容错方案:复制
设计分布式系统,必须要考虑的一个点就是容错(Fault Tolerance)
常见的容错方案就是 复制,提供多个副本,如果其中一个副本挂了,其它的副本能快速补上,整个过程对用户是无感的,实现容错
复制能处理什么样的故障
复制只能处理:单台计算机的 fail-stop 故障
什么是 fail-stop 故障?
Fail-stop 是一种容错领域的通用术语。它是指,如果某些东西出了故障,比如说计算机,那么它会单纯的停止运行。当任何地方出现故障时,就停止运行,而不是运算出错误结果。例如,某人将你服务器的电源线踢掉了,那就会产生一个 fail-stop 故障。类似的,如果某人拔了你的服务器的网线,即使你的服务器还在运行,那也算是一个 fail-stop 故障。
如果编写的软件本身就有问题(例如计算上的问题),那复制肯定解决不了这类问题
当然,如果有一些不相关的软件运行在你的服务器上,并且它们导致了服务器崩溃,例如 kernel panic 或者服务器重启,虽然这些软件与你服务的副本无关,但是这种问题对于你的服务来说,也算是一种 fail-stop。
副本间遵循原则
副本间应该 互不相关,也就是说,副本之间的错误是相互独立的
例如,我们在同一供应商采购了 1000 台计算机,如果其中一台计算机存在设计问题,那剩余的计算机有很大可能也会有这个问题
