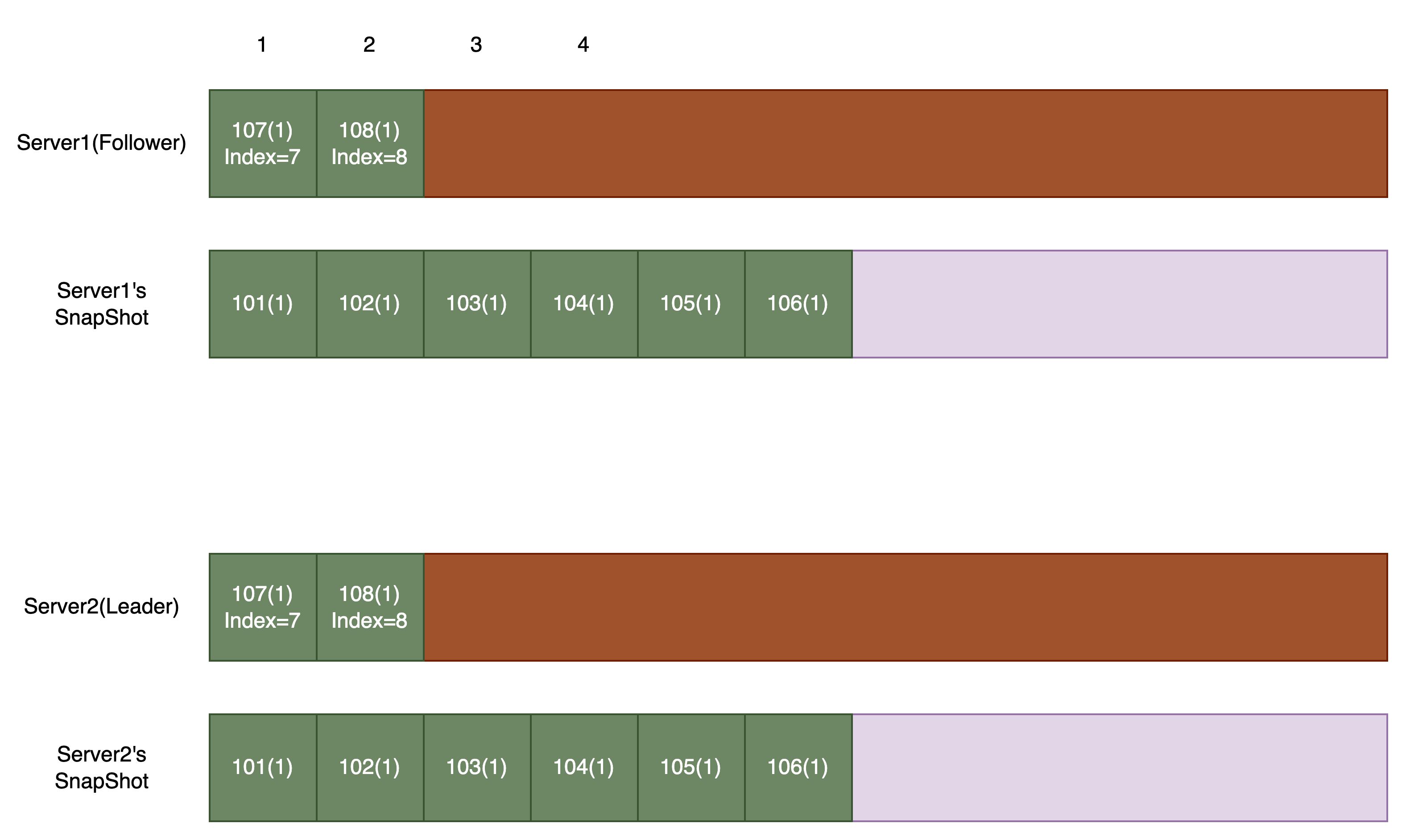
基本分析完毕,来看看具体实现
具体实现
参数与返回值如下:
type InstallSnapshotArgs struct {
Term int // Leader's term
LastIncludedIndex int // The index corresponding to the last log entry contained in the snapshot
LastIncludedTerm int // The term corresponding to the last log entry contained in the snapshot
Data []byte // Snapshot data
}
type InstallSnapshotReply struct {
Term int // Follower's term, for leader to update itself
}
Follower 收到 Leader 发来的 InstallSnapshot RPC,应该:
- 如果 Leader 的 Term 比自己小,忽略
- 如果收到的快照的 LastIncludedIndex 比本地快照的 LastIncludedIndex 小,说明这个快照是一个过期的快照,忽略
- 保存快照文件(使用 Leader 发来的快照文件覆盖本地快照文件)
- 讨论两种情况:
- 如果 rf.logs(内存)中存在一个 Entry 与 LastIncludedIndex、LastIncludedTerm 对应(即此次快照描述的是 rf.Logs 的前缀),那么截断 Entry 前的日志
- 否则,丢弃整个 rf.Logs
- 使用快照内容重置状态机(这里指将快照内容 同步 发送到 applyCh)
- 更新 applyIndex 和 commitIndex
2024.5.29 更新:
注意:这里一定是同步发送,而不是异步,原因 下文 会讲
正确性验证
这里提供一个测试代码的脚本文件,可以指定测试的用例、并发量、总测试次数,并将日志输出重定向到相应文件中:
#!/bin/bash
# 默认执行次数
runs=5
# 默认测试用例名称
test_name="3A"
# 默认最大并发数
concurrency=10
# 解析选项
while [[ $# -gt 0 ]]; do
key="$1"
case $key in
-n)
runs="$2"
shift # 过去参数值
shift # 过去参数值
;;
-name=*)
test_name="${key#*=}"
shift # 过去参数
;;
-c)
concurrency="$2"
shift # 过去参数值
shift # 过去参数值
;;
*)
echo "Unknown option: $key"
exit 1
;;
esac
done
# 根据测试用例名称创建Logs和Status目录
log_dir="logs-$test_name"
status_dir="status-$test_name"
