Linux 线程概念
在 Linux 系统中,进程实际上是由线程来实现的,没有独立的、与线程完全分离的进程实体。实际上,进程可以被视为线程的容器,线程是进程的执行单元。
在传统的操作系统中,进程被认为是独立的实体,具有独立的地址空间、文件描述符、资源等。而在 Linux 中,进程与线程之间没有明显的差异,线程之间共享同一进程的资源,包括内存空间、文件描述符、信号处理等。每个进程至少有一个线程,即主线程,其他线程都是主线程的衍生。
Linux 采用了 轻量级进程(LWP,Lightweight Process)模型,将线程作为进程的基本执行单元 。通过在进程内创建和管理线程,实现并发执行和资源共享。
因此,在 Linux 中,进程只是线程的一个容器,用于提供资源隔离和管理的框架 。每个进程都有一个唯一的进程标识符(PID),用于标识该进程及其线程组。线程之间的切换和调度是通过操作系统内核来完成的 ,进程和线程之间没有明确的边界。
内核级线程与用户级线程
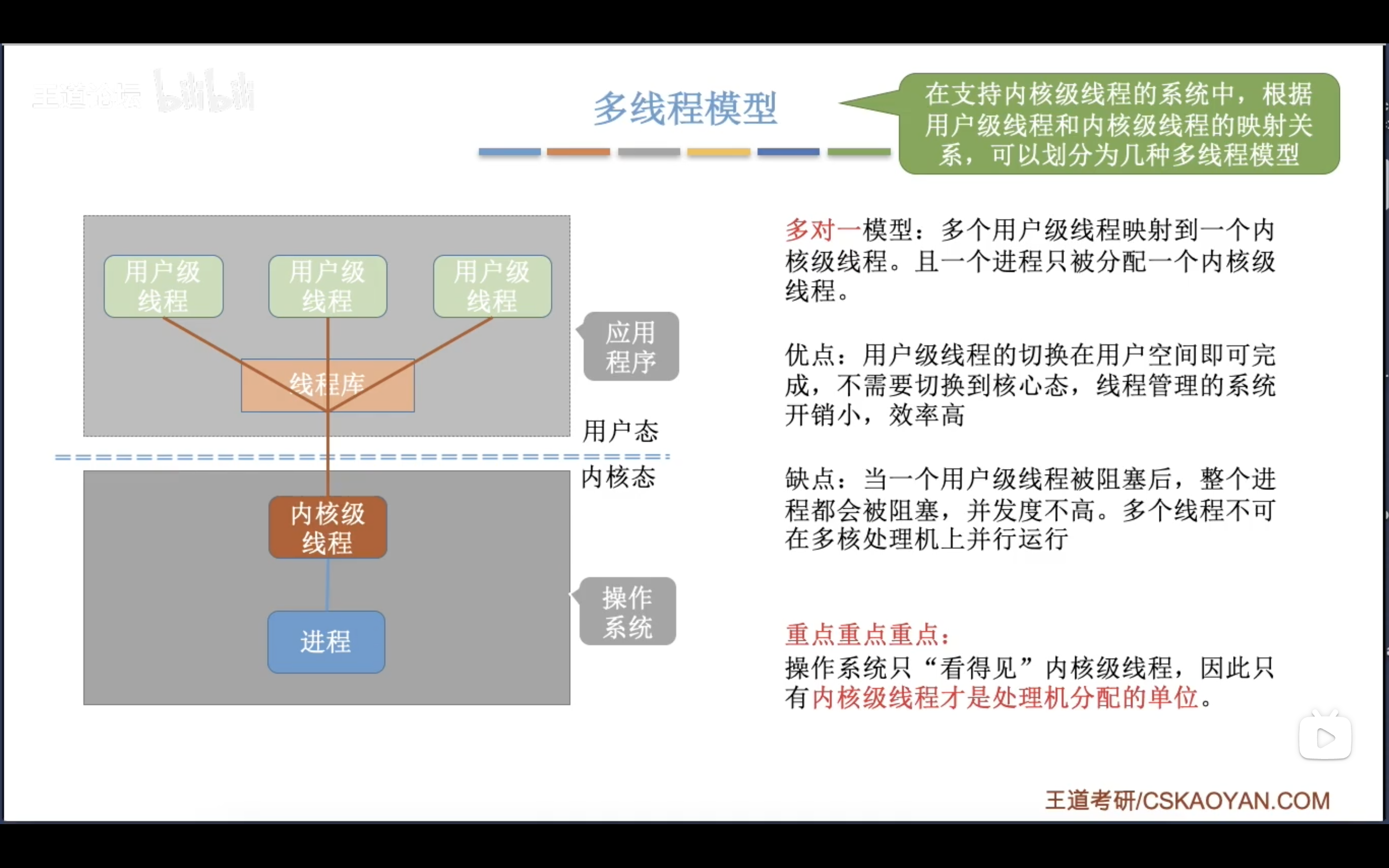
内核级线程:内核级线程是由操作系统内核直接支持和管理的线程。在这种模型中,线程的创建、调度和管理都由操作系统内核 完成。每个内核级线程都有独立的内核栈和内核上下文,由内核进行调度和切换。在内核级线程模型中,多个线程可以并发执行在多个处理器核心上,充分利用多核资源。
用户级线程:用户级线程是在用户空间实现的线程。用户级线程的 创建、调度和管理由用户态的线程库或运行时库完成,而操作系统对这些线程是无感知的 。在 单个内核级线程 上运行的若干个用户级线程,由用户态的调度算法决定线程的切换和执行,不需要操作系统内核的介入,所以线程的切换开销较小。
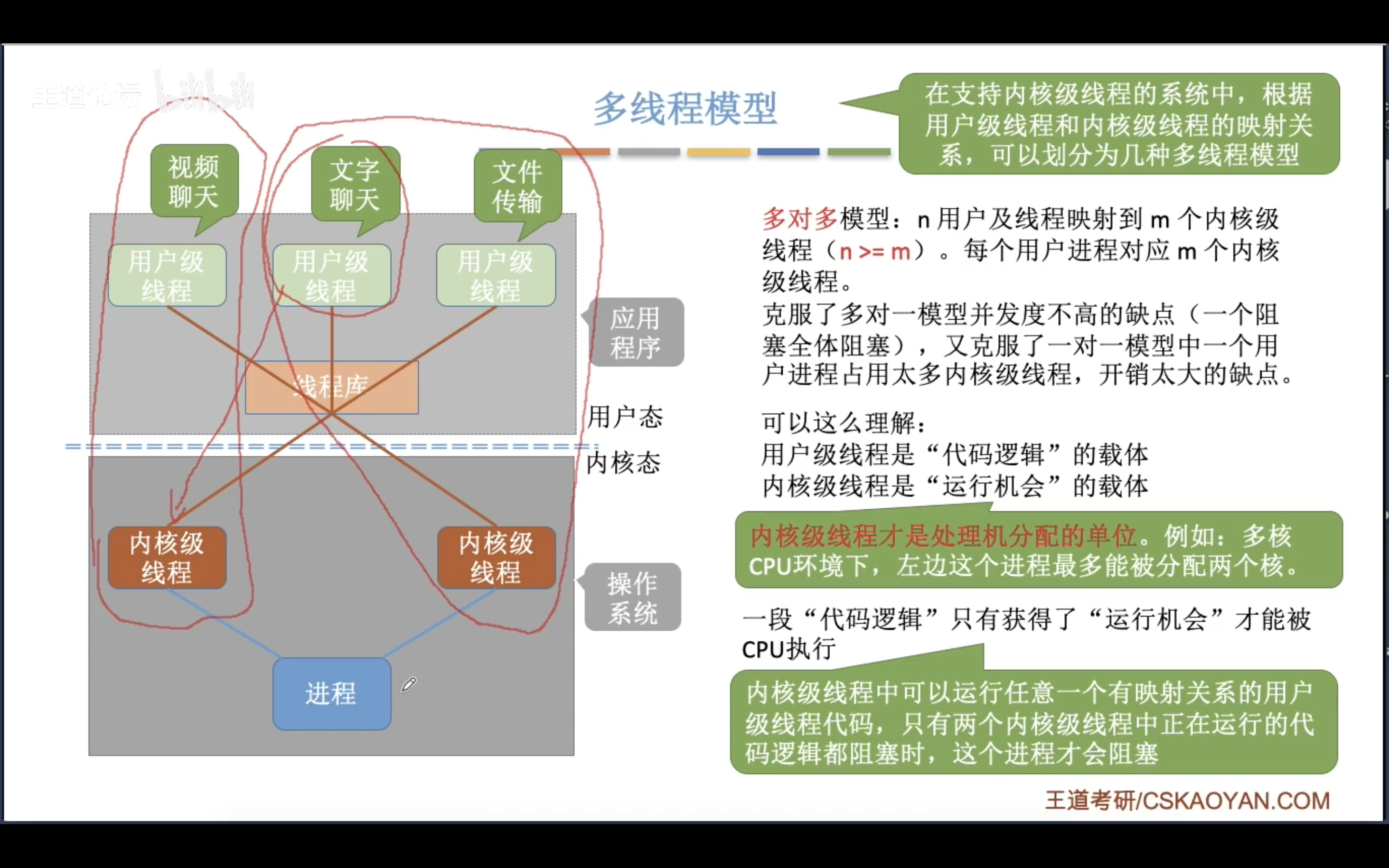
接下来的内容讲的都是内核级线程
线程的优点
- 线程的创建和销毁成本较低
- 线程的切换成本低
- 线程占用的资源少
- 对于
计算密集型的程序而言,使用线程可以将计算部分分配到多个线程执行,提高效率 - 对于
IO 密集型的程序而言,使用线程可以将 IO 操作重叠,等待多种 IO 操作
线程的缺点
- 潜在的性能损失:如果开辟的线程数量大于了计算机可用的处理器数量,那么会产生额外的同步和调度开销
- 健壮性降低:编写多线程程序时,往往会因为数据的不恰当访问而导致数据不一致问题,线程之间是缺乏保护的
- 缺少访问控制:进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响
- 编写难度高:调试一个多线程程序往往比单线程程序困难
线程异常
对于一个多线程程序,如果某一个线程出现异常,崩溃,那么对应的进程也会崩溃,其它线程也会跟着退出
例如:
void *thread0(void *arg)
{
int loops = 3;
while (loops--)
{
printf("Thread0 is running...\n");
sleep(1);
}
raise(SIGABRT); // 线程 1 抛出 SIGABRT
return NULL;
}
void *thread1(void *arg)
{
while (1) // 死循环
{
printf("Thread1 is running...\n");
sleep(1);
}
}
int main(void)
{
pthread_t tid0, tid1;
pthread_create(&tid1, NULL, thread1, NULL); // 创建线程 1
pthread_create(&tid0, NULL, thread0, NULL); // 创建线程 0
sleep(10); // 等待 thread 0 抛出 SIGABRT
printf("Main thread is quitting...\n");
return 0;
}
输出:
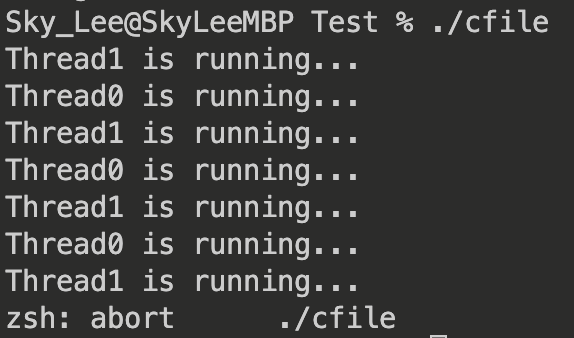
可以看到,当 thread0 抛出异常后,thread1 和 主线程 都退出了
线程与进程
在一开始介绍线程概念的时候,已经讲到了线程与进程的关系,这里再总结一下:
-
进程是资源分配的基本单位,线程是调度的基本单位
-
线程共享进程的资源,包括 内存空间、文件描述符、每种 信号处理的方式 等
-
线程也有自己独享的资源:
- 线程 ID
- 一组寄存器(用于保存上下文数据和调度)
- 栈区(线程的临时数据)
- errno
- 屏蔽信号集
- 调度优先级
根据「进程是线程的容器」这句话理解二者的关系可能更加容易
进程与线程的本质区别?