在这种情况下,即使有冗余副本,副本本身的可用性就值得怀疑,整个系统的可用性是无法得到保障的
还有一种情况就是:所有副本在同一个机房
假设机房电源或者网络出现问题,那么所有副本都将变得不可用
复制是否值得
复制使用了我们实际需要的 2-3 倍的计算机资源。GFS 对于每个数据块都有 3 份拷贝,所以我们需要购买实际容量 3 倍的磁盘。VMware FT 复制了一份,但这也意味着我们需要两倍的计算机,CPU,内存。这些东西都不便宜,所以自然会有这个问题,这里的额外支出真的值得吗?
这个问题主要是从 经济角度 上考虑的,取决于你的服务能够提供的价值
假设你的系统是为银行服务的,如果系统挂了,那么很有可能失去你的用户的信任,造成很大的经济损失
状态转移与复制状态机
假设有两台服务器,其中一个为 Primary,另一个为 Backup
我们希望 BackUp 与 Primary 保持同步,这样即使 Primary 挂了,Backup 也可以顶上
状态转移
状态转移背后的思想是,Primary 将自己完整状态,比如说内存中的内容,拷贝 并发送给 Backup。Backup 会保存收到的最近一次状态,所以 Backup 会有所有的数据。当 Primary 故障了,Backup 就可以从它所保存的最新状态开始运行。所以,状态转移就是发送 Primary 的状态。
状态转移实现比较简单,但是网络传输成本较高:内存的完整快照是一个很大的数据量
复制状态机
