线性一致
首先要了解一个概念:线性一致
一个系统的执行历史是一系列的客户端请求,或许这是来自多个客户端的多个请求。如果 执行历史 整体可以按照 一个顺序 排列,且排列顺序 与客户端请求的实际时间相符合,那么它是线性一致的。
有关「线性一致」的几个例子,可以看看 Robert 教授的讲座
总的来说:
- 线性一致 是对于存储系统中 强一致 的一种标准定义
- 线性一致的定义是 有关历史记录 的定义,而 不是系统的定义。所以我们不能说一个系统设计是线性一致的,我们只能说请求的历史记录是线性一致的。
- 强一致系统表现的也与系统中只有一份数据的拷贝一样,这与线性一致的定义非常接近。所以,可以合理的认为强一致与线性一致是一样的。
ZooKeeper
相比 Raft 来说,Raft 实际上就是一个库。你可以在一些更大的多副本系统中使用 Raft 库。但是 Raft 不是一个你可以直接交互的独立的服务,你必须要设计你自己的应用程序来与 Raft 库交互。
所以这里有一个有趣的问题:是否有一些有用的,独立的,通用的系统可以帮助人们构建分布式系统?是否有这样的服务可以包装成一个任何人都可以使用的独立服务,并且极大的减轻构建分布式应用的痛苦?
所以,第一个问题是,对于一个通用的服务,API 应该是怎样?我不太确定类似于 Zookeeper 这类软件的名字是什么,它们可以被认为是一个通用的 协调服务(General-Purpose Coordination Service)。
通过上面 Robert 教授说的这段话,可以知道:ZooKeeper 是一个分布式协调服务,用于帮助建立分布式系统