是否共享内存空间,是进程与线程的本质区别,Linux 并不区分进程与线程,线程对于内核来说,不过是一个共享特定资源的进程而已
Linux 线程控制
创建线程
可以使用 pthread_create 来创建一个线程
原型如下:
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine)(void *), void *arg);
参数说明:
thread:指向pthread_t类型的 指针,用于存储新创建线程的标识符。attr:指向pthread_attr_t类型的指针,用于指定新线程的属性。可以传入NULL使用默认属性。start_routine:指向线程函数的指针,该函数在新线程中运行。函数的返回值和参数类型都必须是void *类型。arg:传递给线程函数的参数。
返回值:
- 创建成功返回 0
- 创建失败返回一个错误码
pthread_create 函数调用成功后,将创建一个新的线程,并将其标识符存储在 thread 参数指向的位置。新线程将立即开始执行 start_routine 指向的函数,并将 arg 作为参数传递给该函数。
新线程在创建后独立运行,与创建它的线程(通常是主线程)并发执行 。
注意: pthread_create 函数仅仅是创建了一个新线程,并 不会等待新线程的结束 。
如何等待?下文有介绍
线程 ID
前面提到,可以通过 pthread_create 的第一个参数获取创建的子线程的 ID
此外,在一个线程内,也可以通过 pthread_self 来获取自己的线程 ID
例如:
void *thread0(void *arg)
{
printf("[%d]Thread0: Thread0's tid: %ld\n", getpid(), pthread_self());
sleep(30);
return NULL;
}
int main(void)
{
pthread_t tid0;
if(pthread_create(&tid0, NULL, thread0, NULL) != 0)
{
perror("Create thread error!\n");
return -1;
}
sleep(30);
printf("[%d]Main thread: Main thread's tid: %ld\n", getpid(), pthread_self());
printf("[%d]Main thread: Thread0's tid: %ld\n", getpid(), tid0);
return 0;
}
输出:

可以看到:
- 两种方式获取的线程 ID 相同
- 主线程与 thread0 的线程 ID 不同
但这种方式获取的是「用户级」的线程 ID,而不是「内核级」的线程 ID
如何获取内核级线程 ID 呢?使用 ps -aL
为了观察内核级线程 ID,我们让程序在后台运行,并输入终端指令:
ps -aL|head -1 && ps -aL|grep test|grep -v grep
观察到如下结果:
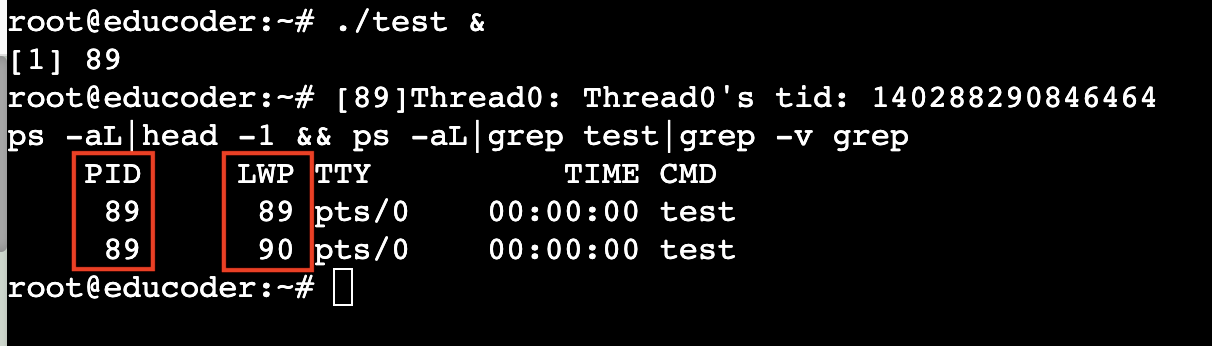
其中,LWP 就是所谓的「内核级」线程 ID
实际上,「内核级」线程 ID 就是「轻量级线程号」,OS 调度时,是根据 LWP 来调度,分配资源是根据 PID 来分配
线程终止
在 Linux 中,一共有三种方式使一个线程终止:
- 从线程函数(就是传给 pthread_create 的函数)中 return
- 调用
pthread_exit - 一个线程可以调用
pthread_cancel来终止另一个线程
pthread_exit
pthread_exit 是一个线程库函数,用于在线程中显式地退出线程。它允许线程提前结束执行,并返回一个指定的退出状态值。
函数原型如下:
void pthread_exit(void *retval);
参数 retval 是一个指向线程退出状态的指针。线程退出状态可以是任何指针类型的值,用于传递线程结束时的信息。
当调用 pthread_exit 函数时,当前线程会立即终止,并将 retval 的值作为线程的退出状态。这个退出状态可以由其他线程使用 pthread_join 函数获取(后文会讲)。
pthread_cancel
pthread_cancel 是一个线程库函数,用于向目标线程发送取消请求,以「请求」目标线程终止执行。
函数原型如下:
int pthread_cancel(pthread_t thread);
参数 thread 是目标线程的线程标识符
当调用 pthread_cancel 函数时,它会发送一个取消请求给目标线程。目标线程可以通过以下几种方式响应取消请求:
- 线程忽略取消请求:线程可以选择忽略取消请求,不做任何响应。
- 线程立即取消:线程可以立即取消,即终止当前的线程执行。
- 线程延迟取消:线程可以在取消点(cancellation point)处取消,即等待到达一个预定的取消点后再终止执行。取消点是指线程执行的某个特定位置,例如线程调用了阻塞的 I/O 操作或者阻塞的系统调用时。
注意: 取消请求是异步的, 目标线程不一定会立即响应取消请求 。另外,要使 pthread_cancel 函数生效,目标线程必须设置为可取消状态,可以通过 pthread_setcancelstate 函数进行设置。
线程等待
为什么要线程等待?
- 如果一个线程退出,它的空间不会释放,而是继续留在进程空间内
- 线程退出后,如果再创建一个新的线程,不会复用之前退出的线程的地址空间
pthread_join
pthread_join 是一个线程库函数,用于等待指定的线程终止,并获取其返回值。
函数原型如下:
int pthread_join(pthread_t thread, void **retval);
参数 thread 是要等待的目标线程的线程标识符
参数 retval 是一个指向指针的指针,用于接收目标线程的返回值。目标线程的返回值通过 pthread_exit 函数传递。
当调用 pthread_join 函数时, 它会阻塞当前线程 ,直到目标线程终止。如果目标线程已经终止,那么 pthread_join 函数会立即返回。如果目标线程尚未终止,当前线程将被阻塞,直到目标线程终止为止。
一旦目标线程终止,它的返回值将被存储在 retval 指向的内存位置中。如果不关心目标线程的返回值,可以将 retval 参数设置为 NULL。
分离线程
在默认情况下,一个新创建的线程是可以 join 的,创建该线程的线程需要进行 join 操作,否则无法回收相关资源
然而,根据前文提到的,当调用 pthread_join 函数时, 它会阻塞当前线程 ,直到目标线程终止。因此,join 操作是有代价的
如果不关心线程的返回值,join 就成了一种负担,有没有什么方法避免 join 带来的负担,同时可以回收线程的资源呢?
pthread_detach
pthread_detach 是一个线程库函数,用于将一个线程标记为“分离状态”,以指示 线程终止后自动释放其资源。
函数原型如下:
int pthread_detach(pthread_t thread);
参数 thread 是要分离的目标线程的线程标识符
调用 pthread_detach 函数将目标线程标记为「分离状态」,这意味着一旦目标线程终止,它的资源将被自动释放,而不需要通过调用 pthread_join 来等待目标线程的终止和获取返回值。
注意: 分离状态的线程无法被等待。也就是说,pthread_join 和 pthread_detach 是互斥的。因此,一旦线程被标记为「分离状态」,就不能再调用 pthread_join 函数等待它的终止。
例如,如果我们同时对一个线程进行等待和分离操作:
void* thread_run(void *arg)
{
printf("%s\n", (char*)(arg));
pthread_detach(pthread_self()); // 线程自己分离
return NULL;
}
int main(void)
{
pthread_t tid;
if((pthread_create(&tid, NULL, thread_run, "Thread is running...")) != 0)
{
perror("Create thread error!\n");
return 1;
}
sleep(1); // 等待线程分离
if(pthread_join(tid, NULL) == 0) // 一个线程不能既是 joinable 又是分离的,所以 join 会失败
printf("Join success!\n");
else printf("Join failed!\n");
return 0;
}
输出:

可以看到,加入是失败了的
实例
// return
void *thread1(void *arg)
{
printf("Thread1 is about returning...\n");
int *state = (int *)malloc(sizeof(int));
*state = 1;
return (void *)state;
}
// exit
void *thread2(void *arg)
{
printf("Thread2 is about exitting...\n");
int *state = (int *)malloc(sizeof(int));
*state = 2;
pthread_exit((void *)state); // 传递的必须是堆区或者全局开辟的
}
// cancel
void *thread3(void *arg)
{
while (1)
{
printf("Thread3 is running...\n");
sleep(1);
}
return NULL;
}
// detach
int flag = 0; // 标记 thread 4 的退出状态
void* thread4(void *arg)
{
sleep(3); // 给 main thread 时间来分离
int loops = 3;
while (loops--)
{
printf("Thread4 is running...\n");
sleep(1);
}
printf("Thread4 is about returning...\n");
flag = 1;
return NULL;
}
int main(void)
{
pthread_t tid;
void *state; // 线程返回的状态
// 创建 Thread 1
pthread_create(&tid, NULL, thread1, NULL);
pthread_join(tid, &state);
printf("Thread1[%X] return value: %d\n", tid, *(int *)state);
free(state);
// 创建 Thread 2
pthread_create(&tid, NULL, thread2, NULL);
pthread_join(tid, &state);
printf("Thread2[%X] exit code: %d\n", tid, *(int *)state);
free(state);
// 创建 Thread 3
pthread_create(&tid, NULL, thread3, NULL);
sleep(3);
printf("Main thread is canceling thread3[%X]...\n", tid);
pthread_cancel(tid);
pthread_join(tid, &state);
if (state == PTHREAD_CANCELED)
printf("Thread3[%X] was calceled.\n", tid);
else
printf("Thread3[%X] return NULL\n", tid);
// 创建 Thread 4
pthread_create(&tid, NULL, thread4, NULL);
pthread_detach(&tid); // 快速分离线程 4,防止线程 4 已经退出,而主线程还没分离线程 4,导致资源无法回收
printf("Main thread is detaching thread4[%X] ...\n", tid);
while (!flag)
{
printf("Main thread is running...\n");
sleep(1);
}
printf("Thread 4 has returned, main thread is about exitting...\n");
return 0;
}
输出:
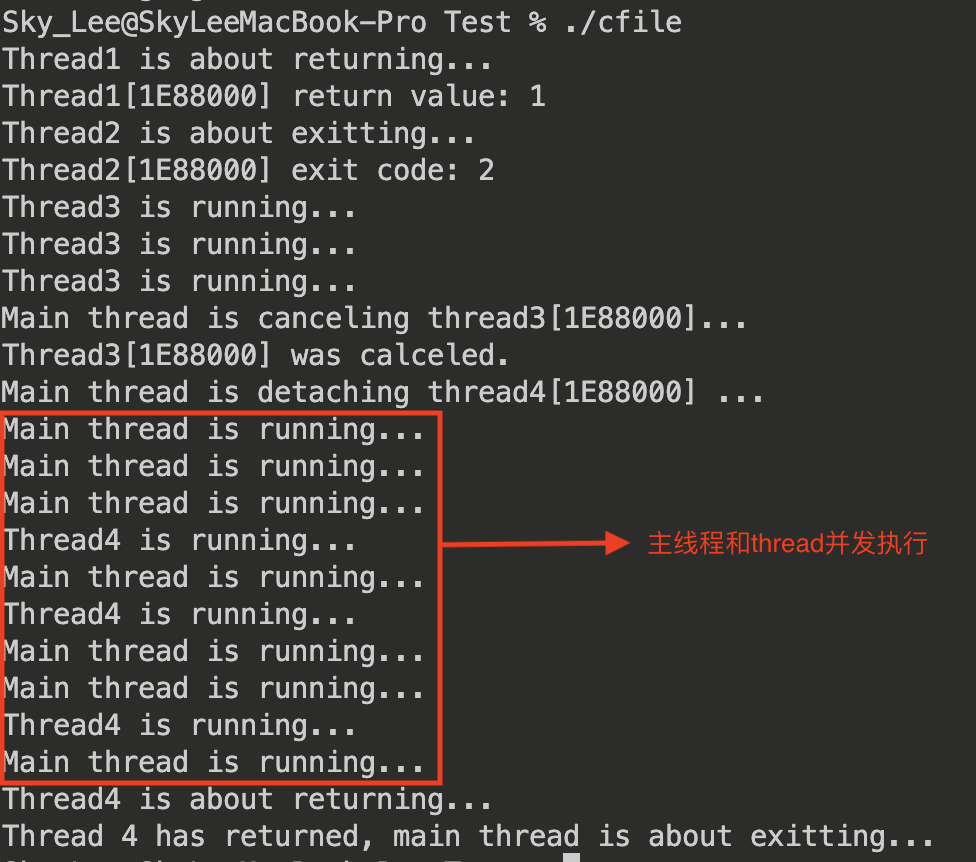
Linux 线程互斥
相关概念
- 临界资源:多个线程共享的资源
- 临界区:访问临界资源的代码
- 互斥:保证任意时刻有且仅有一个线程访问临界区
- 原子性:不会被任何调度机制打断的操作
有问题的售票机
先来看一个例子:
int remainTickets = 66;
void* sell(void *arg)
{
const char* curThread = (const char*)(arg);
while (1)
{
if(remainTickets > 0) // 可以卖一张票
{
usleep(1000); // 阻塞 1000 us,模拟较长的计算过程
--remainTickets;
printf("%s: remainTickets: %d\n", curThread, remainTickets);
}
else break;
}
return NULL;
}
int main(void)
{
pthread_t tid0, tid1, tid2, tid3;
pthread_create(&tid0, NULL, sell, "Thread 0");
pthread_create(&tid1, NULL, sell, "Thread 1");
pthread_create(&tid2, NULL, sell, "Thread 2");
pthread_create(&tid3, NULL, sell, "Thread 3");
pthread_join(tid0, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
pthread_join(tid3, NULL);
return 0;
}
某一次运行时的输出:
Sky_Lee@SkyLeeMBP Test % ./cfile
Thread 1: remainTickets: 65
...
