前置知识
OS Scheduler
在介绍 Go Scheduler 之前,先要了解一下 OS Scheduler
OS Scheduler 是在 OS 层面实现的调度器,调度的基本单位为(内核级)线程,保证在尽可能公平的条件下,充分利用 CPU 资源
在 OS Scheduler 的调度下,各个线程看起来是同时运行的,也就是通常意义上的「并发」
goroutine
什么是 goroutine
前面提到 OS Scheduler 调度的基本单位为内核级线程,但是内核级线程的创建、切换、销毁的代价相对还是比较高的(涉及到用户态与内核态的切换)
在 C++、Java 中,并发编程使用到的就是内核级线程,一般都会使用线程池,来复用线程,以减小线程的创建、切换、销毁的代价
但是 Go 引入了 goroutine,以另一个角度来以减小线程的创建、切换、销毁的代价
goroutine 是在 用户态实现 的线程(通常也叫做协程),这意味着 goroutine 的创建、切换、销毁完全是在用户态进行的
有了 goroutine,Gopher 不会直接面对 kernel thread,我们只会看到代码里满天飞的 goroutine。OS 却相反,goroutine 对 OS 是不可见的,OS 只需要关心内核级线程就可以了
基于 goroutine,Go 天然支持高并发
goroutine 与 kernel thread 的区别
- 创建、销毁:goroutine 的创建与销毁代价极低,不涉及变态
- 内存占用:单个 goroutine 的栈空间仅有 2KB,而单个 kernel thread 的栈空间却有 1M
- 切换:goroutine 的切换,涉及到的寄存器比 kernel thread 少,上下文切换时间短
Scheduler
什么是 Go Scheduler
Go Scheduler 是 Go 在用户态实现的调度器,负责 goroutine 的调度
一个使用 Go 编写的应用,包含两个部分:
- program
- runtime
内存分配、基于 channel 的 通信、goroutine 的创建都是在 runtime 进行的:
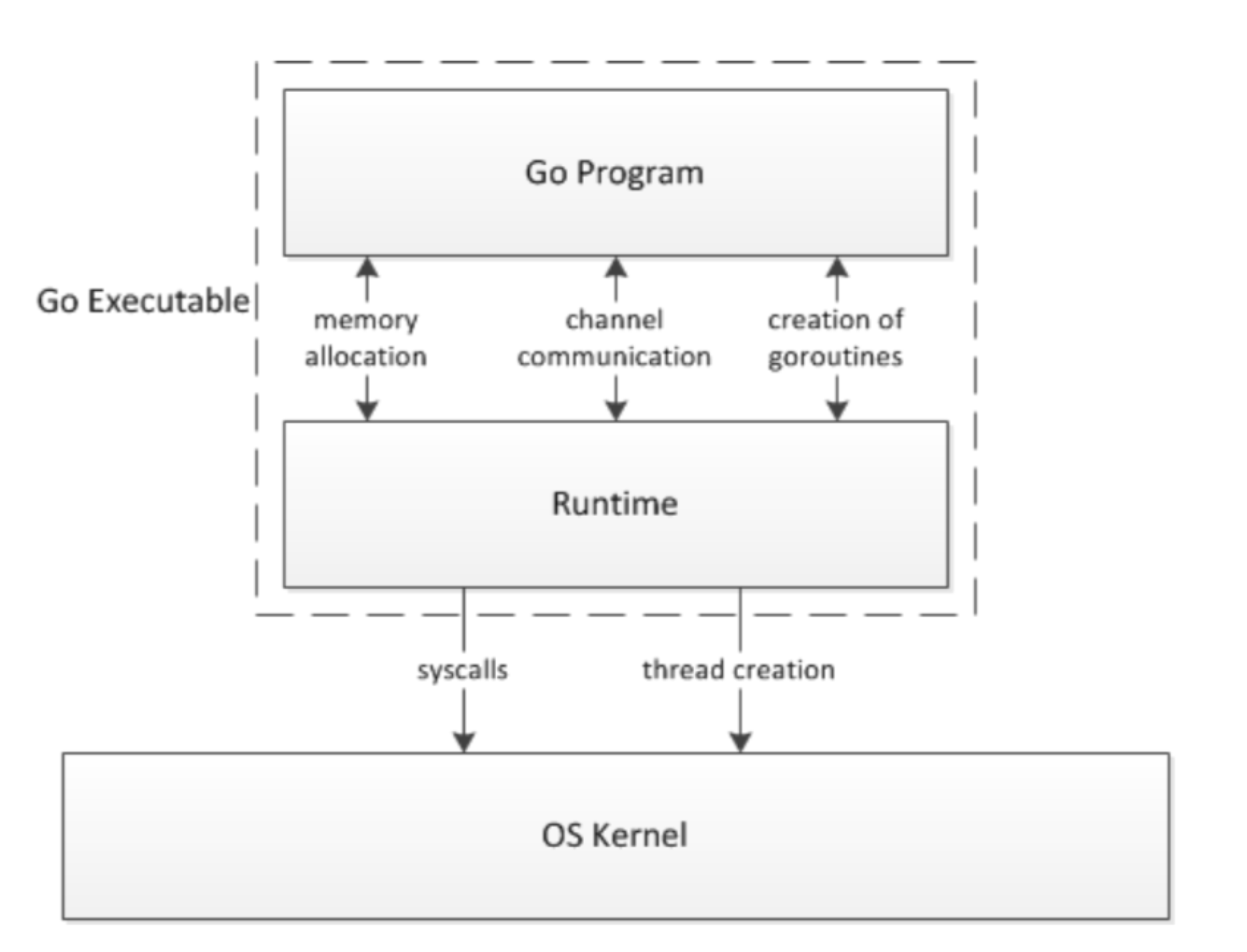
为什么要 Go Scheduler
scheduler 是 runtime 最重要的一部分,负责了所有 goroutine 的调度,是 goroutine 能并发执行的基石,如果没有 scheduler,那么 goroutines 就是一盘散沙
程序执行的效率也与 schduler 的调度策略有关,好的 scheduler 可以更好的利用 CPU 资源,保证性能和响应速度
Scheduler 概览
