与数组最大的不同,切片支持动态扩容
切片(Slice)是一个拥有相同类型元素的可变长度的序列。它是基于数组类型做的一层封装。它非常灵活,支持自动扩容。
切片的内部结构包含地址、长度和容量。切片一般用于快速地操作一块数据集合。
定义
语法
var name []type
var sl []int
与数组的区别就是不需要指定元素的数量
例子:
var sl0 []int // 定义
var sl1 = []int{} // 定义并初始化
var sl2 = []int{1, 2}
var sl3 = []int{1, 2}
fmt.Printf("sl0: %v\n", sl0)
fmt.Printf("sl1: %v\n", sl1)
fmt.Printf("sl2: %v\n", sl2)
fmt.Printf("sl3: %v\n", sl3)
fmt.Printf("(sl0 == nil): %v\n", (sl0 == nil)) // true
fmt.Printf("(sl1 == nil): %v\n", (sl1 == nil)) // false
// (sl2 == sl3) 错误,切片之间不能比较,只能和 nil 比较
注意:切片之间不能比较,只能和 nil 比较
长度和容量
与数组不同,切片的长度和数量往往不一致,就像 std::vector 一样,这是切片的自动扩容机制决定的
可以使用 cap() 函数获取切片的容量:
var sl = []int{1, 2}
c := cap(sl)
切片表达式
切片表达式从字符串、数组、指向数组或切片的指针构造子字符串或切片。它有两种变体:
- 指定 low 和 high 两个索引界限值的简单的形式,
a[low:high] - 除了 low 和 high 索引界限值外还指定容量的完整的形式,
a[low,high,cap]
切片的 底层就是一个数组,所以我们可以基于数组通过切片表达式得到切片:
var arr = [5]int{1, 2, 3, 4, 5}
sl := arr[1:3] // [low, high)
fmt.Printf("sl: %v\n", sl) // 2 3
fmt.Printf("cap(sl): %v\n", cap(sl)) // 4
注意:不包含右边界
为什么容量是 4?这个会在后面讲「切片的本质」时提到
此外,还可以对一个切片再切片:
var arr = [5]int{1, 2, 3, 4, 5}