rm -rf $log_dir/ $status_dir/
# 创建日志和状态目录
mkdir -p $log_dir
mkdir -p $status_dir
# 控制并发数
sem() {
local max_concurrent=$1
shift
local cmd="$@"
(
eval "$cmd"
) &
while [[ $(jobs -r -p | wc -l) -ge $max_concurrent ]]; do
sleep 0.1
done
}
# 定义终止处理函数
terminate() {
echo "Termination signal received. Stopping all tests..."
pkill -P $$ # 终止所有子进程
wait # 等待所有子进程结束
summarize_results
exit 1
}
# 定义总结测试结果的函数
summarize_results() {
success=1
for (( i=1; i<=$runs; i++ )); do
if [ -f "./$status_dir/log${i}.status" ]; then
status=$(cat "./$status_dir/log${i}.status")
if [ "$status" -ne 0 ]; then
echo "Test $i failed. See ./$log_dir/log${i}.log for details."
success=0
fi
else
success=0
fi
done
if [ $success -eq 1 ]; then
echo "All tests passed successfully."
else
echo "Some tests failed."
fi
}
# 捕获 SIGINT 信号并调用终止处理函数
trap terminate SIGINT
# 循环执行命令
for (( i=1; i<=$runs; i++ )); do
echo "Running test $i with test case $test_name"
sem $concurrency "go test -run '$test_name' -v -count=1 > './$log_dir/log${i}.log' 2>&1; echo \$? > './$status_dir/log${i}.status'"
done
# 等待所有后台作业完成
wait
# 总结测试结果
summarize_results
使用上面的 shell,参数为 -c 25 -n 100 -name=3D,可以通过测试:
踩的坑
(Lab3C)向 service 提交 command 时,不应该持锁
当 Raft 实例向应用提交 command 时,不应该持锁,否则有可能因为客户端没有及时取走数据,导致 Raft 整体阻塞(因为目前的实现,整体使用一把大锁)
提交 command,要么不持锁,要么异步提交
但是异步提交存在问题:如何保证提交的顺序性?
