Single Flight 是 Go pkg 中提供的一个工具,通常用于防止缓存击穿
假设这个场景:
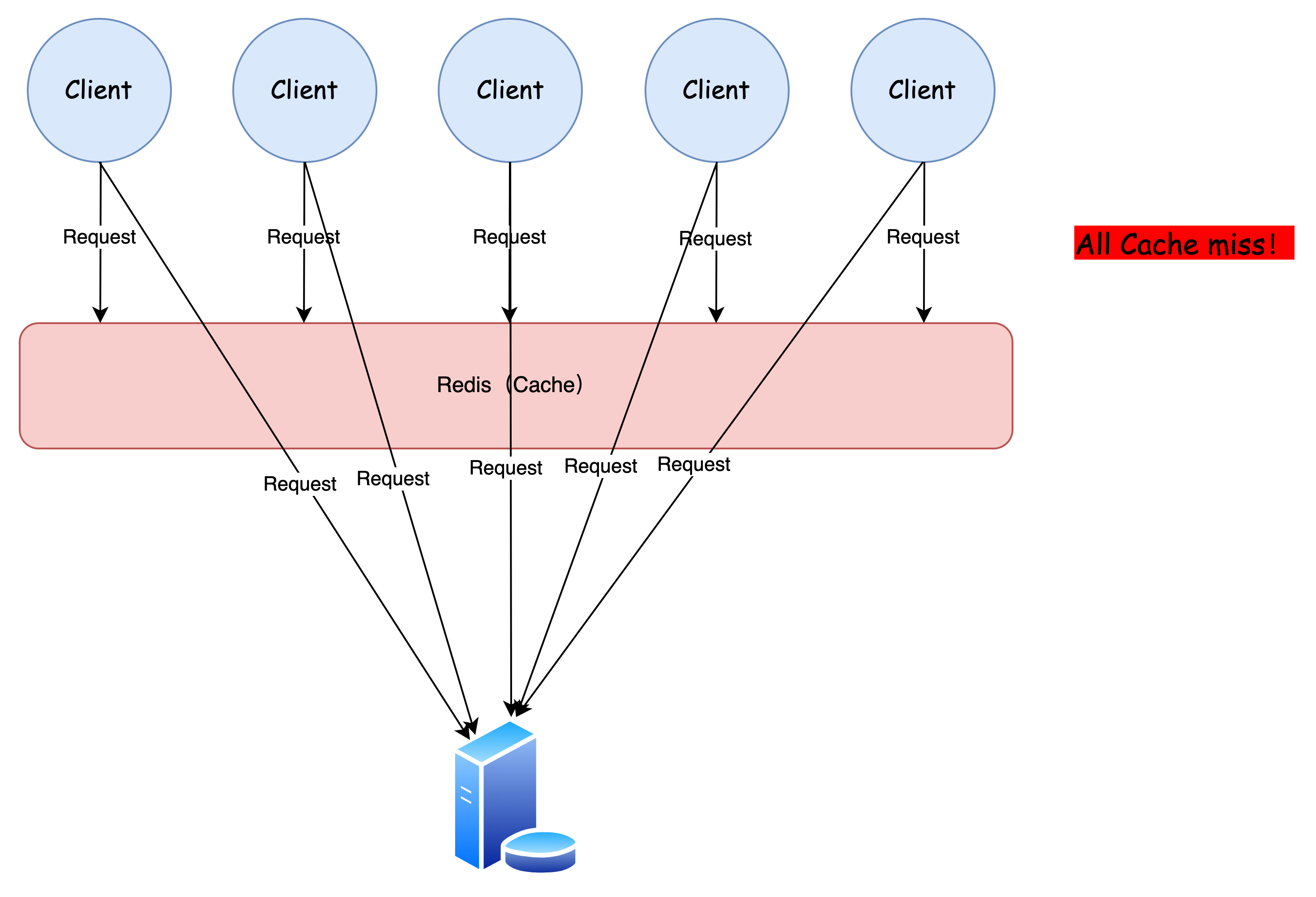
大量客户端请求的缓存均过期了,不得不直接访问 DB,如此高的并发,很有可能将 DB 服务打垮
引入 SingleFilght 工具,可以在一定程度上减缓这种情况
Package singleflight provides a duplicate function call suppression mechanism.