sl := arr[1:3] // [low, high), [2 3]
sl1 := sl[0:4] // 对 sl 切片,[2 3 4 5]
fmt.Printf("sl: %v\n", sl)
fmt.Printf("sl1: %v\n", sl1)
fmt.Printf("cap(sl): %v\n", cap(sl)) // 4
fmt.Printf("cap(sl1): %v\n", cap(sl1)) // 4
注意,再次分片时:high 的上限是切片的容量,对于上面的例子,即 cap(sl) == 4
完整的切片表达式
数组、指向数组的指针、切片支持完整切片表达式:
var arr = [4]int{1, 2, 3, 4} // 数组
sl := arr[0:4] // 切片
sl1 := arr[0:1:4] // [1], cap = 4
sl2 := sl[0:1:4] // [1], cap = 4
fmt.Printf("sl1: %v\n", sl1)
fmt.Printf("cap(sl1): %v\n", cap(sl1))
fmt.Printf("sl2: %v\n", sl2)
fmt.Printf("cap(sl2): %v\n", cap(sl2))
而 string 不支持:
var s string = "123"
sl3 := s[0:1] // 正确
sl4 := s[0:1:2] // 错误,字符串不支持完整切片表达式
完整切片表达式必须满足 0 <= low <= high <= max <= cap(a),a 为底层数组或切片
使用 make 函数构造切片
除了基于数组构造切片外,还可以使用 make 函数动态构造切片:
make([]T, size, cap)
sl1 := make([]int, 4, 16) // size = 4,cap = 16
切片的本质
切片的本质实际上就是把底层数组做了一层封装,包含三个属性:
- 底层数组的指针
- size
- cap
例如,假设有一个数组 a := [8]int{0, 1, 2, 3, 4, 5, 6, 7},切片 s1 := a[0:5]:
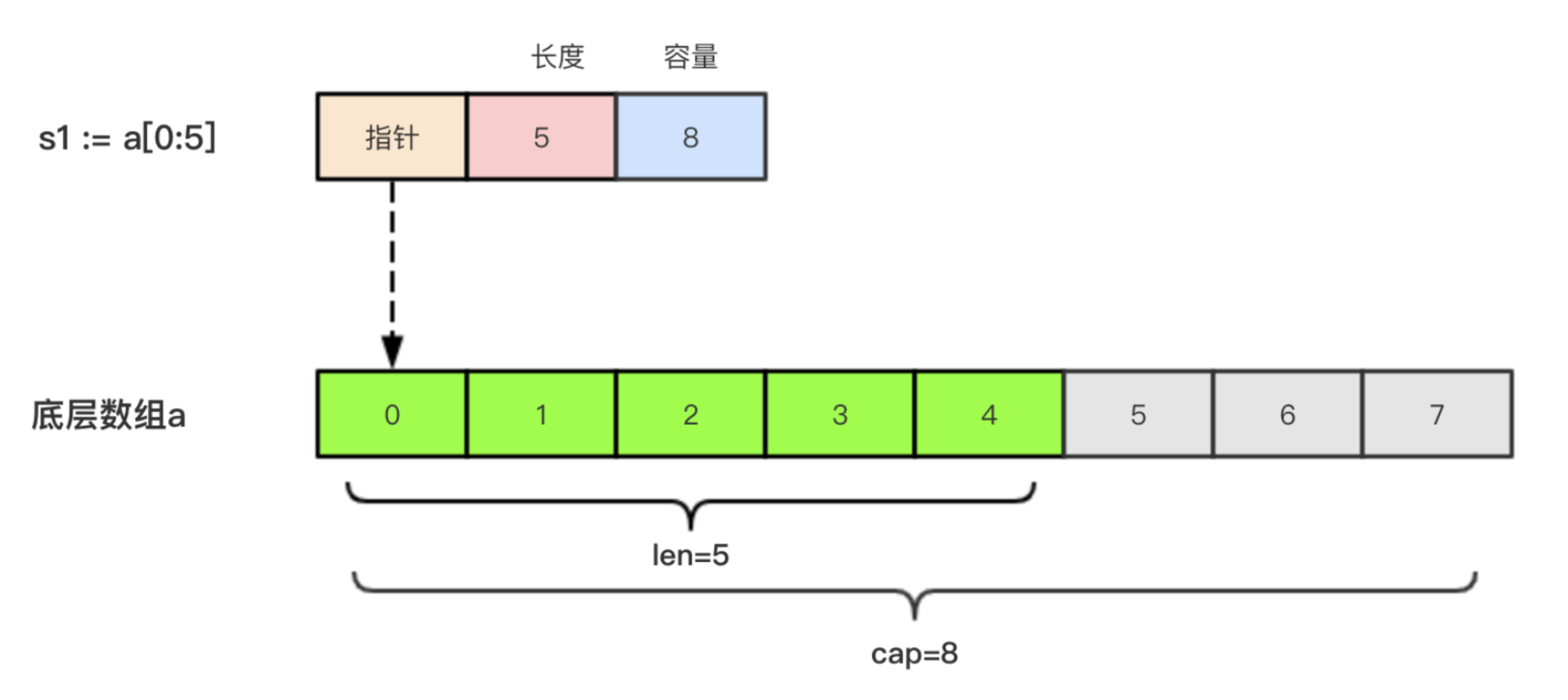
切片 s2 := a[3:6]:
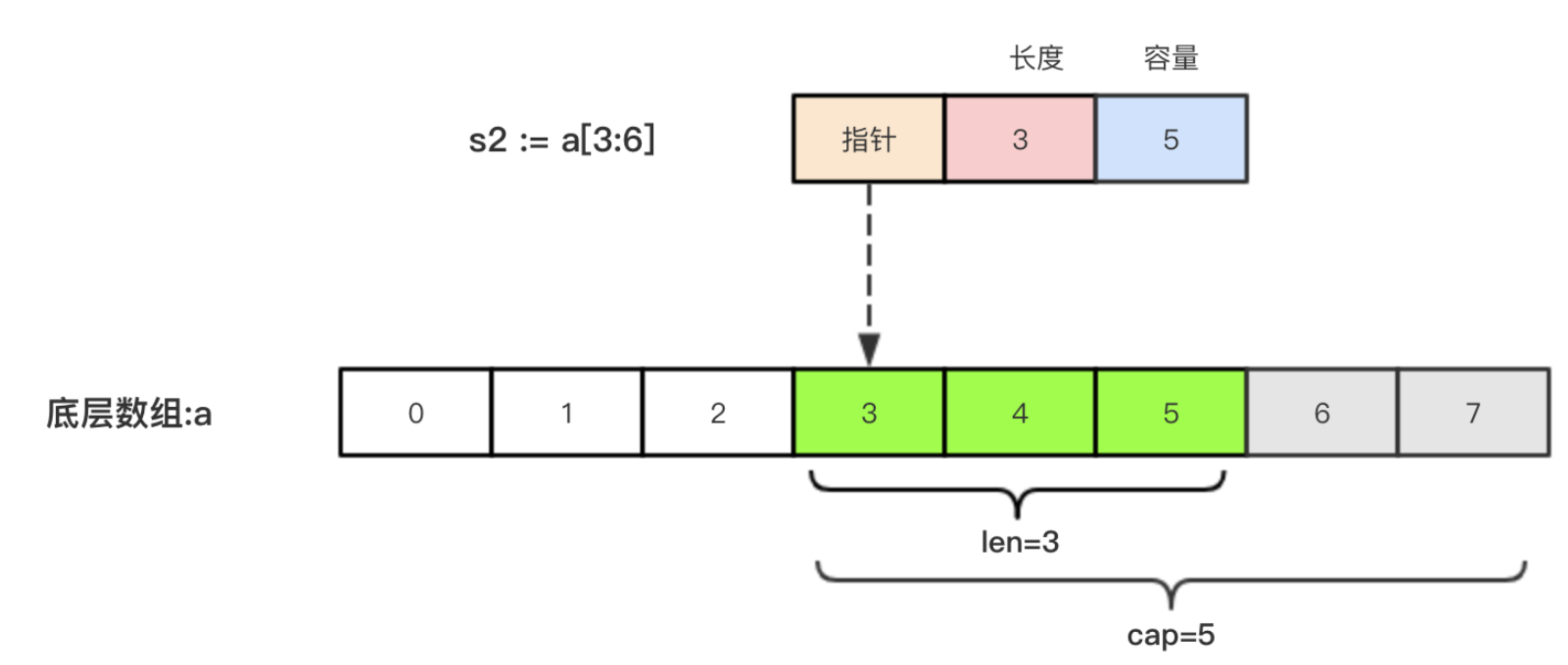
这样应该可以理解为什么容量分别为 8、5 了
判断切片是否为空
判断切片是否为空的唯一方式:len(s) == 0