要想保证提交的顺序性,即使使用多线程,还是要利用同步机制保证 command 的顺序性
因此,还不如直接用单线程,只不过在 apply 时不要持锁
异步发送 InstallSnapshotRPC
这个原因不再赘述,与 Lab3C 异步发送 AE 的原因是一样的
并发问题
引入了 snapshot 后:
- commitIndex
- applyIndex
- Logs
这三个变量,可能会由于 Leader 发来了一个 InstallSnapshotRPC 而改变,这会影响到:
- startApply
- startReplica
- AE RPC
- Make
这四个函数
对于 startApply 来说,问题主要出现在循环中:
// ...
applyIndex, commitIndex := rf.applyIndex, rf.commitIndex
rf.mu.Unlock()
for index := applyIndex + 1; index <= commitIndex; index++ {
rf.mu.Lock()
log := rf.getEntry(index) // can be a problem?
rf.mu.Unlock()
applyMsg := ApplyMsg {
CommandValid: true,
CommandIndex: index,
Command: log.Command,
}
rf.applyCh <- applyMsg
}
rf.applyIndex = commitIndex // can be a problem?
可能出现问题的代码,已经在注释中给出
原因是:循环执行过程中,Logs 可能发生改变(InstallSnapshotRPC 截断了 Logs),我们要提交的日志条目可能已经被截断了,要特别注意这种情况
解决办法很简单:每次尝试 getEntry 前,检查 commitIndex、applyIndex 有没有改变,如果改变,说明 Leader 发来了 InstallSnapshotRPC
由于我们已经在 InstallSnapshotRPC 中使用快照提交了快照包含的日志,因此,这里不能重复提交(事实上也提交不了。。)
同样的,更新 applyIndex 前,也要判断 applyIndex 有没有发生改变,如果改变了,就不要更新
startReplica、AE RPC 实现时,在获取一个日志条目前,一定要先检查这个日志条目是否还在 Logs 中,避免 panic
对于 Make 函数来说,由于有了 snapshot,当 Raft 实例宕机重启后,读取的 Logs 可能并不是完整的,有一部分包含在快照中,这个时候,一定 要初始化 applyIndex 和 commitIndex 为哨兵日志的 Index
2024.5.29 更新:
重写了 applier 核心逻辑,修复了可能存在的 apply out-of-order 问题,下文有提到
applyIndex 只能严格递增
在 AE RPC 中,有一种边界情况:更新后的 commitIndex 比 applyIndex 小
这种情况不被允许,因为对于同一个 server,我们不能重复提交相同 index 的日志(exactly once)
那为什么会出现 leaderCommitIndex < rf.applyIndex 的情况?