Thread 1: remainTickets: 1
Thread 0: remainTickets: -1
Thread 3: remainTickets: -2
Thread 2: remainTickets: 0
Thread 1: remainTickets: -3
神奇的是: remainTickets <= 0 时,线程似乎仍然对 remainTickets 进行了减 1 操作
为什么?
原因就在于没有对临界资源 remainTickets 进行保护
例如,此时 remainTickets == 1 对于某个线程(假设为线程1):
- 判断 if 条件为 true,向下一步执行
- 此时发生了调度,切换到另一个线程(假设为线程2)
- 由于线程 1 没有来得及对 remainTickets 进行减 1 操作,因此,if 条件仍然成立
- 线程 2 对 remainTickets 进行了减 1 操作,此时,
remainTickets == 0 - 调度,切换到线程 1,继续对 remainTickets 进行减 1 操作,此时,
remainTickets == -1
因此,要想避免这种情况,就需要对临界资源保护
那么该如何保护呢?
互斥量(mutex)
在Linux中,互斥量(mutex)是一种用于实现线程同步的机制,用于保护共享资源的访问。它可以确保在任意给定时间只有一个线程可以访问受互斥量保护的代码段或共享资源,以避免并发访问导致的数据竞争和不一致性。
互斥量的主要特性如下:
- 锁定和解锁:互斥量提供了两个主要操作: 锁定(Lock)和解锁(Unlock) 。线程在访问受互斥量保护的代码段或共享资源之前需要获取锁,以确保独占访问。当访问完成后,线程需要释放锁,以允许其他线程获取锁。
- 互斥性:互斥量保证在任意给定时间只有一个线程可以获取到锁。如果一个线程已经持有了互斥锁,其他线程尝试获取锁时将被阻塞,直到该线程释放锁。
有关互斥量的接口
在Linux中,互斥量的实现可以使用pthread_mutex_t数据类型和相关的函数。常用的互斥量操作函数包括:
pthread_mutex_init:初始化互斥量。pthread_mutex_destroy:销毁互斥量。pthread_mutex_lock:获取互斥量的锁定。pthread_mutex_trylock:尝试获取互斥量的锁定,如果获取失败则立即返回。pthread_mutex_unlock:释放互斥量的锁定。
pthread_mutex_init
函数原型:
int pthread_mutex_init(pthread_mutex_t* mutex, const pthread_mutexattr_t* attr);
参数:
mutex:一个指向pthread_mutex_t类型的指针,用于指定要初始化的互斥量。attr:一个指向pthread_mutexattr_t类型的指针,用于指定互斥量的属性。可以将其设置为NULL,表示使用默认属性。
pthread_mutex_init 函数在调用时会为互斥量分配内存,并将其初始化为可用状态。
返回值:
- 如果函数调用成功,返回值为 0,表示初始化互斥锁成功。
- 如果函数调用失败,返回值为非零的错误码,表示初始化互斥锁失败。
注意: 创建互斥量时,一定要用 pthread_mutex_init 初始化
pthread_mutex_lock
函数原型:
int pthread_mutex_lock(pthread_mutex_t *mutex);
参数:
mutex:指向互斥量对象的指针。互斥量用于提供线程之间的互斥访问。
返回值:
- 成功:返回0。
- 失败:返回错误代码。
注意: 可以在不同线程中多次调用pthread_mutex_lock,但要记得每次调用都要对应一个pthread_mutex_unlock。
pthread_mutex_unlock
函数原型:
int pthread_mutex_unlock(pthread_mutex_t *mutex);
参数:
mutex:指向互斥量对象的指针。互斥量用于提供线程之间的互斥访问。
返回值:
- 成功:返回0。
- 失败:返回错误代码。
功能:pthread_mutex_unlock函数用于释放互斥量的锁。它允许其他线程获取该互斥量的锁。
调用pthread_mutex_unlock函数会将互斥量标记为可用状态,允许其他线程获取它。如果当前没有其他线程正在等待获取该互斥量的锁,则互斥量将变为可用状态,否则将允许一个等待的线程获取锁。
注意:
pthread_mutex_unlock函数 应该在持有互斥量锁的线程中调用 ,否则行为是未定义的。- 解锁一个未加锁的互斥量,或 解锁其他线程拥有的互斥量是不正确的,并且可能导致未定义的行为。
pthread_mutex_destroy
函数原型:
int pthread_mutex_destroy(pthread_mutex_t *mutex);
参数:
mutex:指向互斥量对象的指针。互斥量是需要销毁的对象。
返回值:
- 成功:返回0。
- 失败:返回错误代码。
功能:pthread_mutex_destroy函数用于销毁互斥量对象。在不再需要使用互斥量时,应该调用该函数来释放相关资源。
调用pthread_mutex_destroy函数会销毁指定的互斥量对象,并释放相关的资源。在调用该函数之后,对互斥量对象的操作是未定义的。
注意:
- 在调用
pthread_mutex_destroy之前,确保没有任何线程正在使用互斥量,否则会导致未定义的行为。 - 销毁一个已经被其他线程锁定的互斥量是不正确的,并且可能导致未定义的行为。
- 不能对销毁后的互斥量进行上锁,解锁等操作
改进后的售票机
int remainTickets = 100;
pthread_mutex_t mutex; // 互斥量
void* sell(void *arg)
{
const char* curThread = (const char*)(arg);
while (1)
{
pthread_mutex_lock(&mutex);
if(remainTickets > 0) // 可以卖一张票
{
// pthread_mutex_lock(&mutex); // 不能放在这,有可能 if 判断为 True 时发生调度
usleep(1000); // 阻塞 1000 us,模拟较长的计算操作
--remainTickets;
printf("%s: remainTickets: %d\n", curThread, remainTickets);
pthread_mutex_unlock(&mutex); // 确保一个 lock 对应一个 unlock
}
else
{
pthread_mutex_unlock(&mutex); // 确保一个 lock 对应一个 unlock
break;
}
}
return NULL;
}
int main(void)
{
pthread_mutex_init(&mutex, NULL);
pthread_t tid0, tid1, tid2, tid3;
pthread_create(&tid0, NULL, sell, "Thread 0");
pthread_create(&tid1, NULL, sell, "Thread 1");
pthread_create(&tid2, NULL, sell, "Thread 2");
pthread_create(&tid3, NULL, sell, "Thread 3");
pthread_join(tid0, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
pthread_join(tid3, NULL);
pthread_mutex_destroy(&mutex);
return 0;
}
互斥锁实现原理
pthread_mutex_lock 和 pthread_mutex_unlock 对应了下面的伪代码 lock 和 unlock
bool locked = false; // 初始化为未锁定
lock()
{
while(1) // 防止伪唤醒
{
if(!locked)
{
locked = true;
return ;
}
else 挂起等待;
}
}
unlock()
{
locked = false;
唤醒等待锁的进程;
return ;
}
可以发现,上锁时,先判断锁是否可用,如果不可用,会将线程 挂起等待 ,让出时间片,直到锁可用
lock 和 unlock 操作必须是原子操作,不允许中断,因为如果不是原子操作,允许发生调度,可能会导致数据不一致问题,使锁的状态混乱
由于互斥锁没有忙等待,因此适用于 持锁时间长 的操作
自旋锁
自旋锁(spin lock)与互斥锁一样,用于保护共享资源的并发访问。但与互斥锁不同,自旋锁 不会使线程进入睡眠状态,而是 通过不断忙等(自旋)的方式来尝试获取锁 。当一个线程发现自旋锁已经被其他线程占用时,它会一直在一个循环中自旋,直到锁被释放。
特点:
- 自旋锁的加锁和解锁过程是原子的,不会被其他线程打断。
- 自旋锁适用于多核处理器,因为在自旋等待期间,线程会占用一个 CPU 核心进行自旋操作。
自旋锁的使用步骤与互斥锁大致相同:
- 初始化自旋锁。
- 在需要保护的共享资源访问之前,使用自旋锁的加锁操作尝试获取锁。
- 如果获取锁成功,则进入临界区,访问共享资源。
- 访问完成后,使用自旋锁的解锁操作释放锁。
实现原理
每把自旋锁都有一个 bool 类型的变量 available,用于标记这把锁是否可用
pthread_spin_lock 和 pthread_spin_unlock 对应了下面的 acquire 和 release:
bool available;
acquire()
{
while(!available); // 循环检查锁的状态,忙等
available = false;
}
release()
{
available = true;
}
acquire 和 release 操作必须是原子操作,不允许中断,因为如果不是原子操作,允许发生调度,可能会导致 available 的数据不一致问题,使锁的状态混乱
自旋锁的最大缺点就是忙等待,当有一个线程在临界区中,任何其他线程在进入临界区时必须调用 acquire,自旋等待锁,直到可用。
但如果线程对临界区的访问很快,那么它将很快释放锁,忙等待的代价就很小,甚至 小于线程切换的代价
因此,自旋锁适用于:处理器资源不紧张以及持锁时间非常短的情况
可重入与线程安全
概念
重入:同一个函数被不同的执行流调用,当前一个流程还没有执行完,就有其他的执行流再次进入
可重入(Reentrancy),也称为可重入性或递归性,是指一个函数或代码段在被多个线程或进程同时调用时能够正确地执行而不会出现不一致或意外的结果。
线程安全(Thread Safety)是指在多线程环境下,能够保证共享资源或数据结构在并发访问时的正确性和一致性。具体来说,线程安全的代码能够在 多个线程同时访问 共享资源时,正确地完成所需的操作,而不会产生不可预期的结果或导致数据损坏
常见线程不安全情况
- 不保护共享变量的函数
- 返回静态变量指针的函数
- 调用线程不安全的函数
常见线程安全情况
- 对共享变量只读,不修改的函数
- 类的接口是原子操作
- 多个线程之间任意切换,不会产生二义性的函数
常见不可重入情况
- 使用了 malloc/free 的函数,因为 malloc/free 使用全局链表管理堆
- 使用了标准库 IO 操作的函数
常见可重入情况
- 使用局部变量,不使用全局变量、静态变量
- 不使用 malloc/free
- 不使用标准 IO 操作
- 不调用 不可重入函数
线程安全与可重入的联系与区别
- 可重入函数一定线程安全
- 线程安全的函数不一定可重入
怎么理解?