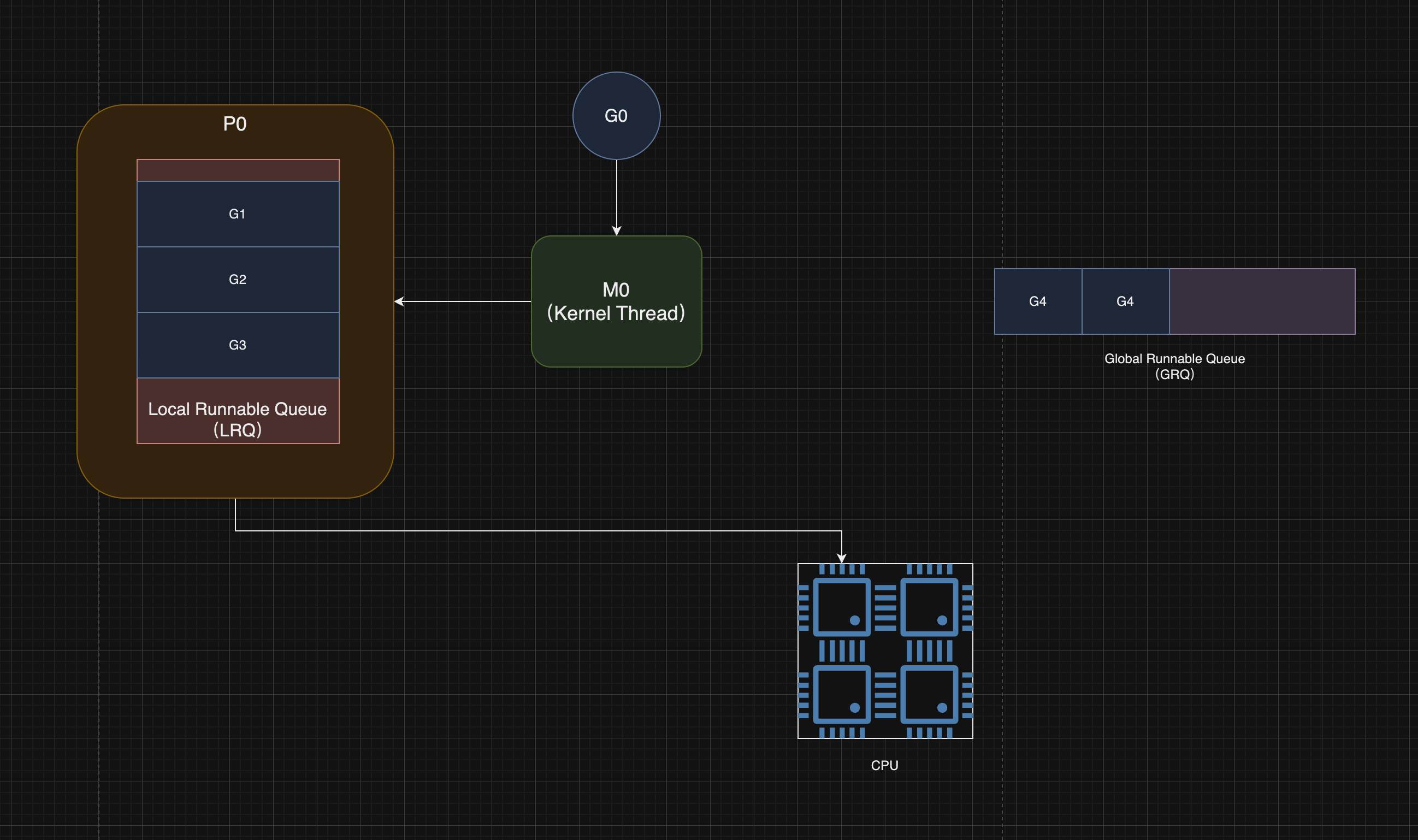
scheduler 的调度,离不开三个结构体:
- Goroutine (G)
- Machine(M):可以理解为一个 M 对应了一个 kernel thread
- Processor(P):可以理解为一个 P 对应了一个 CPU 逻辑处理器
Machine(M)
goroutines 并不是直接与操作系统线程相绑定的,而是通过 M 来执行。一个 M 往往负责多个 G 的执行
Processor(P)
Processor(P)的数量取决于 CPU 的逻辑处理器个数
P 会维护一个本地队列,这个队列存储了可执行(Runnable)状态的 goroutine(G)
G 的执行依赖于 M,而 M 需要获得 P 才能执行 G
在一个时刻,一个 P 只能关联一个 M,这样,可以控制整个应用程序中,kernel thread 的数量,减少 kernel thread 创建、切换、销毁的开销
用一张图来展示 G、M、P 三者关系:
2024.4.7:
Global Runnable Queue:存储全局可运行的 goroutine 的队列,这些 goroutine 还没有分配到任意的 P
那么,一个 goroutine 在什么时候会被存放到全局队列(GRQ)?
- 刚刚创建的 goroutine 可能被分配到 GRQ 中
- goroutine 运行时间过长:Go scheduler 会启动一个后台线程 sysmon,用来检测长时间(超过 10 ms)运行的 goroutine,将其调度到 GRQ,以示惩罚(优先级较低)
- 待补充。。。
Scheduler 的目标
- 仅使用较少的 kernel thread(复用 M)
- 支持高并发(G 的轻量级、较少的 M、优秀的调度)
- 利用并行性,扩展到 N 个逻辑核(N 个 P)
goroutine 被调度的时机
- 创建一个新的 goroutine
- 发起 syscall
- GC
- goroutine 阻塞(例如因为 channel、mutex)
M 是如何选择 goroutine 的
M 选择 goroutine 执行这一过程就是 scheduler 的调度,策略如下:
- 在关联的 P 的本地队列拉取一个 goroutine 执行
- 为了保证公平性,每循环 61 次,从全局队列中拉取一个 goroutine 执行
- 如果关联的 P 的本地队列中,没有 goroutine,那么 M 会尝试在其它 P 的本地队列中「偷取」一半的 goroutines 到关联的 P 的本地队列。这个过程被称为
Work-stealing
// Go 1.9
// 执行一轮调度器的工作:找到一个 runnable 的 goroutine,并且执行它
// 永不返回
func schedule() {
// _g_ = 每个工作线程 m 对应的 g0,初始化时是 m0 的 g0
_g_ := getg()
// ……………………
top:
// ……………………
var gp *g
var inheritTime bool
// ……………………
if gp == nil {
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
// 为了公平,每调用 schedule 函数 61 次就要从全局队列中获取一个 goroutine
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
// 从全局队列最大获取 1 个 gorutine
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
// 从 P 本地获取 G 任务
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
if gp != nil && _g_.m.spinning {
throw("schedule: spinning with local work")
}
}
if gp == nil {
// 从本地运行队列和全局运行队列都没有找到需要运行的 goroutine,
// 调用 findrunnable 函数从其它工作线程的运行队列中偷取,如果偷不到,则当前工作线程进入睡眠
// 直到获取到 runnable goroutine 之后 findrunnable 函数才会返回。
gp, inheritTime = findrunnable() // blocks until work is available
}
// This thread is going to run a goroutine and is not spinning anymore,
// so if it was marked as spinning we need to reset it now and potentially