不能 使用 s == nil 判断:
sl := []int{}
fmt.Printf("(sl == nil): %v\n", (sl == nil)) // false
fmt.Printf("(len(sl) == 0): %v\n", (len(sl) == 0)) // true
// 但是 sl 实际上确实为空
此外,切片之间也 不能 相互比较:

如果要比较两个切片,可以遍历两个切片来比较
切片的拷贝
切片的拷贝可以理解为「浅拷贝」,也就是说:拷贝后的切片与源切片 共享同一个底层数组!
这也许会产生意想不到的结果:
sl0 := []int{1, 2, 3, 4}
sl1 := sl0 // 引用赋值
fmt.Printf("sl1[0]: %v\n", sl1[0]) // 1
sl0[0] = 666
fmt.Printf("sl1[0]: %v\n", sl1[0]) // 666
因此,需要考虑业务需求,来选择是否需要深拷贝
深拷贝切片需要用到 copy 函数:
copy(destSlice, srcSlice []T)
对于上面的示例,可以修改成:
sl0 := []int{1, 2, 3, 4}
sl1 := make([]int, 4) // size == cap == 4,可以访问 sl1[0]
copy(sl1, sl0)
fmt.Printf("sl1[0]: %v\n", sl1[0]) // 1
sl0[0] = 666
fmt.Printf("sl1[0]: %v\n", sl1[0]) // 1
注意,当目的切片没有足够空间(这里是 size,不是 cap)时,copy 不会拷贝后续的部分,并不会抛异常,这与 C++ 是不同的
append 方法
append 方法可以用于向切片添加元素:
func append(slice []Type, elems ...Type) []Type
可以一次添加一个元素或多个元素,也可以直接添加一个切片:
sl0 := []int{5, 6, 7, 8}
// sl1 := []int{} // 没有必要初始化
var sl1 []int // 直接声明即可
sl1 = append(sl1, 1)
sl1 = append(sl1, 2, 3, 4)
sl1 = append(sl1, sl0...) // 注意 ...
fmt.Printf("sl1: %v\n", sl1)
为啥每次都要重新赋值,直接写 append(sl1, 1) 不行吗?