计算机软件可以分为确定部分和不确定部分:
- 确定部分:程序内部的执行逻辑
- 不确定部分:用户的输入
通常情况下,如果一台计算机没有外部影响,它只是一个接一个的执行指令,每条指令执行的是计算机中内存和寄存器上确定的函数,只有当外部事件干预时,才会发生一些预期外的事。
基于这个事实,复制状态机不会在不同的副本之间发送状态,相应的,它只会从 Primary 将这些外部事件,例如外部的输入,发送给 Backup。
复制状态机传输的数据量远远小于状态转移,但是实现较为复杂,需要考虑到底要复制哪些状态
VMWare-FT 的工作原理
VMWare-FT 的实现需要两个 物理机:
- Primary
- Backup

Primary、Backup 以及 Client 会使用网络连接:
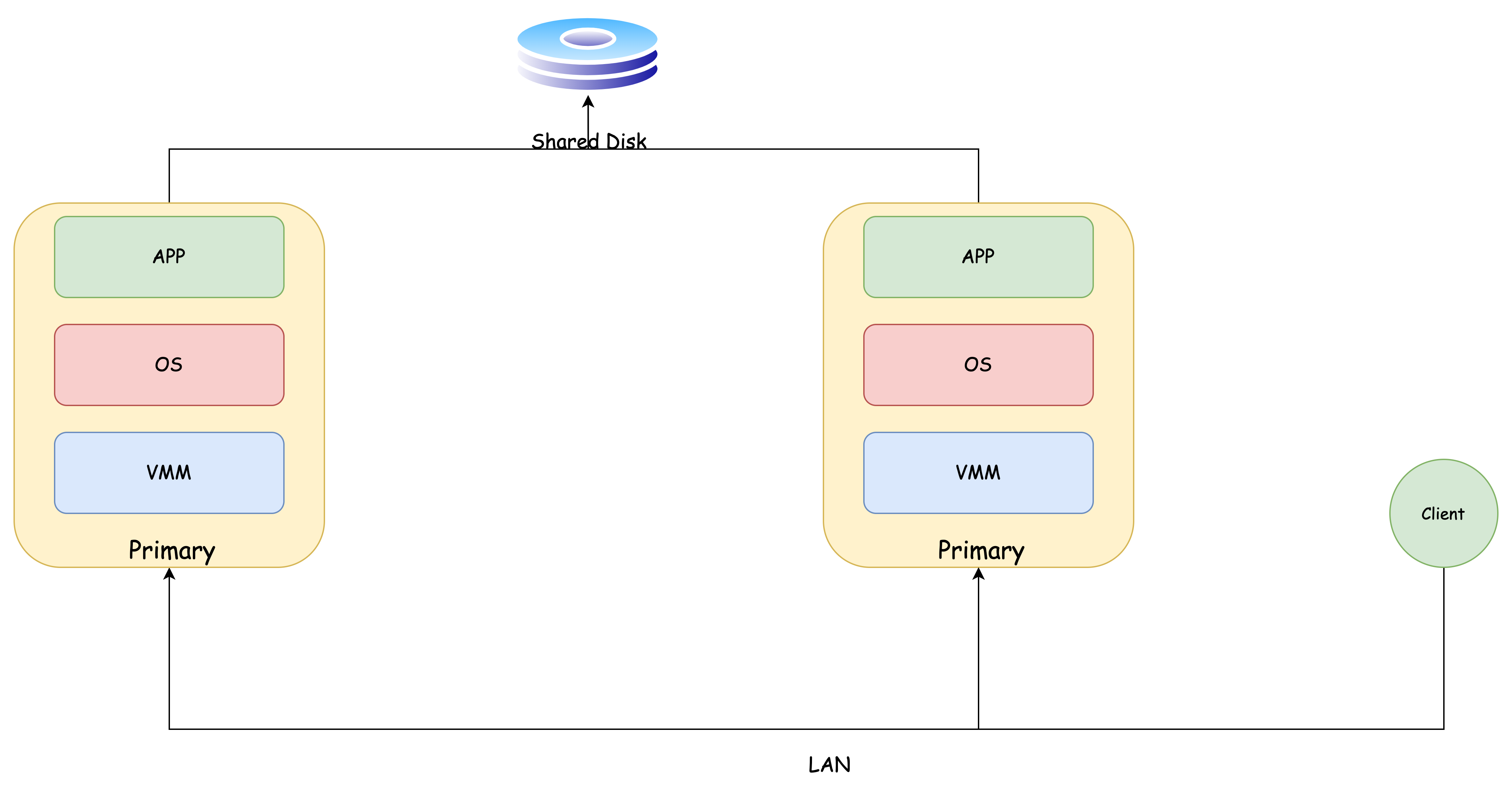
当 Client 向 Primary 发送一个请求:
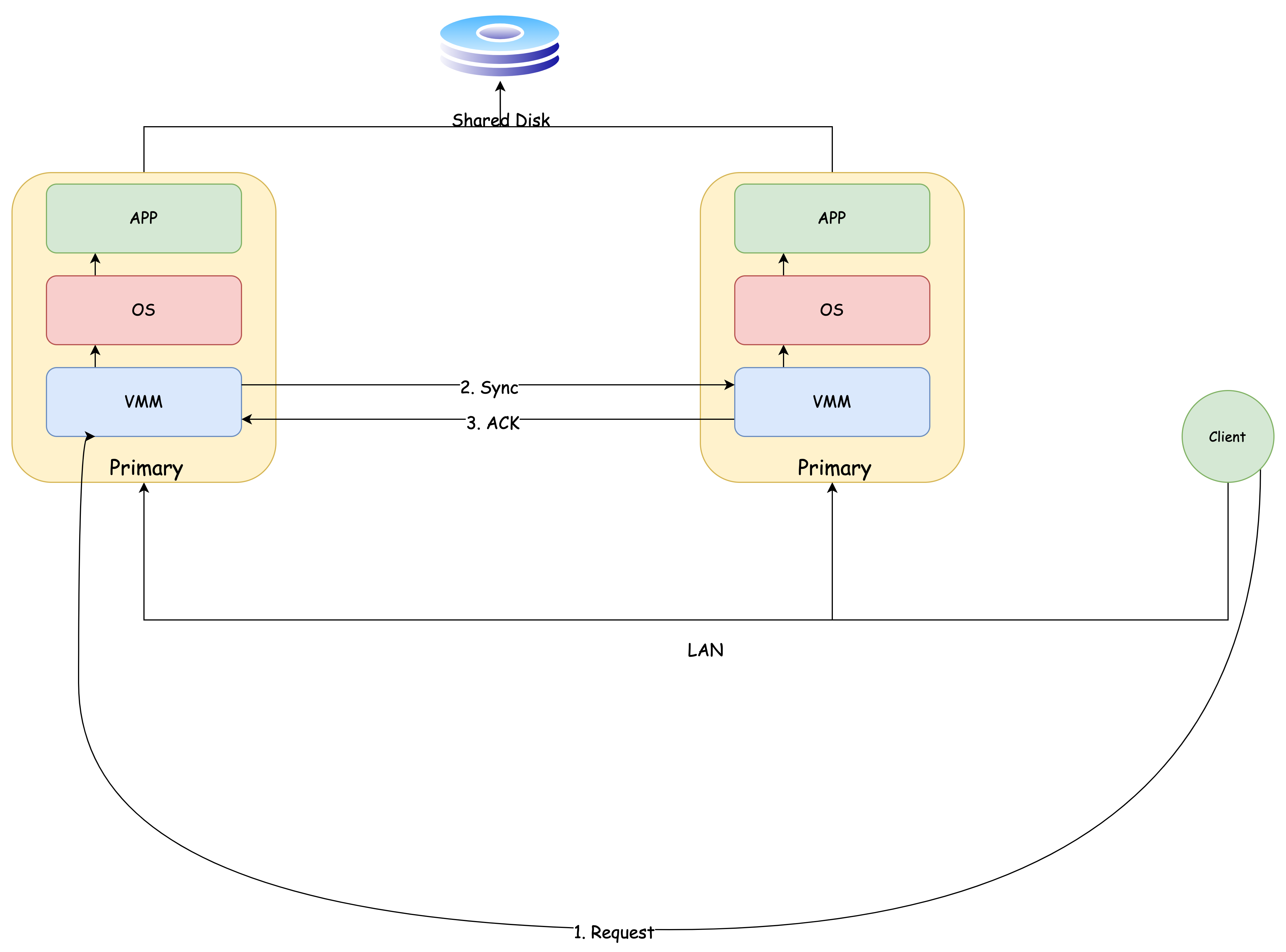
Client 发送给 Primary 的请求首先会被 VMM 观察到
VMM 会向上传输数据给 OS,并且给 Backup 同步这一网络数据包
Primary、Backup 的 App 执行完毕以后,需要返回结果给 Client:
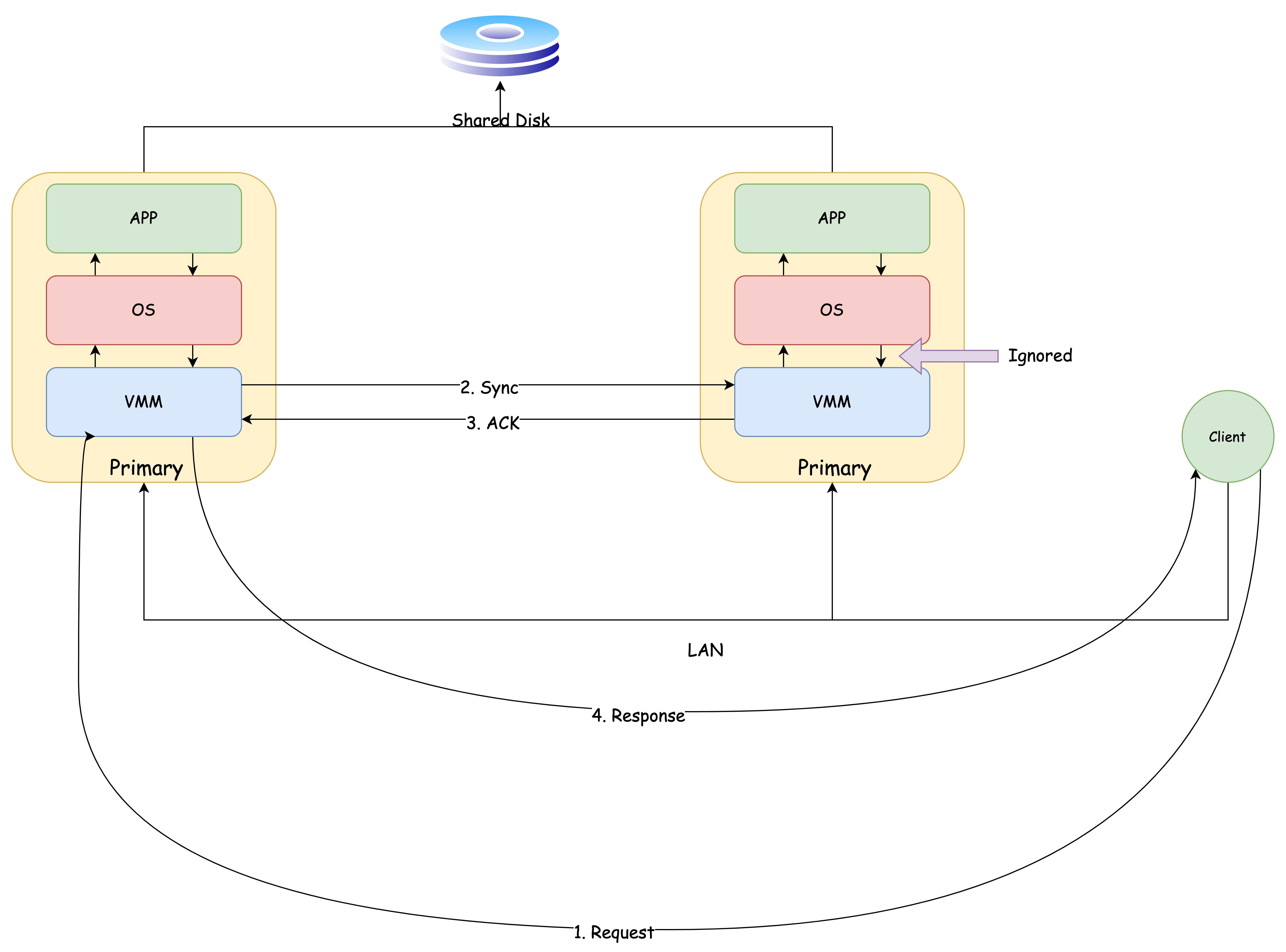