对于可重入函数,其保证了多个线程同时调用时,不会出现二义性,这肯定是线程安全的
可重入函数在同一时间只会影响局部变量或者线程私有数据,不会修改全局变量或者共享数据。
而线程安全的函数是可以修改全局变量或者共享数据的,只要对临界资源进行保护即可(例如使用互斥锁),因此,线程安全的函数不一定可重入
死锁
死锁是指在一组进程中的各个进程均占有不会释放的资源,但因 互相申请 被其他进程所占用不会释放的资源而处于的一种 永久等待 状态。
例如:
pthread_mutex_t mutex0, mutex1;
void* thread0(void *arg)
{
printf("Now thread0 is running...\n");
pthread_mutex_lock(&mutex0); // 获取互斥锁 0
printf("Thread0 has got mutex0.\n");
sleep(3); // 模拟耗时操作
pthread_mutex_lock(&mutex1); // 获取互斥锁 1
printf("Thread0 has got mutex1.\n");
pthread_mutex_unlock(&mutex1);
pthread_mutex_unlock(&mutex0);
return NULL;
}
void* thread1(void *arg)
{
printf("Now thread1 is running...\n");
pthread_mutex_lock(&mutex1); // 获取互斥锁 1
printf("Thread1 has got mutex1.\n");
sleep(3); // 模拟耗时操作
pthread_mutex_lock(&mutex0); // 获取互斥锁 0
printf("Thread1 has got mutex0.\n");
pthread_mutex_unlock(&mutex0);
pthread_mutex_unlock(&mutex1);
return NULL;
}
int main(void)
{
pthread_t tid0, tid1;
pthread_mutex_init(&mutex0, NULL);
pthread_mutex_init(&mutex1, NULL);
pthread_create(&tid0, NULL, thread0, NULL);
usleep(1000);
pthread_create(&tid1, NULL, thread1, NULL);
pthread_join(tid0, NULL);
pthread_join(tid1, NULL);
pthread_mutex_destroy(&mutex0);
pthread_mutex_destroy(&mutex1);
printf("Main thread is about quitting...\n");
}
为了更好的观察死锁现象,我们再新建一个终端用于计时

可以发现,预估运行时间为 6 s,但即使程序运行了 36 s,它也没有退出
这就是死锁现象
来分析为什么会发生死锁
假设线程调度如下:
- 线程 1 尝试获取互斥锁 1,成功(因为一开始没有线程对 互斥锁 1 上锁)
- 此时发生调度,切换到线程 2
- 线程 2 尝试获取互斥锁 2,成功(因为此时没有线程对 互斥锁 2 上锁)
此时,死锁已经产生
- 如果此时线程 2 继续运行,尝试获取锁 1,失败(因为线程 1 已经对锁 1 上锁),线程阻塞,切换到线程 1
- 线程 1 运行,尝试获取锁 2,失败(因为线程 2 已经对锁 2 上锁),线程阻塞,切换到线程 2
- 线程 2 再次尝试获取锁 1,失败
- ……
引用一张图帮助理解:
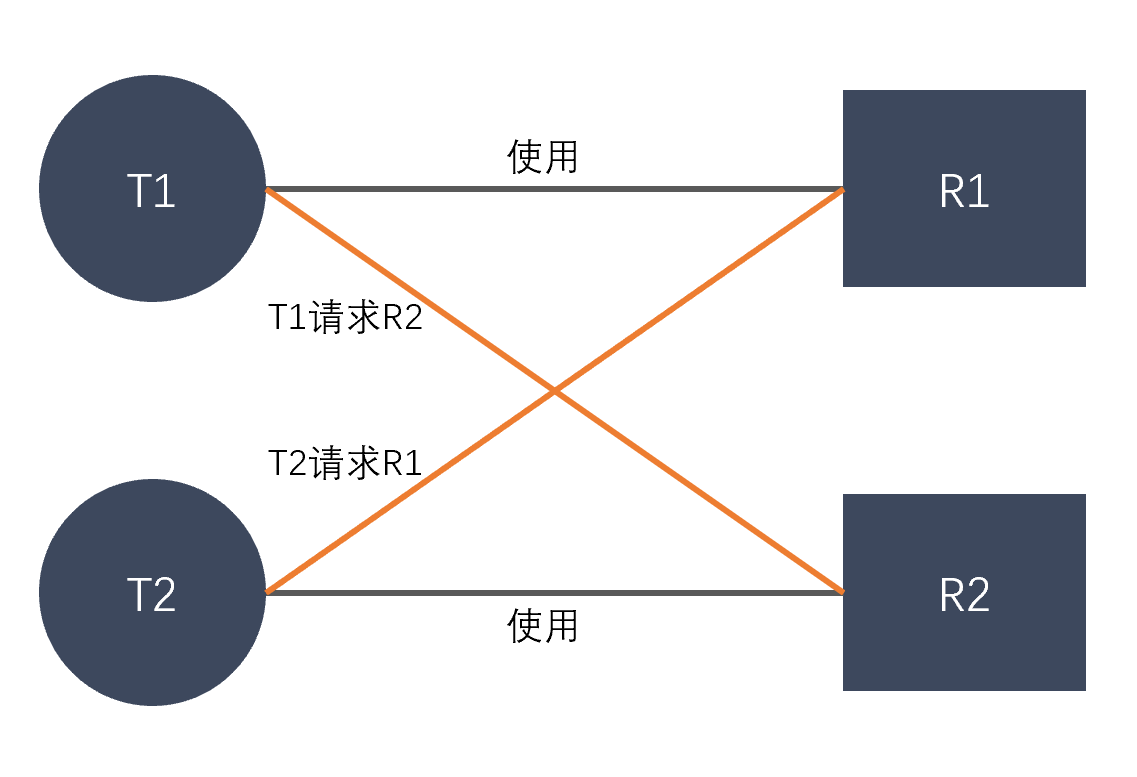
死锁产生的四个必要条件
经过上面的分析,我们可以总结死锁产生的四个必要条件:
- 互斥条件:争抢必须互斥使用的资源才会导致死锁
- 不剥夺条件:资源只能由线程释放,不能强行剥夺
- 请求和保持条件:在保持某种互斥资源不放的同时,申请另一个互斥资源
- 循环等待条件:存在一个互斥资源的循环等待链
避免死锁的方法
要想避免死锁的产生,就必须对资源进行合理地分配
- 破坏死锁的四个必要条件
- 加锁顺序一致
- 资源一次性分配(会导致资源利用率降低,以及饥饿问题)
- 避免锁未释放
此外,还可以通过使用避免死锁的算法,如死锁检测算法,银行家算法等来避免死锁带来的问题
Linux 线程同步
概念
使用同步机制来协调线程之间的执行顺序和访问共享资源的方式,以避免竞态条件和数据不一致性。常用的线程同步机制包括互斥锁、条件变量、信号量和屏障等。
为什么要有线程同步
线程同步保证了各个线程对临界资源的有序访问,如果没有线程同步,可能产生以下问题:
- 竞态条件
- 数据不一致
- 死锁
- 线程饥饿
竞态条件(Race Condition)是指在多线程或多进程环境下,多个线程或进程对共享资源的访问产生的不确定性和不可预测性结果。竞态条件会导致程序的执行结果与预期不符,可能引发各种问题,包括数据损坏、死锁、无限循环等。
条件变量机制
条件变量(Condition Variable)用于线程之间的等待和通知机制。它允许一个或多个线程在满足特定条件之前等待,而不是忙等待。当条件满足时,其他线程可以通过发送信号来通知等待的线程继续执行。
在 C 语言中,pthread_cond_t 是用于线程间条件变量的类型,它是 POSIX 线程库中的一部分。条件变量用于线程间的等待和通知机制,允许线程在特定条件下等待,并在条件满足时被通知继续执行。
相关接口
pthread_cond_init
一个条件变量在使用前必须初始化
pthread_cond_init 函数用于初始化条件变量,创建一个可用的条件变量对象。初始化后的条件变量可用于线程同步和线程间的等待/通知操作。
函数原型:
int pthread_cond_init(pthread_cond_t *cond, const pthread_condattr_t *attr);
参数:
cond:指向条件变量的指针,用于初始化。attr:指向条件变量属性的指针,通常设为NULL以使用默认属性。
返回值:
- 成功:0
- 失败:错误码
pthread_cond_wait
pthread_cond_wait 函数用于在条件变量上等待。
函数原型:
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
参数:
cond:指向条件变量的指针,用于等待和唤醒线程。mutex:指向互斥锁的指针,用于保护共享资源的访问。
返回值:
- 成功时,返回0。
- 失败时,返回一个非零的错误码,表示出现了错误。
注意:
- 在调用该函数之前,线程必须先获取互斥锁,然后将互斥锁传递给
pthread_cond_wait - 在等待条件变量时,线程会自动释放互斥锁,并在 被唤醒后重新获取互斥锁。
- 在等待条件变量时,线程可能会出现 虚假唤醒 的情况,因此需要 在循环中检查条件是否满足 ,以防止出现竞态条件。
- 线程在等待条件变量时可能会被信号中断,需要根据需要处理信号中断的情况。
pthread_cond_signal
pthread_cond_signal 函数用于向等待在条件变量上的一个线程发送信号,唤醒其中一个线程继续执行。它通常与 pthread_cond_wait 配合使用,用于实现线程间的同步。
函数原型:
int pthread_cond_signal(pthread_cond_t *cond);
参数、返回值与 pthread_cond_wait 一致,这里不再赘述
pthread_cond_boardcast
与 pthread_cond_signal 不同的是,发送广播通知,pthread_cond_boardcast 会唤醒所有等待在条件变量上的线程。
函数原型:
int pthread_cond_broadcast(pthread_cond_t *cond);
参数、返回值与 pthread_cond_wait 一致,这里不再赘述
pthread_cond_destroy
pthread_cond_destroy 函数用于销毁条件变量。在 使用完条件变量后,应该调用该函数进行清理工作,释放相关的资源。
函数原型:
int pthread_cond_destroy(pthread_cond_t *cond);
参数、返回值与 pthread_cond_wait 一致,这里不再赘述
注意:
- 调用
pthread_cond_destroy之前,应该 确保没有线程在等待条件变量上。否则,销毁条件变量将导致未定义的行为。 - 销毁条件变量后,不能再使用已销毁的条件变量。
实例
pthread_mutex_t mutex;
pthread_cond_t cond;
int flag = 0;
char *shareResorces = NULL; // 共享资源
void *thread0(void *arg)
{
printf("Now thread0 is running...\n");
pthread_mutex_lock(&mutex); // 先上锁
while (!flag) // 当条件不满足
{
// 循环等待其它线程唤醒(循环目的?防止假唤醒,因为 wait 可能失败提前返回)
// 会释放锁
pthread_cond_wait(&cond, &mutex);
}
printf("Thread0: Access shareResorces: %s\n", shareResorces);
free(shareResorces);
pthread_mutex_unlock(&mutex);
printf("Now thread0 is about quitting...\n");
return NULL;
}
void *thread1(void *arg)
{
printf("Now thread1 is running...\n");
pthread_mutex_lock(&mutex);
shareResorces = (char *)malloc(sizeof(char) * 100);
strcpy(shareResorces, "Hello, pthread_cond_t!");
flag = 1;
pthread_cond_signal(&cond); // 唤醒线程 0
pthread_mutex_unlock(&mutex); // 解锁
printf("Now thread1 is about quitting...\n");
return NULL;
}
// 同步:先执行线程 1,再执行线程 0
int main(void)
{
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&cond, NULL);
pthread_t tid0, tid1;
pthread_create(&tid0, NULL, thread0, NULL);
sleep(1);
pthread_create(&tid1, NULL, thread1, NULL);
pthread_join(tid0, NULL);
pthread_join(tid1, NULL);
pthread_cond_destroy(&cond);
pthread_mutex_destroy(&mutex);
printf("Now main thread is about quitting...\n");
}
输出:
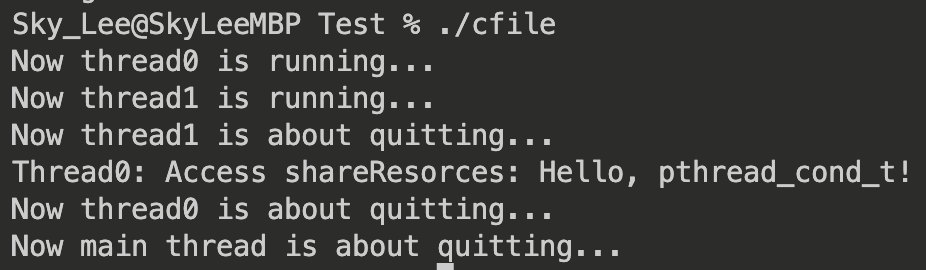
可以发现,即使让线程 0 先执行 1s,线程 0 也必须等到线程 1 写入了资源后才能访问到资源,避免了空指针异常,这体现了线程同步的必要性
为什么 wait 操作需要用到互斥量 mutex
在前面的介绍中,可以发现 pthread_cond_wait 函数参数含有互斥量 mutex,这是为什么?