主要原因还是因为切片的扩容机制决定的
append 时,若底层数组的 cap 不足以容纳新的元素时,切片会按照一定「策略」扩容,这会改变切片指向的底层数组
由于切片的扩容机制,append 实际上每次返回的是一个新的切片(底层数组可能相同)
因此,每次 append 都要用原变量来接受 append 的返回值
为什么 nil 切片可以直接 append?
因为 nil 切片可以通过 append 来扩容(申请一块内存),最终变成一个正常的 slice
扩容策略
来看一下 Go 切片扩容的源码:
newcap := oldCap
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < newLen {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = newLen
}
}
}
- 先假设扩容后的 newcap 为 doublecap,即原 cap 的 2 倍
- 如果 append 后,切片的长度比 doublecap 还大,说明扩容 2 倍不能满足需求,直接使用 append 后的切片长度作为 newcap
sl0 := []int{1, 2, 3} sl0 = append(sl0, 4, 5, 6, 7, 8, 9, 10) fmt.Printf("len(sl0): %v\n", len(sl0)) // 10 fmt.Printf("cap(sl0): %v\n", cap(sl0)) // 10 - 否则,说明扩容 2 倍能满足需求,但不能直接使用 doublecap,因为要减少无效内存占用(如果本身的容量已经很大,扩容 2 倍很有可能浪费内存),判断原容量与 threshold 的大小关系:
- 如果比 threshold 小,说明原来的 cap 还比较小,可以接受扩容 2 倍带来的潜在内存浪费
- 否则,计算 newcap,以平滑地过渡从 2 倍增长到 1.25 倍增长的情况。循环将 newcap 增加到一个新值,该值介于两者之间。
- 如果计算过程中,newcap <= 0,说明计算溢出了,为了安全起见,将 newcap 设置为新的长度(newLen)。
此外,切片扩容策略还有可能与切片元素类型有关,例如,int 和 string 类型的处理方式就不一样
2024.3.13 补充:
切片扩容还涉及到了 内存对齐,主要是为了保证 CPU 的访问性能
// Specialize for common values of et.Size. // For 1 we don't need any division/multiplication. // For goarch.PtrSize, compiler will optimize division/multiplication into a shift by a constant. // For powers of 2, use a variable shift. switch { case et.Size_ == 1: case et.Size_ == goarch.PtrSize: case isPowerOfTwo(et.Size_): default: }因此,扩容后的实际容量还与与切片元素类型有关
测试
示例 0
func test0() {
a1 := [7]int{1, 2, 3, 4, 5, 6, 7}
fmt.Printf("a1: %v (len: %d, cap: %d)\n",
a1, len(a1), cap(a1))
s9 := a1[1:4]
fmt.Printf("s9: %v (len: %d, cap: %d)\n",
s9, len(s9), cap(s9))
for i := 1; i <= 5; i++ {
s9 = append(s9, i)
fmt.Printf("s9(%d): %v (len: %d, cap: %d)\n",
i, s9, len(s9), cap(s9))
}
fmt.Printf("a1: %v (len: %d, cap: %d)\n",
a1, len(a1), cap(a1)) // 想清楚这一行的输出
fmt.Println()
}
输出:
a1: [1 2 3 4 5 6 7] (len: 7, cap: 7)
s9: [2 3 4] (len: 3, cap: 6)
s9(1): [2 3 4 1] (len: 4, cap: 6) # 在这里对 a1 修改
s9(2): [2 3 4 1 2] (len: 5, cap: 6) # 在这里对 a1 修改
s9(3): [2 3 4 1 2 3] (len: 6, cap: 6) # 在这里对 a1 修改
s9(4): [2 3 4 1 2 3 4] (len: 7, cap: 12)
s9(5): [2 3 4 1 2 3 4 5] (len: 8, cap: 12)
a1: [1 2 3 4 1 2 3] (len: 7, cap: 7) # s9 的底层数组就是 a1,对 s9 的修改会反映到 a1 上
因此,在必要的时候使用深拷贝
示例 1
func test2() {
// 示例1。
s6 := make([]int, 0)
fmt.Printf("The capacity of s6: %d\n", cap(s6))
for i := 1; i <= 5; i++ {
s6 = append(s6, i)
fmt.Printf("s6(%d): len: %d, cap: %d\n", i, len(s6), cap(s6))
}
fmt.Println()
// 示例2。
s7 := make([]int, 1024)
fmt.Printf("The capacity of s7: %d\n", cap(s7))
s7e1 := append(s7, make([]int, 200)...)