假设 leader1 成功将 index = 3 以及之前的日志同步到 follower
于是,leader1 更新自己的 commitIndex 为 3,并 apply,此时 leader1 的 applyIndex 也更新为 3
然而,在 leader1 给其它 follower 发送心跳前,宕机了,这意味着其它 follower 的 commitIndex 可能小于 3,因为它们并不知道 leader1 的 commitIndex 已经更新
然后,集群选出第二个 leader2
然后,leader1 重新上线,收到了 leader2 的心跳,其中,commitIndex = 2
如果此时更新 commitIndex 为 2,并且如果你的实现:applyIndex 的更新依赖于 commitIndex,那就会出现问题
解决方案:
- 不允许 applyIndex 减小(除了 InstallSnapshot RPC),applyIndex 应该严格递增
极低概率出现 apply out of order
来看一段日志:
# 省略部分内容 #
2024/05/28 09:20:31 {5}0: Load Raft State Successfully, CurrentTerm: 5
VotedFor: -1
Logs: [{4 119 83 <nil>} {4 120 83 3739460424151144431} {4 121 83 3168617896739618178} {4 122 83 9162378228834488708} {4 123 83 6831704875973104458} {5 124 124 549014041314024410} {5 125 125 2306247720335571870} {5 126 126 3489300829279971277}]
# 省略部分内容 #
2024/05/28 09:20:31 {5}0: Received snapshot from leader, lastIncludedIndex: 139, lastIncludedTerm: 5
2024/05/28 09:20:31 {5}0: Received AE from 2
2024/05/28 09:20:31 {5}0: Appended Entries to local log(current len:142)
2024/05/28 09:20:31 {5}0: Received AE from 2
2024/05/28 09:20:31 {5}0: Received unexpected AE from 2: args.PrevLogIndex not int local log
2024/05/28 09:20:31 {5}0: applied command which index is 140(term:5)
2024/05/28 09:20:31 apply error: server 0 apply out of order, expected index 120, got 140
exit status 1
FAIL 6.5840/raft 121.630s
日志第一行表明 server-0 宕机重启完毕了,并且有快照,快照的 lastIncludedIndex 为 119
然后,server-0 收到了来自 leader 的 InstallSnapshotRPC,要求应用一个新的快照,新的快照的 lastIncludedIndex 为 139
server-0 会做以下几件事:
- 使用新的快照替换旧的快照
- 将 applyIndex 由 119 修改为 139
- 将新的快照发给上层 Service
然后,后台的 applier 开始 apply command,第一条 command 的 index 肯定是 140(因为 applyIndex 已经修改为 139)
一切看起来如此合理,为啥测试程序期望的 command index 为 120,而不是 140 呢?
只有一个原因:applier 在 apply command 时,「将新的快照发给上层 Service」这个操作 还没有开始执行
为什么会出现这个情况?因为 InstallSnapshot RPC 中,将新的快照发给上层 Service 这个操作是 异步的
正确的实现应该是:更新 applyIndex 和 将新的快照发给上层 Service 这两个操作应该是一个 原子操作
怎么实现原子操作?最简单的方式就是 同步 发送新的快照到上层 Service:
// RequestInstallSnapshot RPC handler.
func (rf *Raft) RequestInstallSnapshot(args *RequestInstallSnapshotArgs, reply *RequestInstallSnapshotReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
// ...
// apply snapshot synchronously
rf.applyCh <- applyMsg
rf.persist()
}
当然这可能导致客户端响应的延迟,我们也可以这样写:
// RequestInstallSnapshot RPC handler.
func (rf *Raft) RequestInstallSnapshot(args *RequestInstallSnapshotArgs, reply *RequestInstallSnapshotReply) {
rf.mu.Lock()
// defer rf.mu.Unlock() 不要释放锁
// ...
go func() {
rf.applyCh <- applyMsg
rf.mu.Unlock() // 在这里释放
}()
rf.persist()
}
同样的,Make 函数也有问题,修改如下:
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
// ...
// Reset state machine using snapshot
if len(rf.SnapshotData) > 0 {
applyMsg := ApplyMsg {
SnapshotValid: true,
Snapshot: rf.SnapshotData,
SnapshotIndex: rf.Logs[0].Index,
SnapshotTerm: rf.Logs[0].Term,
}
rf.mu.Lock()
go func() {
rf.applyCh <- applyMsg
// To avoid possible apply out-of-order problems,
// lock until the snapshot is successfully applied to applych
rf.mu.Unlock()
}()
}
// ...
return rf
}
写在最后
Lab3D 是整个 Lab3 的最后一个小节了,通过实现这四部分 Lab,顺利掌握了 Raft 共识算法的实现细节,也学到了 debug 的技巧,提升了解决问题的能力
说实话,Lab3 的实现还是有一定难度,即使是完全按照论文描述实现,还是会遇到一些 corner case
只有自己 独立完成 Lab3,才能真正搞清楚 Raft 的细节
遇到困难,不要害怕,相信办法永远比困难多
这句话虽然简单,但是正是这句话激励着我不断思考,调试,最终实现了整个 Lab3