第一个原因:
在等待的过程中,共享数据可能发生变化,这就需要互斥锁来保护临界资源,有了互斥锁,就能保证在等待唤醒的过程中,对临界资源的访问是互斥的
第二个原因:
确保原子性。
例如,如果 pthread_cond_wait 函数参数 不 含有互斥量 mutex:
// 错误的设计
pthread_mutex_lock(&mutex);
while (condition_is_false)
{
pthread_mutex_unlock(&mutex);
// 此处如果发生调度,想想会发生什么?
pthread_cond_wait(&cond);
pthread_mutex_lock(&mutex);
}
pthread_mutex_unlock(&mutex);
如果这样写,在 解锁之后,等待之前 ,条件可能已经满足,信号已经发出,但是该信号可能就被 pthread_cond_wait(&cond) 错过了,导致该进程永远等待唤醒
生产者消费者问题
生产者消费者问题是一种经典的互斥、同步问题,涉及到多个生产者和消费者线程对共享资源的访问和操作。
生产者线程负责生产产品,并将其放入一个 有限大小的缓冲区 中,而消费者线程负责从缓冲区中取出产品进行消费。生产者和消费者之间通过共享缓冲区进行通信。
生产者和消费者之间需要协调合作,避免出现以下问题:
- 缓冲区溢出:当缓冲区已满时,生产者必须等待,直到有空闲位置。
- 缓冲区为空:当缓冲区为空时,消费者必须等待,直到有可用产品。
为了解决生产者消费者问题,需要用到同步机制,下面是以条件变量机制解决的生产者消费者问题的代码:
// BlockQueue.h
#pragma once
#include <iostream>
#include <queue>
#include <pthread.h>
#include <unistd.h>
class BlockQueue
{
std::queue<int> data;
size_t bufferSize; // 阻塞队列缓冲区大小
pthread_mutex_t mutex; // 互斥锁
pthread_cond_t _full; // 队列满
pthread_cond_t _empty; // 队列空
bool full(void) const;
bool empty(void) const;
public:
BlockQueue(size_t bufferSize = 6);
~BlockQueue();
void push(int val);
// 和 JAVA 的 pop 类似,返回队列首元素
int pop(void);
};
// BlockQueue.cpp
#include "BlockQueue.h"
inline bool BlockQueue::full(void) const
{
return data.size() == bufferSize;
}
inline bool BlockQueue::empty(void) const
{
return data.empty();
}
BlockQueue::BlockQueue(size_t bufferSize)
: bufferSize(bufferSize)
{
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&_full, NULL);
pthread_cond_init(&_empty, NULL);
}
BlockQueue::~BlockQueue()
{
pthread_mutex_destroy(&mutex);
pthread_cond_destroy(&_full);
pthread_cond_destroy(&_empty);
}
void BlockQueue::push(int val)
{
pthread_mutex_lock(&mutex);
std::cout << "Check if the BlockQueue is full" << std::endl;
while (full())
{
std::cout << "BlockQueue is full! Waiting for consumer..." << std::endl;
pthread_cond_wait(&_full, &mutex); // 阻塞,等待消费者消费产品
}
data.push(val);
std::cout << "Push success! The size of BlockQueue is " << data.size() << std::endl;
pthread_mutex_unlock(&mutex);
pthread_cond_signal(&_empty); // 通知可能正在等待 _empty 的消费者
}
int BlockQueue::pop(void)
{
pthread_mutex_lock(&mutex);
std::cout << "Check if the BlockQueue is empty" << std::endl;
while (empty())
{
std::cout << "BlockQueue is empty! Waiting for producer..." << std::endl;
pthread_cond_wait(&_empty, &mutex); // 阻塞,等待生产者生产产品
}
int ret = data.front();
data.pop();
std::cout << "Pop success! The size of BlockQueue is " << data.size() << std::endl;
pthread_mutex_unlock(&mutex);
pthread_cond_signal(&_full); // 通知可能正在等待 _full 的生产者
return ret;
}
// main.cpp
#include "BlockQueue.h"
#include <random>
void *thread0(void *arg);
void *thread1(void *arg);
int main(void)
{
BlockQueue blockQueue;
pthread_t tid0, tid1;
pthread_create(&tid0, NULL, thread0, &blockQueue);
sleep(10); // 让队列满了再开始线程 1
pthread_create(&tid1, NULL, thread1, &blockQueue);
pthread_join(tid0, NULL);
pthread_join(tid1, NULL);
}
// 生产者线程
void *thread0(void *arg)
{
std::uniform_int_distribution<int> u(0, 9);
std::default_random_engine e(time(NULL));
BlockQueue *blockQueue = static_cast<BlockQueue*>(arg);
for (int loop = 0; loop < 60; ++loop)
{
blockQueue->push(u(e));
sleep(1);
}
return NULL;
}
// 消费者线程
void *thread1(void *arg)
{
BlockQueue *blockQueue = static_cast<BlockQueue*>(arg); // 记得用指针,否则线程 0、线程 1 的阻塞队列都不同!
for (int loop = 0; loop < 60; ++loop)
{
int val = blockQueue->pop();
std::cout << "Thread1: received data from BlockQueue: " << val << std::endl;
sleep(1);
}
return NULL;
}
某一次运行时输出:
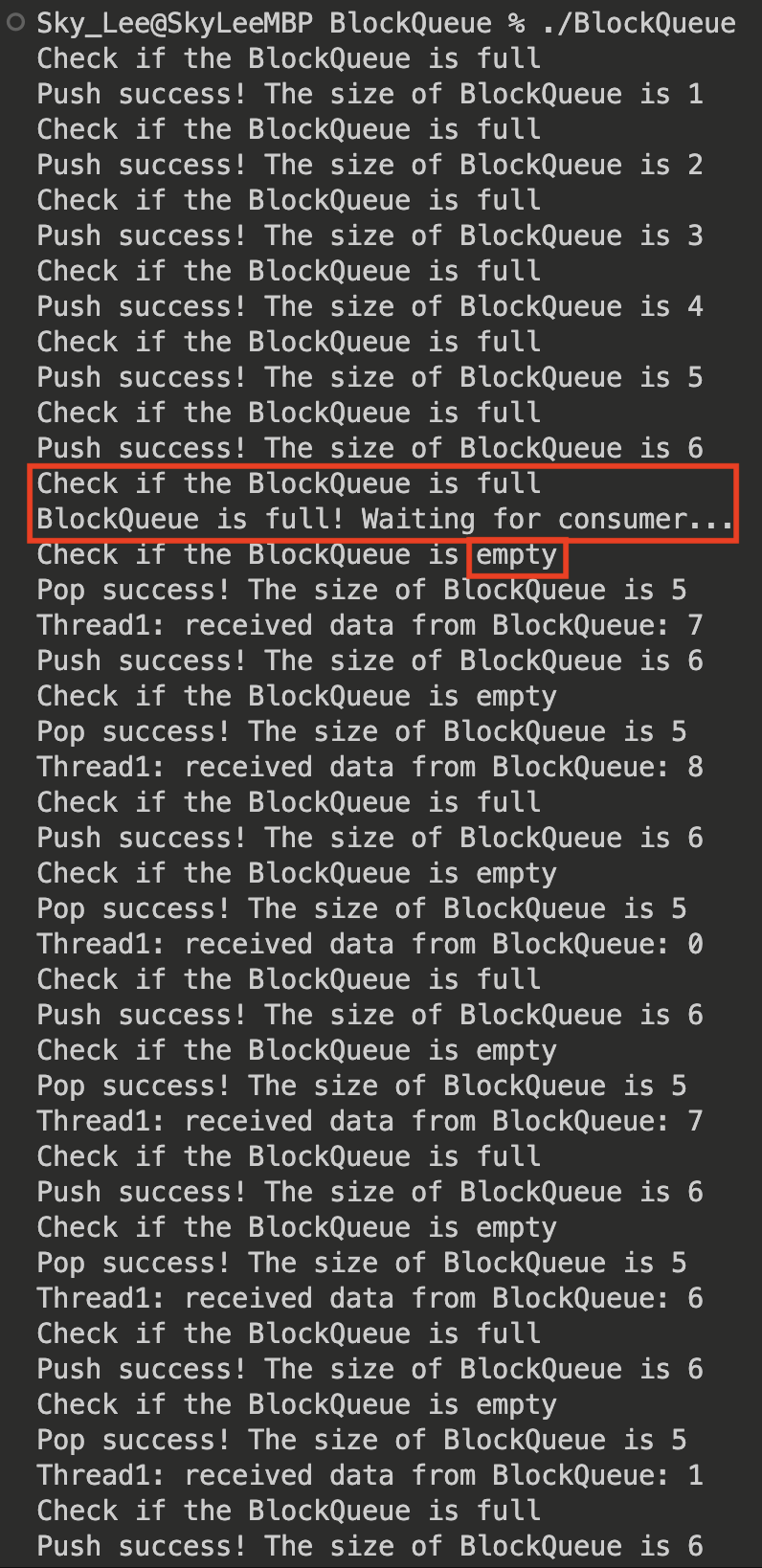
注意:
- 在使用条件变量时需要初始化,销毁
- 循环等待其它线程唤醒,防止假唤醒
- 在线程内操作队列时,为了保证两个线程操作相同的阻塞队列,需要使用指针,避免拷贝
POSIX 信号量
POSIX 信号量是一种用于进程间同步和互斥的机制。它是 POSIX 标准中定义的一组函数和数据类型,用于实现并发编程中的线程同步操作。
POSIX 信号量的特点和使用方法包括:
- 信号量用于实现资源的同步访问和互斥操作,通过控制对共享资源的访问来避免竞态条件和数据不一致性问题。
- 信号量可以通过 P(wait)和 V(post)操作来进行加锁和解锁操作,以控制对资源的访问。
- 等待 P 操作的线程或进程会被阻塞,直到信号量的计数器满足条件,才能继续执行。
- 执行 V 操作会增加信号量的计数器,并唤醒等待的线程或进程继续执行。
- 信号量的计数器可以表示资源的数量,也可以表示互斥锁的状态。
- POSIX 信号量提供了一组函数,如
sem_init、sem_wait、sem_post和sem_destroy等,用于初始化、操作和销毁信号量。
常用接口
要想使用 POSIX 信号量的接口,需要包含头文件 semaphore.h
sem_init
sem_init函数用于初始化一个POSIX信号量。它创建一个新的信号量,并设置初始值。
原型:
int sem_init(sem_t *sem, int pshared, unsigned int value)
参数:
- sem: 指向要初始化的信号量的指针
- pshared: 指定信号量的共享方式,取值为0或非零。
- 如果pshared为0,则信号量被 线程内部 使用,只能在同一进程内的线程间共享。
- 如果pshared非零,则信号量可以在多个 进程间 共享
- value: 指定信号量的初始值,必须是非负数。
返回值:
- 成功时返回0,表示信号量初始化成功。
- 失败时返回-1,表示初始化失败,具体错误信息保存在errno中。
注意:
- 在调用sem_init之前,应确保sem指针是有效的,且未被初始化。
- 对于线程内部使用的信号量,通常将pshared参数设置为0。
- 信号量的初始值通过value参数指定,它 表示资源的初始数量 。
sem_wait(P 操作)
sem_wait函数用于获取(等待)一个信号量。如果信号量的值大于0,表示有可用资源,sem_wait会将信号量的值减1,并立即返回。如果信号量的值为0,表示没有可用资源,sem_wait将阻塞线程,直到有资源可用时才返回。
原型:
int sem_wait(sem_t *sem)
参数:
- sem: 指向要操作的信号量的指针
返回值:
- 成功时返回0,表示成功获取到信号量。
- 失败时返回-1,表示出现错误,具体错误信息保存在errno中。
注意: sem_wait是一个阻塞操作,如果没有可用资源,它会一直等待,直到有资源可用或出现错误。
sem_post(V 操作)
sem_post函数用于释放一个信号量。它会将信号量的值加1,表示释放了一个资源。如果有其他线程正在等待该信号量,则其中一个线程将 被唤醒 ,可以获取到该信号量,并继续执行。
sem_post 与 sem_wait 的用法类似,这里不再赘述
sem_destroy
sem_destroy函数用于销毁一个信号量。它会释放信号量相关的资源,并将信号量重置为未初始化的状态。
原型:
int sem_destroy(sem_t *sem)
参数:
- sem: 指向要销毁的信号量的指针
返回值:
- 成功时返回0,表示成功销毁信号量。
- 失败时返回-1,表示出现错误,具体错误信息保存在errno中。
生产者消费者模型再探
再理一下生产者与消费者关系:
- 有空闲缓冲区 -> 生产者可以生产产品
- 有非空闲缓冲区 -> 消费者可以消费产品
// CircularQueue.h
#pragma once
#include <vector>
#include <semaphore.h>
#include <pthread.h>
class CircularQueue
{
std::vector<int> data;
size_t bufferSize;
size_t size;
sem_t _full; // 记录当前缓冲区存放的数据个数
sem_t _empty; // 记录当前缓冲区空闲个数
pthread_mutex_t mutex;
int front = 0;
int rear = 0;
public:
CircularQueue(int bufferSize = 6);
~CircularQueue();
void push(int val);
int pop(void);
};
// CircularQueue.cpp
#include <cstdio>
#include "CircularQueue.h"
CircularQueue::CircularQueue(int bufferSize)
:bufferSize(bufferSize)
{
pthread_mutex_init(&mutex, NULL);
sem_init(&_empty, 0, bufferSize); // 将 _empty 信号量的数量设置为 bufferSize
sem_init(&_full, 0, 0);
data.resize(bufferSize);
}
CircularQueue::~CircularQueue()
{
sem_destroy(&_empty);
sem_destroy(&_full);
pthread_mutex_destroy(&mutex);
}
void CircularQueue::push(int val)
{
sem_wait(&_empty); // P(_empty)
printf("CircularQueue: pushed data %d.\n", val);
fflush(stdout);
data[rear] = val;
rear = (rear + 1) % bufferSize;
sem_post(&_full); // V(_full)
}
int CircularQueue::pop(void)
{
sem_wait(&_full); // P(_full)
int ret = data[front];
front = (front + 1) % bufferSize;
sem_post(&_empty); // V(_empty)
printf("CircularQueue: poped data %d.\n", ret);
return ret;
}
// main.cpp
#include "CircularQueue.h"
#include <iostream>
#include <random>
#include <pthread.h>
#include <unistd.h>
// 生产者线程
void *thread0(void *arg)
{
std::uniform_int_distribution<int> u(0, 9);
std::default_random_engine e(time(NULL));
CircularQueue *circularQueue = static_cast<CircularQueue*>(arg);
for (int loop = 0; loop < 60; ++loop)
{
int val = u(e);
circularQueue->push(val);
sleep(1);
}
return NULL;
}
// 消费者线程
void *thread1(void *arg)
{
CircularQueue *circularQueue = static_cast<CircularQueue*>(arg);
for (int loop = 0; loop < 60; ++loop)
{
int val = circularQueue->pop();
sleep(1);
}
return NULL;
}
int main(void)
{
CircularQueue circularQueue;
pthread_t tid0, tid1;
pthread_create(&tid0, NULL, thread0, &circularQueue);
sleep(10); // 让队列满了再开始线程 1
pthread_create(&tid1, NULL, thread1, &circularQueue);
pthread_join(tid0, NULL);
pthread_join(tid1, NULL);
}
输出:
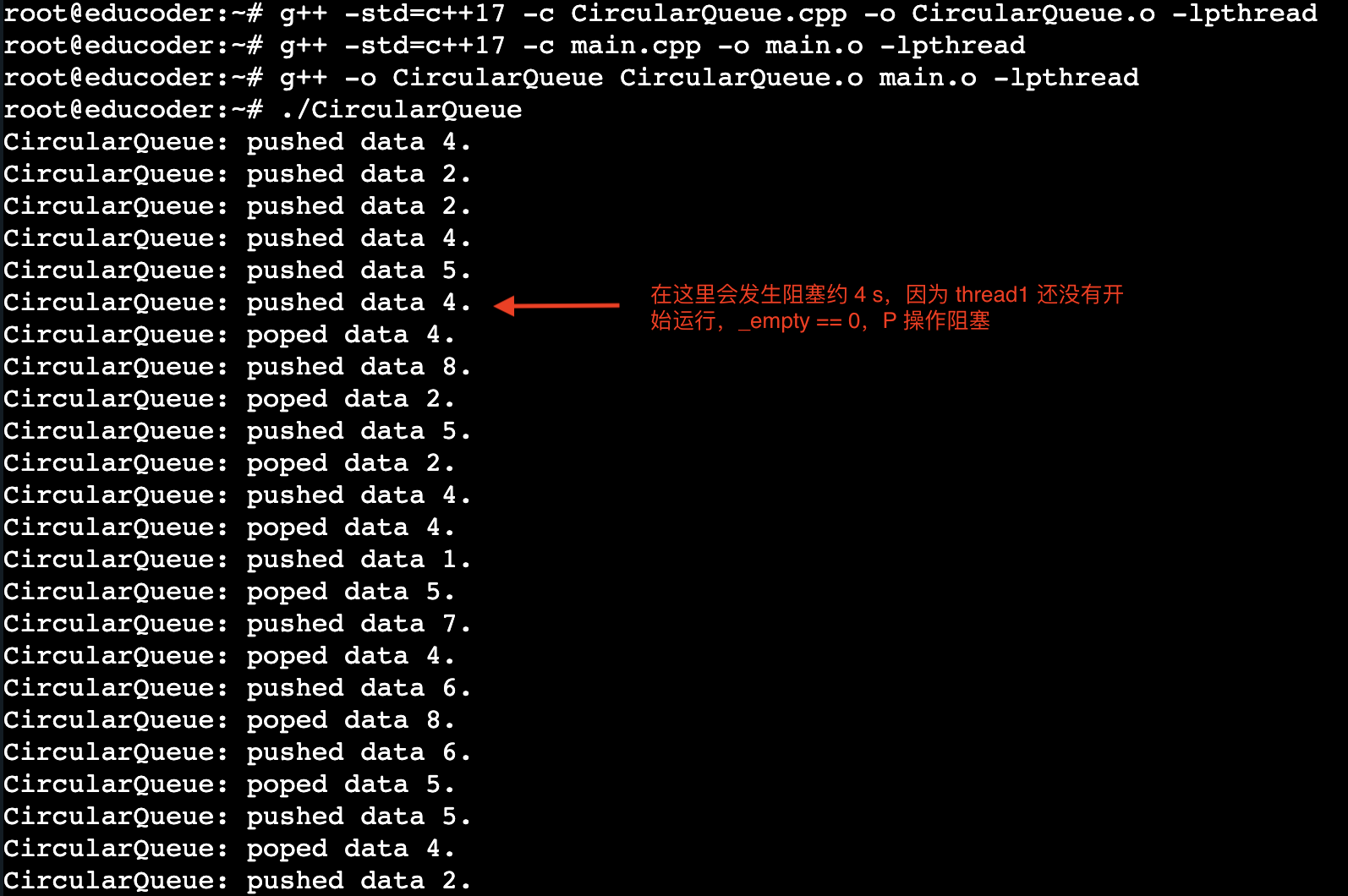
读者写者问题
有读者和写者两组并发进程,共享一个文件,当两个或两个以上的读进程同时访问共享数据时不会产生副作用,但若某个写进程和其他进程(读进程或写进程)同时访问共享数据时则可能导致数据不一致的错误。因此要求:①允许多个读者可以同时对文件执行读操作;②只允许一个写者往文件中写信息;③任一写者在完成写操作之前不允许其他读者或写者工作;④写者执行写操作前,应让己有的读者和写者全部退出。
概括一下:
- 允许多个读进程同时读数据
- 只允许一个写进程写数据
- 在写数据的过程中,不允许其它任何进程访问数据
semaphore rw = 1; // 信号量,用于实现文件的互斥访问
int count = 0; // 记录读文件进程的数量,用于实现多个进程“同时”读数据
writer()
{
while(1)
{
P(rw); // 上锁
写文件;
V(rw); // 解锁
}
}
reader()
{
while(1)
{
if(count == 0) // 如果自己是第一个读文件的进程 1
P(rw); // 上锁 2
++count;
读文件;
--count;
if(count == 0) // 如果自己是最后一个退出的进程
V(rw); // 解锁
}
}
上面的代码看起来没什么毛病嗷,但是,如果在 if(count == 0) 这句话发生了进程调度,切换到另一个读进程,即:
- 第一个读进程执行到 1,进程调度,切换到第二个读进程
- 第二个读进程执行到 1,进程调度,切换到第一个读进程
- 第一个读进程上锁
- 第二个读进程无法上锁,因为已经上锁,被阻塞
也就是说,此时并没有实现两个读进程同时访问文件的要求
如何解决?
很容易想到,出现上面的问题,根本原因是:
if(count == 0) // 如果自己是第一个读文件的进程 1
P(rw); // 上锁 2
++count;
这三句话不是原子操作,导致第二个进程以为 count == 0,进而发生阻塞
因此,再添加一个互斥信号量,以实现 “类原子操作”,即:
semaphore mutex = 1;
reader()
{
...