作为一个多副本系统,Zookeeper 本身是一个 容错的 ,通用的协调服务,它与其他系统一样,通过 多副本 来完成容错。
即然涉及到多副本,我们自然能想到:n 个副本能不能带来(近似) n 倍的性能提升?
对于 Raft 来说,n 个副本不仅不会带来 n 倍的性能提升,反而会导致性能下降
因为副本数越多,Leader 的压力就会越大,而 Raft 的 读写操作均在 Leader 进行,因此整体的吞吐肯定是下降的
那 ZooKeeper 呢?
这里直接给出结论:ZK 的 读 性能会随着副本数的增加而增加
这是一个好消息,因为 绝大多数的操作都是读操作,仅有少部分操作是写操作
或许你已经大概猜到为什么 ZK 的读性能会随着副本数的增加而增加,而写性能不会
如果我们将 读请求分发 到不同的节点(即 Leader 节点和 Follower 节点),就可以获得 n 倍的读性能提升
读请求分发到不同节点,是否存在不一致的问题?也就是说,还遵循「线性一致」吗?
ZK 的一致性保证
ZK 的论文在 2.3 小节提到:
ZooKeeper 有两个基本的顺序保证:
- 线性写:所有更新 ZooKeeper 状态的操作是串行的,先来先服务
- FIFO 客户端顺序:来自单个客户端的所有请求按客户端发送的顺序依次执行。
也就是说,ZK 的一致性保障可以总结为:
- 保证 所有客户端 写请求满足「线性一致」
- 保证 单个客户端 所有请求满足「线性一致」
从这里我们可以回答上面的问题:ZooKeeper 不保证所有客户端的读请求的「线性一致」,也就是说:客户端可能读取到 过期 的数据,这也是我们常说的「最终一致性」保障
事实上,对于任何分布式系统来说,写请求的「线性一致」是基本要求,如果写请求无法保证「线性一致」,那这个系统本身就没有什么意义,我们完全无法预料最终的结果是什么