Backup 的返回结果会在 VMM 这一层被拦截,只需要 Primary 响应就可以了,不需要重复输出
注意: Primary 在响应结果前,必须收到 Backup 的 ACK,这样才能保证客户端视角下的一致性(在输出控制 那一块会提到)
Primary 与 Backup 同步的数据流的通道称之为 Log Channel
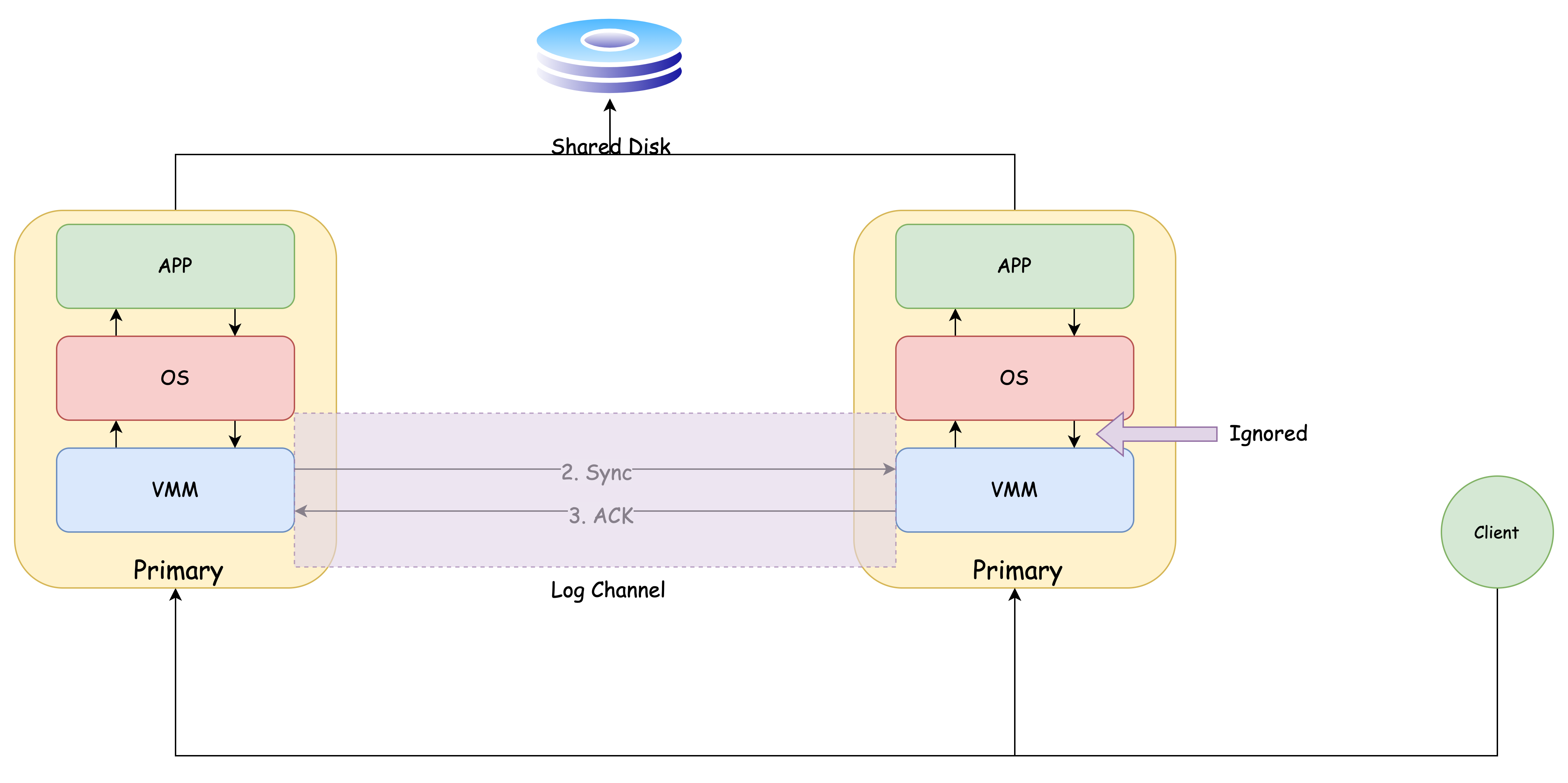
对于「怪异指令」的处理
什么是「怪异指令」?
简单来说,在 Primary 和 Backup 中产生不同结果的指令,就是「怪异指令」
比如获取当前时间,或者获取当前处理器序号,或者获取已经执行的的指令数,或者向硬件请求一个随机数用来加密,这种指令相对来说都很少见。
如果一个指令是怪异指令,在 Backup 上重放时会被特殊处理
输出控制
输出控制就是在 前面 提到的注意事项
具体直接看 Lecture4,Robert 教授的讲解 吧
Test-And-Set 服务
当 Backup 在较长时间内都没有收到 Primary 在 Log Channel 上的同步请求,Backup 会认为 Primary 挂了
同样地,Primary 在较长一段时间内没有收到 Backup 的 ACK,也会认为 Backup 挂了
发生的条件有两种:
- Primary 或者 Backup 真的挂了
- 网络分区问题
Primary 或者 Backup 如果要想上线,不能直接上线(因为可能是单纯的网络分区问题,两个 Primary 会导致数据不一致),而是要经过 Test-And-Set 服务
Test-and-Set 服务不运行在 Primary 和 Backup 的物理服务器上,VMware FT 需要通过网络支持 Test-and-Set 服务。这个服务会在内存中保留一些标志位,当你向它发送一个 Test-and-Set 请求,它会设置标志位,并且返回旧的值。Primary 和 Backup 都需要获取 Test-and-Set 标志位,这有点像一个锁。为了能够上线,它们或许会同时发送一个 Test-and-Set 请求,给 Test-and-Set 服务。当第一个请求送达时,Test-and-Set 服务会说,这个标志位之前是 0,现在是 1。第二个请求送达时,Test-and-Set 服务会说,标志位已经是 1 了,你不允许成为 Primary。对于这个 Test-and-Set 服务,我们可以认为运行在单台服务器。当网络出现故障,并且两个副本都认为对方已经挂了时,Test-and-Set 服务就是一个仲裁官,决定了两个副本中哪一个应该上线。
也就是说,VMware-FT 的主从切换还是要依靠外部系统,不是独立的,这要求 Test-And-Set 服务本身具有一定的可用性(应该也是一个具有 FT 的系统)