P(mutex);
if(count == 0) // 如果自己是第一个读文件的进程 1
P(rw); // 上锁 2
++count;
V(mutex);
读文件;
P(mutex);
--count;
if(count == 0) // 如果自己是最后一个退出的进程
V(rw); // 解锁
V(mutex);
...
}
无论是否修改,这个代码存在潜在的写进程饥饿问题,如果有源源不断的读进程,那么写进程将持续被阻塞(只有最后一个退出的读进程才能解锁 rw)
因此这种方式又叫读优先
要想实现写优先,需要再添加一个信号量:
semaphore w = 1;
writer()
{
while(1)
{
P(w);
P(rw); // 上锁
写文件;
V(rw); // 解锁
V(w);
}
}
reader()
{
...
P(w);
P(mutex);
if(count == 0) // 如果自己是第一个读文件的进程 1
P(rw); // 上锁 2
++count;
V(mutex);
V(w);
...
}
假设按照 读者 1 -> 写者 1 -> 读者 2 这种模式并发执行 P(w)
- 读者 1 执行 P(w)
- 写者 1 执行 P(w),失败,被阻塞,挂在阻塞队列的队头
- 读者 2 执行 P(w),失败,被阻塞,挂在阻塞队列的队头后
- 读者 1 执行 V(w),解锁,唤醒
写者 1进程 - …
可以发现,添加一个信号量 w,解决了写进程饥饿的问题,实现了 “写优先”
当然,这个 “写优先” 不是真正意义上的写优先,而是一种「先来先服务」的原则,体现在阻塞队列中
线程池
线程池是一种并发编程的技术,可以管理和 重用 多个线程来执行任务。
主要目的
- 提高线程的利用率和性能
- 控制线程的数量
- 避免创建和销毁线程的开销。
组成
-
任务队列(Task Queue):用于存储待执行的任务。线程池中的线程从任务队列中获取任务并执行。
-
线程池管理器(Thread Pool Manager):负责创建、初始化和管理线程池。它维护线程池的状态、线程数量、任务队列等信息。
-
工作线程(Worker Threads):线程池中的线程,负责执行任务。它们从任务队列中获取任务,并执行任务的代码逻辑。
工作流程
-
初始化线程池:创建指定数量的线程,并初始化任务队列等。
-
提交任务:外部程序将任务提交给线程池管理器,任务会被添加到任务队列中。
-
空闲线程获取任务:当线程池中的线程空闲时,它们会从任务队列中获取任务并执行。
-
执行任务:线程执行任务的代码逻辑,处理任务的操作。
-
返回结果:任务执行完成后,可以返回结果给调用方。
-
终止线程池:当不再需要线程池时,可以通过线程池管理器来终止线程池,释放资源。
优点
-
提高性能:线程池可以重用线程,避免了频繁创建和销毁线程的开销,提高了性能。
-
控制并发度:通过控制线程的数量,可以限制并发执行的任务数量,避免系统资源过度占用。
-
提供任务排队机制:任务可以在任务队列中排队等待执行,避免任务丢失和阻塞调用方。
-
提供任务调度和管理:线程池管理器可以灵活地调度任务,并提供监控和管理线程池的功能。
实例
ThreadTask.h(任务)
#pragma once
#include <functional>
#include <random>
#include <cstdio>
class ThreadTask
{
using task_t = std::function<void(void)>;
task_t task; // 简单四则运算作为任务函数
public:
ThreadTask()
:task(nullptr) {}
ThreadTask(const task_t &task)
:task(task) {}
void run(void)
{
task();
}
};
void task(void)
{
std::random_device rd;
std::mt19937 e(rd());
std::uniform_int_distribution<int> u(1, 100);
char ops[] = {'+', '-', '*', '/'};
int a = u(e);
int b = u(e);
char op = ops[u(e) % 4];
int res = 0;
switch (op)
{
case '+':
res = a + b;
break;
case '-':
res = a - b;
break;
case '*':
res = a * b;
break;
case '/':
res = a / b;
break;
default:
break;
}
// printf("[%X]%d %c %d = %d\n", pthread_self(), a, op, b, res); // 如果要看执行结果,取消注释,这里为了观察运行时间,才注释掉
// sleep(1);
}
其中,
std::random_device rd;
std::mt19937 e(rd());
std::uniform_int_distribution<int> u(1, 100);
是 C++ 11 引入的随机数库,通过使用随机设备作为种子来产生随机数
ThreadPool.hpp(线程池)
#pragma once
#include "ThreadTask.h"
#include <iostream>
#include <queue>
#include <pthread.h>
#include <unistd.h>
/**
* @brief 工具函数,每个线程的入口函数,运行任务
*
* @param arg 线程池的 this 指针
* @return void*
*/
void *runTask(void *arg);
class ThreadPool
{
static constexpr int MAX_THREAD_NUM = 6; // 默认允许的线程数量的最大值
friend void *runTask(void *arg);
private:
size_t curThreadNum; // 线程池当前含有的线程数量
size_t maxThreadNum; // 线程池最大允许的线程数量
pthread_mutex_t lock; // 互斥锁
pthread_cond_t cond; // 条件变量
bool _quit = false; // 标记线程池是否退出
std::queue<ThreadTask> taskQueue; // 线程调度队列
int popCnt = 0;
private:
// 锁定调度队列
void lockQueue(void);
// 解锁调度队列
void unlockQueue(void);
// 唤醒一个正在等待的线程
void wakeupOne(void);
void wakeupAll(void);
// 让线程阻塞
void threadWait(void);
// 让线程退出
void threadQuit(void);
public:
ThreadPool(size_t maxThreadNum = MAX_THREAD_NUM);
~ThreadPool();
void pushTask(const ThreadTask &task);
void popTask(ThreadTask &task);
// 使线程池退出所有线程
void quit(void);
};
inline void ThreadPool::lockQueue(void)
{
pthread_mutex_lock(&lock);
}
inline void ThreadPool::unlockQueue(void)
{
pthread_mutex_unlock(&lock);
}
inline void ThreadPool::wakeupOne(void)
{
pthread_cond_signal(&cond);
}
inline void ThreadPool::wakeupAll(void)
{
pthread_cond_broadcast(&cond);
}
inline void ThreadPool::threadWait(void)
{
if (_quit)
threadQuit();
pthread_cond_wait(&cond, &lock);
}
inline void ThreadPool::threadQuit(void)
{
--curThreadNum;
unlockQueue();
pthread_exit(NULL);
}
void ThreadPool::pushTask(const ThreadTask &task)
{
lockQueue();
if (_quit)
{
unlockQueue();
return;
}
taskQueue.push(task);
unlockQueue();
wakeupOne(); // 唤醒可能正在等待的线程
}
void ThreadPool::popTask(ThreadTask &task)
{
// lockQueue(); // 不能上锁,因为在 runTask 函数已经上锁,重复上锁会阻塞!
task = taskQueue.front();
taskQueue.pop();
// unlockQueue();
}
void ThreadPool::quit(void)
{
lockQueue();
_quit = true;
unlockQueue();
while (curThreadNum > 0)
{
wakeupAll();
usleep(1000);
}
}
ThreadPool::ThreadPool(size_t maxThreadNum)
: curThreadNum(0), maxThreadNum(maxThreadNum)
{
pthread_mutex_init(&lock, NULL);
pthread_cond_init(&cond, NULL);
pthread_t tid;
for (size_t i = 0; i < maxThreadNum; ++i)
{
if (pthread_create(&tid, NULL, runTask, this) != 0)
{
throw std::runtime_error("Create Thread Error!\n");
}
++curThreadNum;
}
}
ThreadPool::~ThreadPool()
{
pthread_mutex_destroy(&lock);
pthread_cond_destroy(&cond);
}
void *runTask(void *arg)
{
pthread_detach(pthread_self());
ThreadPool *threadPool = static_cast<ThreadPool *>(arg);
while (1) // 让线程一直做任务,直到调用了 threadpool.quit()「会通知线程退出」
{
threadPool->lockQueue(); // 注意,在循环内上锁,否则就不能互斥的访问临界资源!!
while (threadPool->taskQueue.empty())
{
threadPool->threadWait();
}
ThreadTask task;
threadPool->popTask(task);
threadPool->unlockQueue();
task.run();
fflush(stdout);
// sleep(3);
}
return NULL;
}
重点和易错点已经标注在代码中
main.cpp(请求方)
#include "ThreadPool.hpp"
#include <iostream>
#include <ctime>
#include <cstdio>
int main(void)
{
printf("-------------------ThreadPool[%d]-------------------\n", getpid());
time_t startTime = time(NULL);
ThreadPool threadPool(500); // 开 500 个线程
for(int i = 0; i < 100000; ++i) // 来 100000 个任务,分配给 500 个线程执行
{
ThreadTask threadTask(task);
threadPool.pushTask(threadTask);
}
threadPool.quit();
time_t endTime = time(NULL);
printf("Process runtime: %lf\n", difftime(endTime, startTime));
}
完成相同数量的任务,使用线程池:

不使用线程池:

可以看到,使用线程池,执行时间不到 1 s,而不使用线程池,执行相同任务,需要 26 s!
虽然使用线程池产生了额外的调度开销与性能损失,但只要开的线程数量合适,执行效率会大大提高!
单例设计模式
饿汉实现
template <typename T>
// 饿汉实现单例模式
class Singleton
{
private:
static T val;
// 私有构造函数,防止实例化对象
Singleton() {}
public:
// 公共静态成员函数,用于获取单例实例
static T &GetInstance()
{
return val;
}
};
template <typename T>
T Singleton<T>::val = 114; // 在类的外部进行初始化
int main()
{
int &val = Singleton<int>::GetInstance();
// 使用单例对象进行操作
val = 2;
std::cout << Singleton<int>::GetInstance() << std::endl; // 2
std::cout << Singleton<double>::GetInstance() << std::endl; // 114
// 因为 Singleton<double> 与 Singleton<int> 是不同的实例
return 0;
}
懒汉实现
int cnt = 0; // 记录实例化的次数
template <typename T>
// 懒汉实现单例模式
class Singleton
{
private:
static T* val;
// 私有构造函数,防止实例化对象
Singleton() {}
public:
// 公共静态成员函数,用于获取单例实例
static T* GetInstance()
{
if(val == nullptr)
{
val = new T;
++cnt;
}
return val;
}
};
template<typename T>
T* Singleton<T>::val = nullptr;
测试代码:
void* run(void *arg)
{
pthread_detach(pthread_self());
int *pi = Singleton<int>::GetInstance();
return NULL;
}
int main()
{
pthread_t tid;
for(int i = 0; i < 100; ++i) // 开 100 个线程
{
pthread_create(&tid, NULL, run, NULL);
}
std::cout << cnt << std::endl; // 输出实例化次数
return 0;
}
输出:
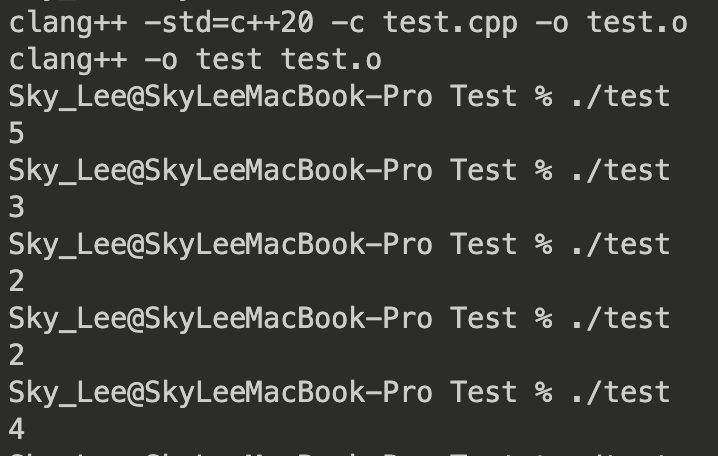
这段代码存在一个严重问题:线程不安全
在单线程环境下,如果直接使用单次判断 val == nullptr,则在第一次调用 GetInstance() 时会创建单例对象,这是正确的。
但在多线程环境下,可能会导致多个线程 「同时」通过 第一次判断,进入临界区创建实例,从而导致 创建多个实例 ,违背了单例模式的要求。(这里的同时是宏观上的)
如何解决?使用互斥锁
template <typename T>
// 懒汉实现单例模式
class Singleton
{
private:
static T* val;
static pthread_mutex_t lock;
// 私有构造函数,防止实例化对象
Singleton() {}
public:
// 公共静态成员函数,用于获取单例实例
static T* GetInstance()
{
pthread_mutex_lock(&lock);
if(val == nullptr)
{
val = new T;
++cnt;
}
pthread_mutex_unlock(&lock);
return val;
}
};
template<typename T>
T* Singleton<T>::val = nullptr;
template <typename T>
pthread_mutex_t Singleton<T>::lock = PTHREAD_MUTEX_INITIALIZER;
再次运行:
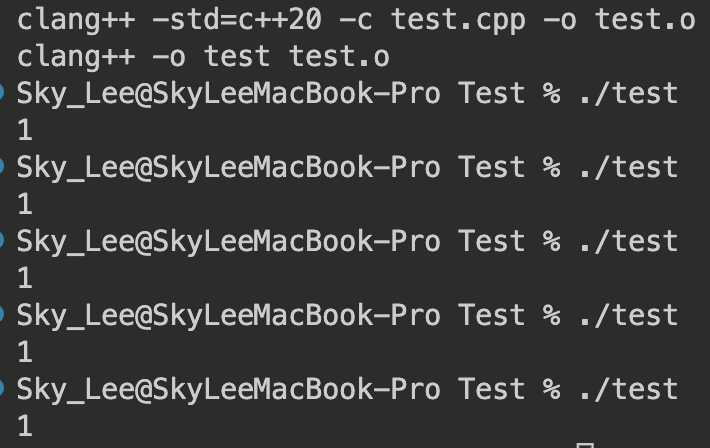
经过多次运行,输出均为 1,可以证明,val 只被实例化 1 次
但实际上,上面的代码还有一个问题,性能损失
因为不管有没有实例化 val, 每次 有一个线程尝试获取实例对象,我们 都先上锁 ,这样无疑增加了许多锁冲突,造成 性能严重损失!