相反,读请求可以根据「使用需求」来做 trade-off:
- 如果要强一致性保障,那么需要舍弃性能
- 如果需要读性能,那么需要舍弃一致性保障(只能最终一致)
如何保证写请求的线性一致
ZooKeeper 写请求线性一致保障实现原理,与 Raft 是类似的:
- 所有的写请求都由 Leader 处理并提交,这样可以确保写请求的全序。
- ZAB 协议 确保写请求只有在被过半追随者确认后才会被提交,从而保证了写请求的持久性和一致性。
- 事务日志和同步机制确保了在服务器崩溃或网络分区后,系统可以恢复并保持一致的状态。
ZAB 协议,与 Raft 协议类似,用于节点间数据同步,核心思想都是「过半票决」
如何保证单个客户端所有请求的线性一致
Zookeeper 通过 ZXID 来保障单个客户端请求的线性一致
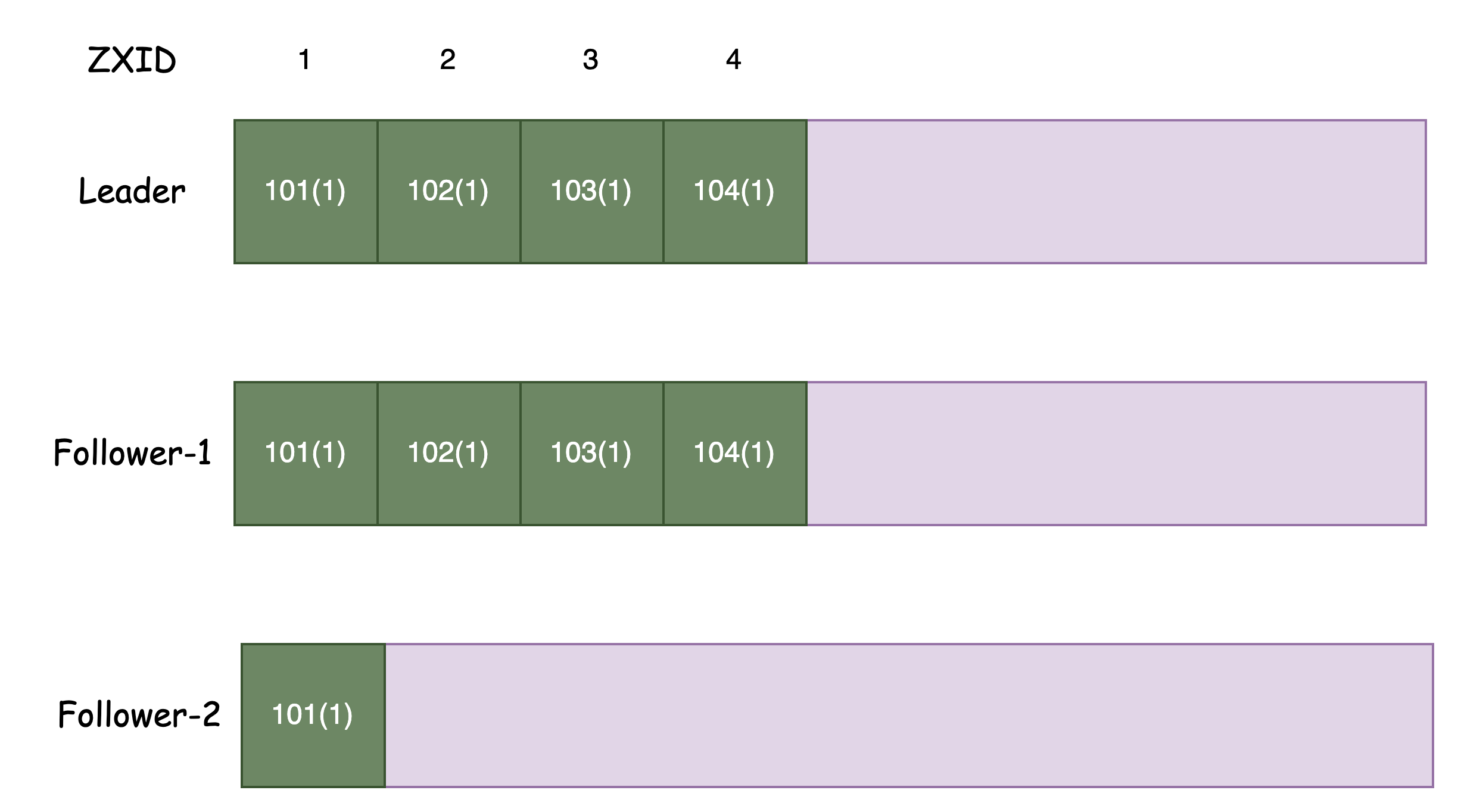
上面的图描述了当前 ZK 集群的 Logs 状态
假设 Client 在 Leader 执行了一次读请求:
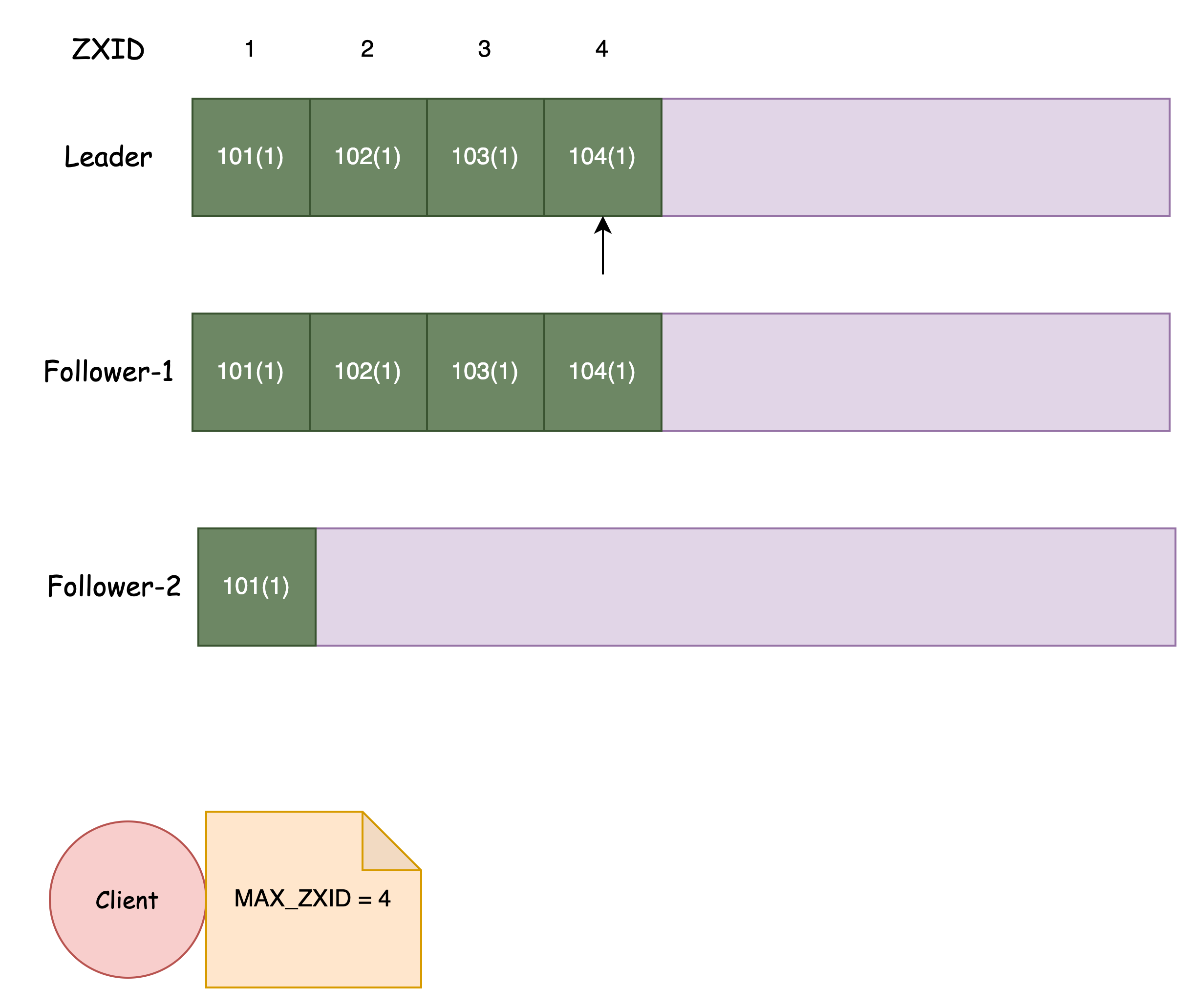
- Leader 返回执行当前请求时,对应的 ZXID = 4
- Client 记录下 ZXID,并取最大值保存到本地
为了保证请求的线性一致,客户端后续的请求,对应的 ZK 节点必须满足: LastZXID >= ClientZXID
当 ZK 节点接收到一个请求后,首先需要判断客户端携带的 ZXID
如果客户端携带的 ZXID 比本地日志的最大 ZXID 还要大,那么就无法为这个客户端提供服务,例如上图中的 Follower-2