fmt.Printf("s7e1: len: %d, cap: %d\n", len(s7e1), cap(s7e1))
s7e2 := append(s7, make([]int, 400)...)
fmt.Printf("s7e2: len: %d, cap: %d\n", len(s7e2), cap(s7e2))
s7e3 := append(s7, make([]int, 600)...)
fmt.Printf("s7e3: len: %d, cap: %d\n", len(s7e3), cap(s7e3))
fmt.Println()
// 示例3。
s8 := make([]int, 10)
fmt.Printf("The capacity of s8: %d\n", cap(s8))
s8a := append(s8, make([]int, 11)...)
fmt.Printf("s8a: len: %d, cap: %d\n", len(s8a), cap(s8a))
s8b := append(s8a, make([]int, 23)...)
fmt.Printf("s8b: len: %d, cap: %d\n", len(s8b), cap(s8b))
s8c := append(s8b, make([]int, 45)...)
fmt.Printf("s8c: len: %d, cap: %d\n", len(s8c), cap(s8c))
}
输出:
The capacity of s6: 0
s6(1): len: 1, cap: 1
s6(2): len: 2, cap: 2
s6(3): len: 3, cap: 4
s6(4): len: 4, cap: 4
s6(5): len: 5, cap: 8
The capacity of s7: 1024
s7e1: len: 1224, cap: 1536 # 理论计算结果为 1024 + (1024 + 256 * 3) / 4 = 1472,但却是 1024 的 1.5 倍,这也是内存对齐的结果
s7e2: len: 1424, cap: 1536
s7e3: len: 1624, cap: 2048
The capacity of s8: 10
s8a: len: 21, cap: 22
s8b: len: 44, cap: 44
s8c: len: 89, cap: 96 # 很好的体现了扩容策略中的「内存对齐」
删除切片的元素
Go 没有直接提供删除切片元素的方法,但是可以使用 append 来达到相同效果:
sl0 := []int{1, 2, 3, 4, 5, 6}
sl0 = append(sl0[0:1], sl0[2:]...) // 删除 idx = 1 的元素
fmt.Printf("sl0: %v\n", sl0) // 1 3 4 5 6
传 slice 和 slice 指针有什么区别
Go 所有的函数传递,都是 值传递,没有引用传递
因此,在 Go 中:
- 传一个对象本身,在函数调用者看来,是不希望对象被函数改变的
- 传一个对象的指针,在函数调用者看来,是允许对象被函数改变的
对于 slice,也是适用这个规则,因为 slice 实际上是一个复合类型
示例 0
func myAppend(s []int) {
s = append(s, 100)
}
func main() {
s := []int{1, 1, 1}
myAppend(s)
fmt.Printf("s: %v\n", s)
}
输出:
s: [1 1 1]
可以看到,myAppend 对 slice 的改变,并没有反映到原 slice
正确的写法有两种:
// 返回修改后的对象
func myAppend(s []int) []int {
s = append(s, 100)
return s
}
// 直接传递指针
func myAppendPtr(s *[]int) {
*s = append(*s, 100)
}
func main() {
s := []int{1, 1, 1}
s = myAppend(s)
fmt.Println(s)
myAppendPtr(&s)
fmt.Println(s)
}
当然,你可能对接下来的示例有些疑惑:
示例 1
// 传值
func foo(s []int) {
s[len(s) - 1] = 114514
}
func main() {
s := []int{1, 2, 3}
foo(s)
fmt.Printf("s: %v\n", s)
}
输出:
s: [1 2 114514]
可以发现,即使传递的是 slice 副本,还是被修改了,似乎违背了 Go 只有值传递的事实,这是为什么?
实际上,虽然传递的是 slice 的副本,但是 底层数组还是同一个,通过 [] 运算符修改,实际上操作的还是底层数组
例如:
type Foo struct {
A *int
}
func Bar(f Foo) {
*f.A = 114514
}
func main() {
f := Foo{A: new(int)}
*f.A = 1
Bar(f) // 传的是 f 的副本
fmt.Printf("f.A: %v\n", *f.A) // 114514
}
这个示例的本质与示例 1 是一致的
因此,当直接用切片作为函数参数时,可以改变切片的元素,不能改变切片本身
如果想要在一个函数中修改 slice 本身,那么建议 传递 slice 的指针