如何解决?
双重检查锁定(Double-Checked Locking)
static T* GetInstance()
{
if(val == nullptr) // 解决大部分锁冲突,因为大部分线程运行时,val 已被实例化
{
pthread_mutex_lock(&lock);
if(val == nullptr) // 确实需要实例化
{
val = new T;
++cnt;
}
}
pthread_mutex_unlock(&lock);
return val;
}
双重检查锁定避免了潜在的性能损失
注意: 在使用双重检查锁定时,需要将指针 val 声明为 volatile 类型,以避免编译器进行优化。这是因为编译器在进行优化时可能会对指令进行重排,导致双重检查锁定失效。使用 volatile 关键字可以告诉编译器不要对该指针进行优化,保证代码的正确性。
static volatile T* val;
// ......
template<typename T>
volatile T* Singleton<T>::val = nullptr;
线程安全相关
STL 的容器是否线程安全
STL 的容器 不是 线程安全的
因为在设计 STL 时,追求的是极致的效率,如果要实现线程安全,势必会带来许多性能开销
因此,STL 的容器不是线程安全的,需要用户保证线程安全
智能指针是否线程安全
智能指针,即 unique_ptr 和 shared_ptr 是线程安全的
对于 unique_ptr,它只在当前代码范围内生效,离开当前范围,自动析构,不存在线程安全问题
对于 shared_ptr,与 unique_ptr 不同的是,离开当前范围是否析构,取决于「引用计数值」是否为 0
因此,shared_ptr 的线程安全主要就取决于「引用计数值」的管理上
shared_ptr 的实现使用了原子操作(例如CAS,Compare-and-Swap)来确保 对引用计数的操作是线程安全的 。shared_ptr 的引用计数是 以原子方式 进行递增和递减的,这意味着多个线程可以同时对引用计数进行操作,而不会导致竞争条件或数据不一致的问题。
-
同一个shared_ptr对象可以被多线程同时读取。
-
不同的shared_ptr对象(即使管理的对象指针相同)可以被多线程同时修改。
-
同一个shared_ptr对象不能被多线程直接修改
几种锁
悲观锁
悲观锁的核心思想:总是 悲观地 认为其它线程 会 修改临界资源,因此,每次获取临界数据前,总会加锁
特点:
- 阻塞等待:当获取锁的线程无法立即获得资源访问权限时,会被阻塞等待,直到获取到锁为止。
- 资源独占 :悲观锁一次只允许一个线程访问共享资源,其他线程需要等待锁的释放。
- 效率较低 :由于需要频繁地加锁和解锁操作,以及可能的线程切换和阻塞唤醒操作,悲观锁在高并发场景下可能导致性能下降。
因此,悲观锁适用于 读写频繁 的场景
乐观锁
乐观锁的核心思想:总是 乐观地 认为其它线程 不会 修改临界资源,因此,每次获取临界数据前,不会加锁,而是在更新资源时 检查是否发生冲突
这种也叫做 无锁编程
检查方式:
- 版本号(Versioning):为共享资源引入一个版本号或时间戳,每次更新时都对版本号进行比较,以检测是否发生冲突。
- CAS(Compare and Swap):使用原子操作,比较共享资源的当前值与预期值,若相等则进行更新,否则 重试。
CAS(Compare and Swap)是一种乐观锁的实现方式,用于解决并发编程中的原子操作问题。CAS操作通过比较内存中的值与期望值,如果相等则进行交换,否则不执行交换
特点:
- 非阻塞:乐观锁 不会阻塞 其他线程的访问,线程可以自由地进行操作。
- 冲突检测
- 重试机制
例如:在线表格编辑这个场景就是使用的乐观锁,这个场景下,用户修改到同一个单元格,即发生冲突的概率较小
- 如果使用悲观锁,那每个用户提交自己的修改这个过程是单线程的,很慢,用户体验不好
- 如果使用乐观锁,由于乐观锁实际上就是无锁编程,并发高,并且发生冲突的概率较低(重试的概率小),用户体验会好很多
在这个场景,假设有两个用户:
- 用户 A 从 Server 获取文档以及版本号V0
- 用户 B 从 Server 获取文档以及版本号V0
- 用户 A 修改了单元格 A,提交,服务器校验本地版本号与用户提交携带的版本号一致,修改成功,更新版本号为 V1
- 用户 B 也修改了单元格 A,提交,服务器校验本地版本号与用户提交携带的版本号 不一致,修改失败,通常客户端会重新从 Server 获取最新的文档,然后让用户重试
因此,只有 加锁成本高,并且发生 冲突概率比较小 的情况下,可以考虑使用乐观锁
读写锁
在之前我们使用伪代码以及信号量机制介绍了读者写者问题
实际上,POSIX 还提供了一些接口实现读写锁
pthread_rwlock_init
pthread_rwlock_init 函数用于初始化读写锁对象。
函数原型:
int pthread_rwlock_init(pthread_rwlock_t *rwlock, const pthread_rwlockattr_t *attr);
参数:
rwlock:读写锁对象的指针attr:读写锁属性对象的指针,用于设置读写锁的属性。可以传递NULL,表示使用默认属性
返回值:
- 成功时,返回 0。
- 失败时,返回错误代码。
示例用法:
pthread_rwlock_t rwlock;
pthread_rwlock_init(&rwlock, NULL);
pthread_rwlockattr_setkind_np(设置锁的偏好)
pthread_rwlockattr_setkind_np 函数是一个 非标准的 POSIX 函数,用于设置读写锁属性中的锁类型。
函数原型:
int pthread_rwlockattr_setkind_np(pthread_rwlockattr_t *attr, int pref);
参数:
attr:读写锁属性对象的指针pref:锁类型的偏好值。可以是以下常量之一:PTHREAD_RWLOCK_PREFER_READER_NP:偏好于读者PTHREAD_RWLOCK_PREFER_WRITER_NP:偏好于写者PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP:偏好于非递归写者
返回值:
- 成功时,返回 0。
- 失败时,返回错误代码。
注意: pthread_rwlockattr_setkind_np 是一个非标准的函数,其可移植性可能有所限制。
pthread_rwlock_rdlock
pthread_rwlock_rdlock 函数用于获取读锁,允许多个线程同时读取共享资源,但不允许写入操作。
函数原型:
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
参数 rwlock 是一个指向读写锁对象的指针,指向要获取读锁的读写锁对象。
函数返回值为 0 表示成功获取读锁,非零值表示失败。
调用 pthread_rwlock_rdlock 函数会尝试获取读锁,
- 如果当前 没有线程持有写锁,则获取成功
- 如果有其他线程持有写锁,则获取读锁的线程会被阻塞,直到写锁被释放
读锁是 共享的 , 多个线程可以同时持有读锁 ,并行地读取共享资源。在 读锁被持有期间,其他线程可以继续获取读锁,但无法获取写锁,保证了读锁的共享性和读操作的并发性。
pthread_rwlock_wrlock
pthread_rwlock_wrlock 函数用于获取写锁,允许一个线程独占地写入共享资源,而其他线程无法同时读取或写入。
函数原型:
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
- 如果当前没有线程持有读锁或写锁,则获取成功,允许当前线程 独占地写入 共享资源。
- 如果有其他线程持有读锁或写锁,则获取写锁的线程会被阻塞,直到读锁和写锁都被释放。
写锁是独占的,一旦某个线程获取写锁,其他线程无法同时获取读锁或写锁,保证了写操作的互斥性。
pthread_rwlock_unlock
pthread_rwlock_unlock 函数用于释放读写锁(读锁或写锁)。
函数原型:
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
- 对于读锁,如果当前线程持有读锁的计数大于 1,则只是将读锁计数减 1
- 对于写锁,会将写锁标记为未持有状态。
pthread_rwlock_destroy
pthread_rwlock_destroy 函数用于销毁一个读写锁对象,并释放与之相关的资源。
函数原型:
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
实例
#include <iostream>
#include <string>
#include <vector>
#include <random>
#include <pthread.h>
#include <unistd.h>
std::string sharedResorces = "default";
std::vector<std::string> dic =
{
"niuma", "mabaoguo", "dingzhen", "wangyuan", "dianlao"
};
pthread_rwlock_t rwlock;
pthread_mutex_t mutex; // 用于标准输出的互斥访问
// 读线程
void* thread0(void *arg)
{
pthread_detach(pthread_self());
for(int i = 0; i < 100; ++i)
{
pthread_rwlock_rdlock(&rwlock);
// std::string buff = "ReadThread[";
// buff += std::to_string(pthread_self()->__sig);
// buff += "]: ";
// buff += sharedResorces;
// buff.push_back('\n');
// std::cout << buff;
// std::cout.flush();
pthread_mutex_lock(&mutex);
printf("ReadThread[%X]: ", pthread_self());
std::cout << sharedResorces << std::endl;
pthread_mutex_unlock(&mutex);
pthread_rwlock_unlock(&rwlock);
sleep(1);
}
return NULL;
}
// 写线程
void* thread1(void *arg)
{
pthread_detach(pthread_self());
std::mt19937 e;
std::uniform_int_distribution<int> u(0, 4);
for(int i = 0; i < 100; ++i)
{
pthread_rwlock_wrlock(&rwlock);
sharedResorces = dic[u(e)];
pthread_rwlock_unlock(&rwlock);
sleep(1);
}
return NULL;
}
int main(void)
{
pthread_t tid;
pthread_rwlock_init(&rwlock, NULL);
pthread_mutex_init(&mutex, NULL);
for(int i = 0; i < 10; ++i)
{
pthread_create(&tid, NULL, thread0, NULL);
}
pthread_create(&tid, NULL, thread1, NULL);
sleep(10);
pthread_rwlock_destroy(&rwlock);
pthread_mutex_destroy(&mutex);
return 0;
}