singleflight 包提供了重复函数调用 抑制 机制
使用
SingleFlight 提供了以下 API:
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool)
func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result
func (g *Group) Forget(key string)
Do 方法接收一个函数作为参数,返回函数的执行结果(v、err),以及这个结果是不是被多个 goroutine shared
DoChan 在 Do 方法的基础上,引入了超时控制,返回一个 channel
Forgety 方法用于删除一个 key,防止获取过期的结果
示例 0:基本使用
先来看看不用 SingleFlight:
package main
import (
"errors"
"fmt"
"sync"
"time"
)
var ErrCacheMiss = errors.New("cache miss")
func GetUserInfo() (any, error) {
userInfo, err := ReadFromCache()
if err != nil {
userInfo, err = ReadFromDB()
if err != nil {
return nil, err
}
// 缓存回源
// 这里省略
}
return userInfo, err
}
var wg sync.WaitGroup
func main() {
const N = 100 // 模拟 100 个 Client 的并发请求
wg.Add(N)
for i := 0; i < N; i++ {
go func() {
defer wg.Done()
GetUserInfo()
}()
}
wg.Wait()
}
func ReadFromCache() (v any, err error) {
return nil, ErrCacheMiss
}
func ReadFromDB() (v any, err error) {
fmt.Println("Read From DB")
time.Sleep(time.Second)
// 模拟从数据库读取数据
return "read from DB", nil
}
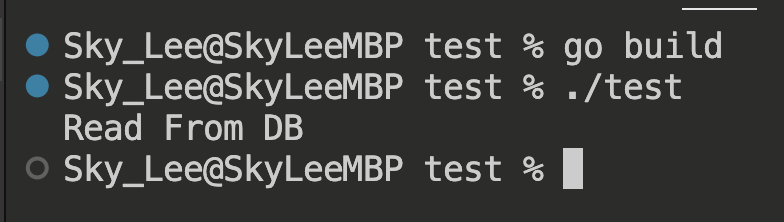
输出:
Sky_Lee@SkyLeeMBP test % ./test
Read From DB
Read From DB
Read From DB
Read From DB
Read From DB
Read From DB
Read From DB
Read From DB
Read From DB
...
Read From DB
所有请求都直接走到 DB,那么使用 singleflight 呢?
for i := 0; i < N; i++ {
go func() {
defer wg.Done()
sg.Do("GetUserInfo", GetUserInfo) // 使用 single flight
}()
}
输出:
可以看到,仅仅走了一次 DB!
示例 1:超时控制
引入超时控制:
// ...
for i := 0; i < N; i++ {
go func() {
defer wg.Done()
ctx, cancel := context.WithTimeout(context.Background(), 3*time.Second) // 控制超时时间为 3s
defer cancel()
ch := sg.DoChan("GetUserInfo", GetUserInfo)
var res singleflight.Result
select {
case res = <-ch:
case <-ctx.Done():
// 超时返回
fmt.Println("timeout")
return
}
fmt.Println(res.Val)
}()
}
// ...
// 修改 ReadFromDB 的时间
func ReadFromDB() (v any, err error) {
fmt.Println("Read From DB")
time.Sleep(time.Second * 5) // 模拟长查询
// 模拟从数据库读取数据
return "read from DB", nil
}
输出:
Sky_Lee@SkyLeeMBP test % ./test
Read From DB
timeout
timeout
...