对于这种情况,客户端有两种选择:等待;或者选择其它 ZK 节点
同步操作(sync)
通过前面的介绍,我们知道客户端可能读取到「过期」的数据(Follower 没有同步到最新位置,就为 Client 提供读服务)
如果客户端想要读取 最新的 数据怎么办?
ZooKeeper 提供了一个 Sync API 实现这一点
Sync API 实际上就是一个 写请求,只不过这个写请求并不实际写入任何数据
我们知道 ZK 保证所有客户端写请求的线性一致性,因此调用 Sync API 后,必须要 半数以上 的节点确认了这条 Sync 后,Sync API 才会返回
那也仅仅是半数节点啊,如果客户端请求的是处于「另一个分区」的 ZK Node 呢?
别急,Sync 返回的同时不是还会带上 ZXID 吗,客户端下次执行读请求时,带上这个 ZXID,只有请求的 ZK Node 同步到这个位置以后才能提供服务
通过上面的分析,得出结论:调用 Sync 后,可以保证客户端看到 Sync 对应的状态,可以合理地认为是最新的
就绪文件(Ready File)
ZooKeeper 最广泛的应用场景,就是 管理集群的元数据 了
ZK 将这些数据以「文件」的形式存储,也被叫做「ZNode」
然而,这些数据不会一成不变,肯定会随着集群的运行,动态发生变化
那么如何更新这些元数据呢?
我们当然不希望客户端获取到部分更新的元数据(通常来说这些数据没有任何意义),因此必须满足 原子更新
ZooKeeper 使用就绪文件(Ready File)来标记一个文件(ZNode)是否可用(存在)