// start a new spinning M.
if _g_.m.spinning {
resetspinning()
}
if gp.lockedm != nil {
// Hands off own p to the locked m,
// then blocks waiting for a new p.
startlockedm(gp)
goto top
}
// 执行 goroutine 任务函数
// 当前运行的是 runtime 的代码,函数调用栈使用的是 g0 的栈空间
// 调用 execute 切换到 gp 的代码和栈空间去运行
execute(gp, inheritTime)
}
同步与异步 syscall
前面说到:在任意时刻,一个 P 只能关联一个 M
那么,如果 M 阻塞了,怎么办呢?
M 阻塞的情况通常出现于 同步系统调用
M 一旦阻塞,P 本地队列中的 goroutine 就无法运行了
为了避免这种情况,scheduler 会将阻塞的 M 与关联的 P 分离开,然后创建一个新的 M 关联这个 P
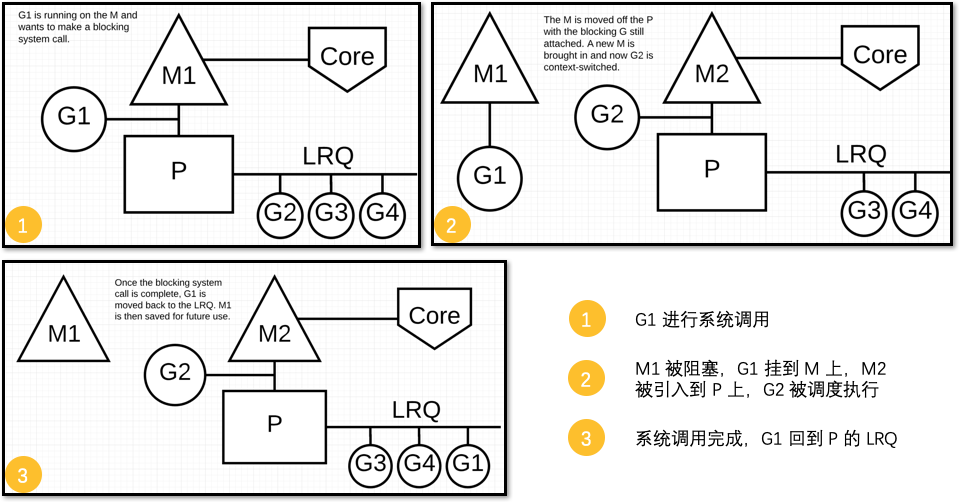
M 恢复后,对应的 goroutine 会重新回到 LRQ,而 M 则保存下来留着以后使用
对于异步的系统调用,情况有所不同:发起异步调用的 goroutine 会交给 net poller 来管理,M 得以释放,给剩余的 goroutine 执行机会:
Go 的网络轮询器(net poller)是 Go 运行时(runtime)用来高效处理 I/O 操作的一部分。网络轮询器底层利用操作系统提供的事件通知机制,例如 Linux 的 epoll,可以非阻塞地等待一组文件描述符上的 I/O 事件。
当 goroutine 执行一个网络 I/O 操作时,如果数据准备好了,它会立即处理。如果数据没有准备好,goroutine 会被 挂起,并被 加入到等待队列中。网络轮询器会监测对应的文件描述符,等待事件发生。
当相关事件发生,如连接建立、数据到达、可以发送数据等,系统通知网络轮询器,网络轮询器会 唤醒 之前挂起的 goroutine。
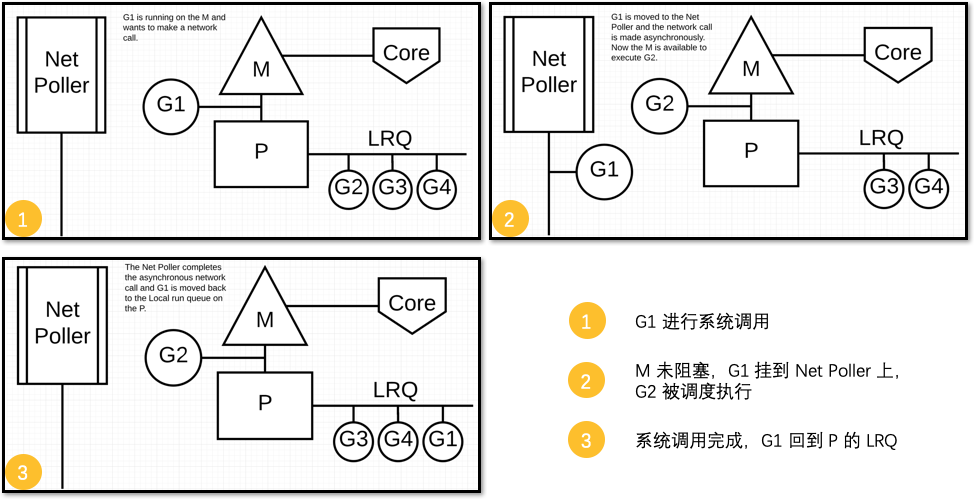
从这里可以看出来:只要有 Runnable 的 goroutine,scheduler 不会让任何 M 闲下来
In Go, it’s possible to get more work done, over time, because the Go scheduler attempts to use less Threads and do more on each Thread, which helps to reduce load on the OS and the hardware.
为什么需要 P,只要 G、M 不行吗?
在 Go 1.5 之前,实际上是没有 P 的,只有 G、M
在只有 G、M 的情况下,所有的 M 都要在一个 全局的队列 中获取 Runnable goroutine,那么这个过程一定要加一把 大锁,锁的粒度大,并发能力不强
于是 Go 1.5 引入了 P,每个 P 维护一个 LRQ,避免了加锁,并发能力得到提升
为什么一定要有一个 P,直接让 M 来管理 LRQ 不行吗?
前面提到了:M 可能被阻塞,如果 M 被阻塞,那么 M 的 LRQ 中剩余的 goroutines 无法被执行,并发能力也降低了
因此,P 的存在相当于将 LRQ 与 M 解耦,是很有必要的
参考资料
本文仅仅是浅浅介绍了一下 Go Scheduler,要想深入了解,可以看看 这个系列的文章