timeout
成功将时间控制在 3s 内
示例 2:定期 forget
为了防止获取到过期数据,可以定期 forget,以多请求 DB 来换取数据的时效性
例如:
for i := 0; i < N; i++ {
go func() {
defer wg.Done()
sg.Do("GetUserInfo", GetUserInfo)
go func() {
time.Sleep(100 * time.Millisecond)
sg.Forget("GetUserInfo") // 100ms 后删除 GetUserInfo 这个 key,接下来的并发请求,将会走 GetUserInfo,而不是等待
}()
}()
}
睡眠的时间可以根据下游服务的 rps 确定,例如允许的 rps 为 10req/s,那么可以设置 100ms 后删除这个 key
当然,在 GetUserInfo 返回后,为了数据的时效性,singleflight 内部是会将这个 key 删除的
这里 forget 针对的是在 GetUserInfo 返回前,100ms 后如果有新的请求,那么就再调用一次 GetUserInfo,而不是继续等待
原理
数据结构
type Group struct {
mu sync.Mutex // protects m
m map[string]*call // lazily initialized
}
singleflight 的数据结构非常简单,只有两个字段:
- mu:保护 m 的互斥访问,进一步保证 m 的 goroutine 安全
- m:存放 key ~ call 的映射关系
其中,call 的定义如下:
type call struct {
wg sync.WaitGroup // 用于等待一个 goroutine 执行完毕
val interface{} // 存放执行结果
err error // 存放执行中产生的错误
dups int // 存放当前等待的 goroutine 的个数
chans []chan<- Result // 存放 DoChan 生成的 channel
}
Group.m 是懒加载的:
- 使得 Group 开箱即用
Do
接下来看看 Do 方法:
func (g *Group) Do(key string, fn func() (interface{}, error)) (v interface{}, err error, shared bool) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call) // 懒加载 map
}
// 如果这个 key 存在,说明已经有一个 goroutine 正在执行 fn,我们应该等待
if c, ok := g.m[key]; ok {
c.dups++ // 当前等待的 goroutine +1
g.mu.Unlock()
c.wg.Wait() // 等待
if e, ok := c.err.(*panicError); ok { // 如果执行 fn 的过程 panic 了,我们将 panic 返回给 caller
panic(e)
} else if c.err == errGoexit { // 如果执行 fn 的过程中,fn 调用了 runtime.GoExit()
runtime.Goexit()
}
return c.val, c.err, true // 返回第一个调用 fn 的调用结果
}
// 如果这个 key 不存在,说明我们是第一个执行 fn 的
// new 一个 call
c := new(call)
c.wg.Add(1)
g.m[key] = c // 让后续来的 goroutine 能够知道已经有一个 goroutine 在执行 fn
g.mu.Unlock()
g.doCall(c, key, fn) // 这里面会同步执行 fn
return c.val, c.err, c.dups > 0
}
过程全部放在注释中了,还是比较简单的
doCall
doCall 是 singleflight 的核心了,我们直接上源码:
// doCall handles the single call for a key.
func (g *Group) doCall(c *call, key string, fn func() (interface{}, error)) {
normalReturn := false
recovered := false
// use double-defer to distinguish panic from runtime.Goexit,
// more details see https://golang.org/cl/134395
defer func() {
// the given function invoked runtime.Goexit
if !normalReturn && !recovered {
c.err = errGoexit
}
g.mu.Lock()
defer g.mu.Unlock()
c.wg.Done()
if g.m[key] == c {
delete(g.m, key)
}
if e, ok := c.err.(*panicError); ok {
// In order to prevent the waiting channels from being blocked forever,
// needs to ensure that this panic cannot be recovered.
if len(c.chans) > 0 {
go panic(e)
select {} // Keep this goroutine around so that it will appear in the crash dump.
} else {
panic(e)
}
} else if c.err == errGoexit {
// Already in the process of goexit, no need to call again
} else {
// Normal return
for _, ch := range c.chans {
ch <- Result{c.val, c.err, c.dups > 0}
}
}
}()
func() {
defer func() {
if !normalReturn {
// Ideally, we would wait to take a stack trace until we've determined
// whether this is a panic or a runtime.Goexit.
//
// Unfortunately, the only way we can distinguish the two is to see
// whether the recover stopped the goroutine from terminating, and by
// the time we know that, the part of the stack trace relevant to the
// panic has been discarded.
if r := recover(); r != nil {
c.err = newPanicError(r)
}
}
}()
c.val, c.err = fn()
normalReturn = true
}()
if !normalReturn {
recovered = true
}
}
有点长,我们分解成若干部分来看:
部分 0
// 调用匿名函数
func() {
// 匿名函数返回前,执行 defer 语句
defer func() {
if !normalReturn {
// 说明 fn 执行过程 panic 了,先 recover 住
if r := recover(); r != nil {
c.err = newPanicError(r) // 给执行结果 c 的 err 字段赋值一个 panicError 类型的 error
}
}
}()
c.val, c.err = fn() // 先调用 fn
normalReturn = true // 如果执行到这里,说明 fn 没有 panic,也没有调用 runtime.GoExit()
}()
if !normalReturn {
// 如果执行到这里,说明 fn 没有调用 runtime.GoExit,而是 panic 了,但是被我们 recover 了
recovered = true
}
这一部分主要注意两个异常的处理:
- panic
- runtime.GoExit
如果 fn 执行过程 panic 了,会创建一个 panicError,包含了 panic 的堆栈信息:
// A panicError is an arbitrary value recovered from a panic
// with the stack trace during the execution of given function.
type panicError struct {
value interface{}
stack []byte
}
func newPanicError(v interface{}) error {
stack := debug.Stack()
// The first line of the stack trace is of the form "goroutine N [status]:"
// but by the time the panic reaches Do the goroutine may no longer exist
// and its status will have changed. Trim out the misleading line.
if line := bytes.IndexByte(stack[:], '\n'); line >= 0 {
stack = stack[line+1:]
}
return &panicError{value: v, stack: stack}
}
部分 1
// 使用 double-defer 来区分 panic 与 Goexit,
// 更多细节查看:https://golang.org/cl/134395
defer func() {
if !normalReturn && !recovered {
// 如果没有被 recover,说明 fn 内部调用了 runtime.GoExit
// 给 err 赋值为 errGoexit
c.err = errGoexit
}
g.mu.Lock()
defer g.mu.Unlock()
c.wg.Done()
if g.m[key] == c {
// fn 执行完毕了,删除 key,保证后续请求重新执行 fn
// 注意:执行结果已经存储在 c 中,之前等待的 goroutine 直接返回 c.val, c.err 即可
delete(g.m, key)
}
if e, ok := c.err.(*panicError); ok {
// 执行到这,说明 fn 执行过程 panic 了
// 为了保证等待 channel 的 goroutine(针对 DoChan 方法)不被永久阻塞
// 需要保证这个 panic 无法被 recover
if len(c.chans) > 0 { // 说明调用过 DoChan 方法
go panic(e) // 新建一个 goroutine 来 panic(父 goroutine 无法 recover 子 goroutine 的 panic)
select {} // 让这个 goroutine 阻塞,这样它可以出现在错误堆栈信息中
} else {
panic(e) // 没有调用过 DoChan 方法,意味着没有 goroutine 因为 channel 而阻塞,我们直接 panic 就行(允许调用者 recover)
}
} else if c.err == errGoexit {
// 在 fn 中已经调用过 runtime.Goexit,我们不需要再次执行
} else {
// 正常返回
// 唤醒所有等待 channel 的 goroutine
for _, ch := range c.chans {
ch <- Result{c.val, c.err, c.dups > 0}
}
}
}()
细节已经在注释中给出
根据两个部分的代码,可以看出:doCall 使用 double-defer 来分辨 fn 中的 panic 与 runtime.Goexit
这里补充一下 runtime.Goexit
Goexit terminates the goroutine that calls it. No other goroutine is affected.
Goexit runs all deferred calls before terminating the goroutine. Because Goexit is not a panic, any recover calls in those deferred functions will return nil.
DoChan
DoChan 与 Do 的区别在于:DoChan 会先返回一个 channel 用作超时控制,异步执行 fn:
// DoChan is like Do but returns a channel that will receive the
// results when they are ready.
//
// The returned channel will not be closed.
func (g *Group) DoChan(key string, fn func() (interface{}, error)) <-chan Result {
ch := make(chan Result, 1) // 新建一个带 buffer 的 channel(防止 doCall 发送阻塞)
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok { // 如果已经有 goroutine 执行过 fn
c.dups++
c.chans = append(c.chans, ch) // 加到 chans 中,后续可以在 doCall 中批量返回
g.mu.Unlock()
return ch
}
c := &call{chans: []chan<- Result{ch}}
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
go g.doCall(c, key, fn) // 异步执行 doCall
return ch
}
Forget
Forget 方法很简单,就是删除 Group.m 中的某个 key:
func (g *Group) Forget(key string) {
g.mu.Lock()
delete(g.m, key)
g.mu.Unlock()
}
总结
- Singleflight 是一个并发控制库,用于防止多个 goroutine 同时执行某个函数,避免重复执行,我们可以利用这个特性来防止缓存击穿
- Singleflight 开箱即用,提供了三个 API
- 在一些数据实时性要求较高的应用中,可以使用 forget 方法,来发起新的请求,而不是等待之前的请求返回
- doCall 方法使用 double-defer 来分辨 fn 中的 panic 与 runtime.Goexit