所谓 Ready File,就是以 Ready 为名字的 file。如果 Ready file 存在,那么允许读这个配置。如果 Ready file 不存在,那么说明配置正在更新过程中,我们不应该读取配置。
如果一个客户端要更新元数据,它的执行流是这样的:
delete("Ready-File-0") // 删除 Ready File
write(f1) // 写元数据
write(f2) // 写元数据
create("Ready-File-0") // 创建 Ready File
如果一个客户端要读取元数据,它的执行流是这样的:
exists("Ready-File-0", watch = true) // 检查 Ready File 是否存在
read(f1) // 如果存在,读取元数据
read(f2)
我们考虑下面这种情况:
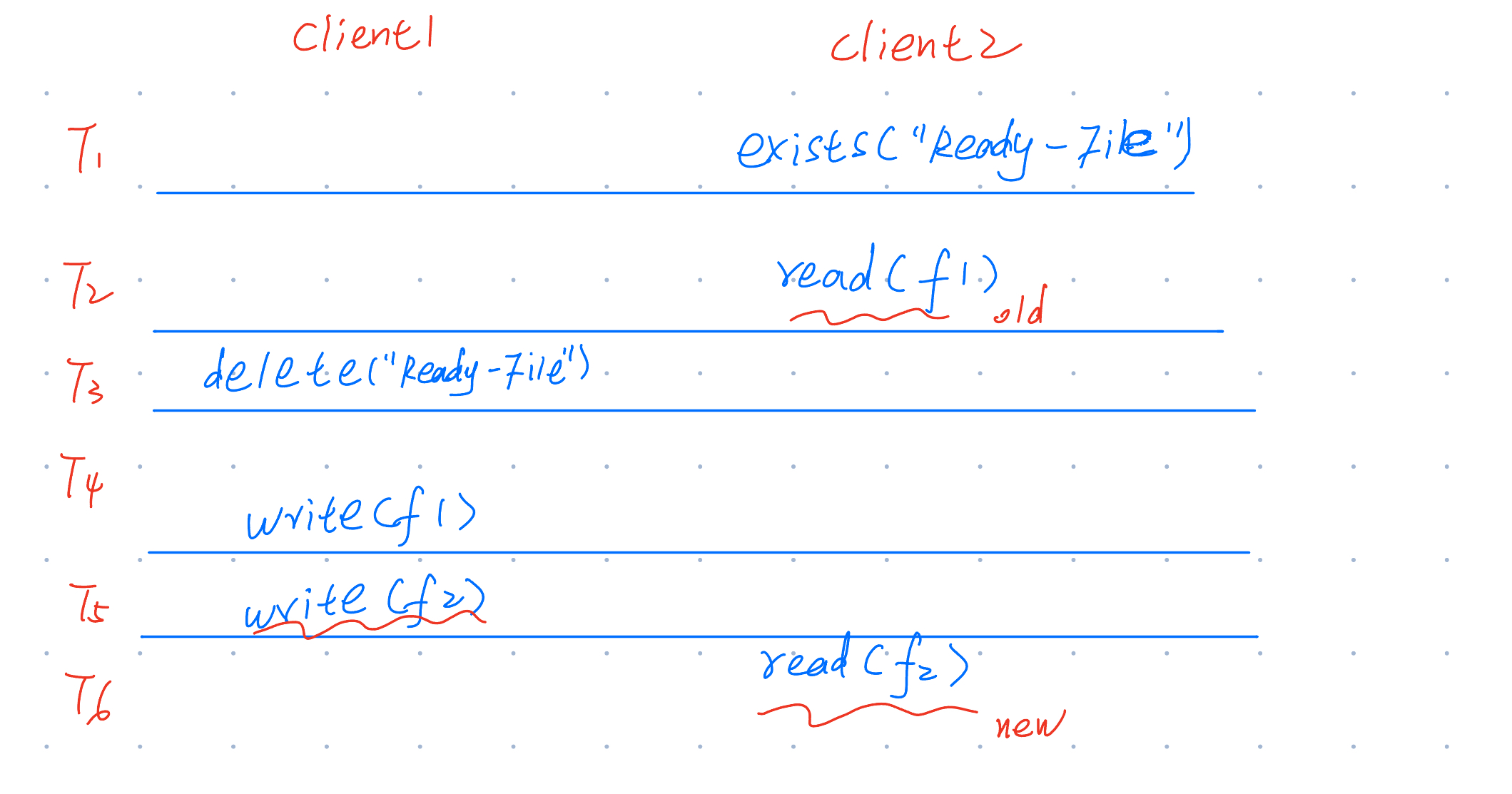
容易发现,Client2 此时读取的元数据是「错误」的:旧的 f1 + 新的 f2,没有任何意义
那么 ZK 是如何解决这种情况,即实现「原子」修改呢?
watch 机制
调用 exists API,不仅仅会判断 Ready File 是否存在,还会注册一个 watch 事件,即监听 Ready File 的状态
当一个客户端想要修改 Ready File 时,ZK 会 先通知 之前 watch 这个 Ready File 的客户端,告诉它们这个 Ready File 发生了变化,然后再真正执行 Ready File 的修改
当客户端收到 ZK 的通知(Ready File 发生变化),客户端会立刻终止此次读取行为,然后再重试读:
