执行一个 SQL 语句,发生了什么?
SQL 语句 在 MySQL 的大致执行流程
先来看看整体流程:
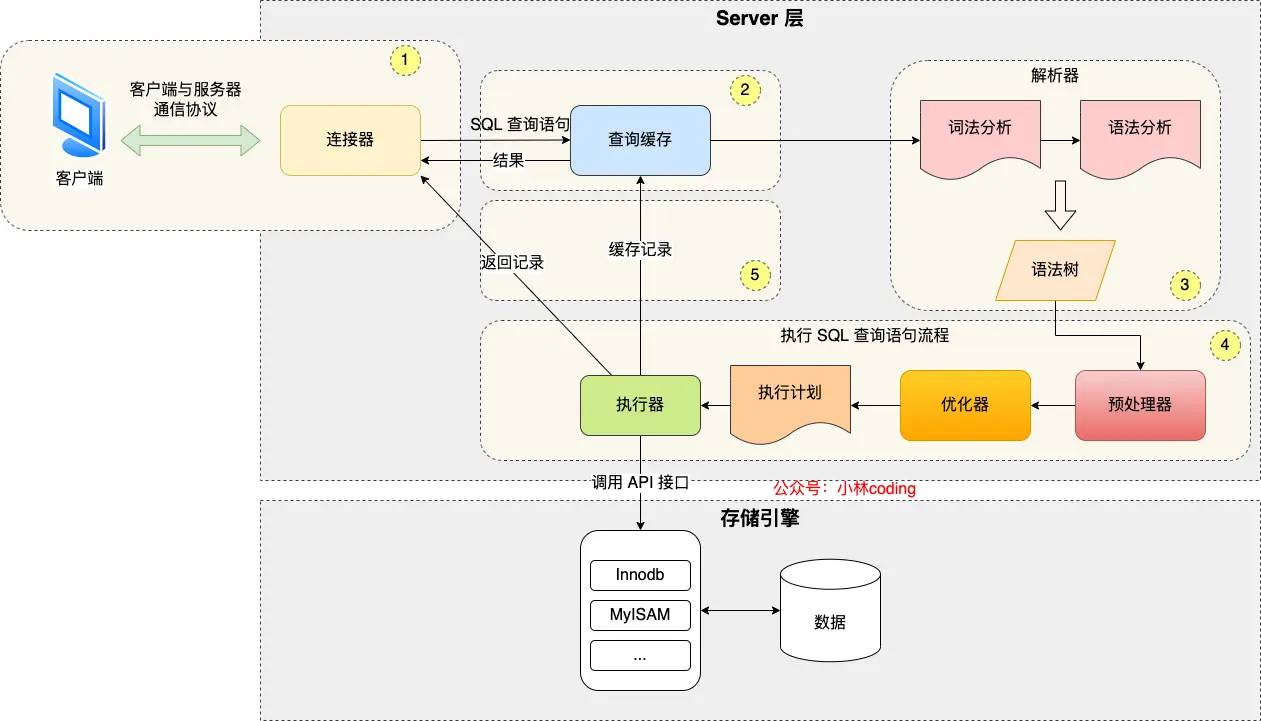
- Client 先与 Server 建立连接,确定 Client 的权限,后续请求的权限都基于此
- 执行 SQL 语句前,先看看 Cache 有没有这个 SQL 的缓存,如果有直接返回,如果没有:
- 解析 SQL 语句
- 执行 SQL 语句:
- 预处理:看看字段、表等是否存在
- 确定执行计划:选择合适的索引
- 执行,向存储引擎发起 API 请求
可以发现,MySQL 的整体架构主要分为两部分:
- Server:负责与 Client 的通信,SQL 语句的分析,执行 SQL
- 存储引擎:负责数据的落地
建立连接 — 连接器
在执行 SQL 语句前,Client 需要先与 Server 建立连接
MySQL 建立的连接是基于 TCP 的
Client 建立连接时,需要指定用户名和密码,如果验证通过,连接器就会获取该用户拥有的权限,后续的 SQL 调用,都是基于这个时候获取的权限来鉴权的
查询缓存
连接建立后,如果 Client 想要执行一个 SQL 语句,Server 会先看看这个 SQL 语句的查询结果有没有缓存(缓存是 KV 结构),如果有缓存,就可以直接返回结果给 Client
为了确保数据的一致性,只要表的数据发生更改,MySQL 就会清空该表对应的缓存
因此,对于更新频繁的表,查询缓存的命中率是很低的
MySQL 8.0 版本直接将查询缓存删掉了
SQL 语句解析 — 解析器
执行 SQL 语句之前,还要看看有没有语法错误
MySQL 会使用「解析器」将一个 SQL 语句解析成若干个词
- 关键词:如 select、from、where
- 非关键词:如 user
解析过后,看看有没有语法错误,如果有,直接返回错误给 Client,如果没有,构建语法树,为后续执行 SQL 做准备
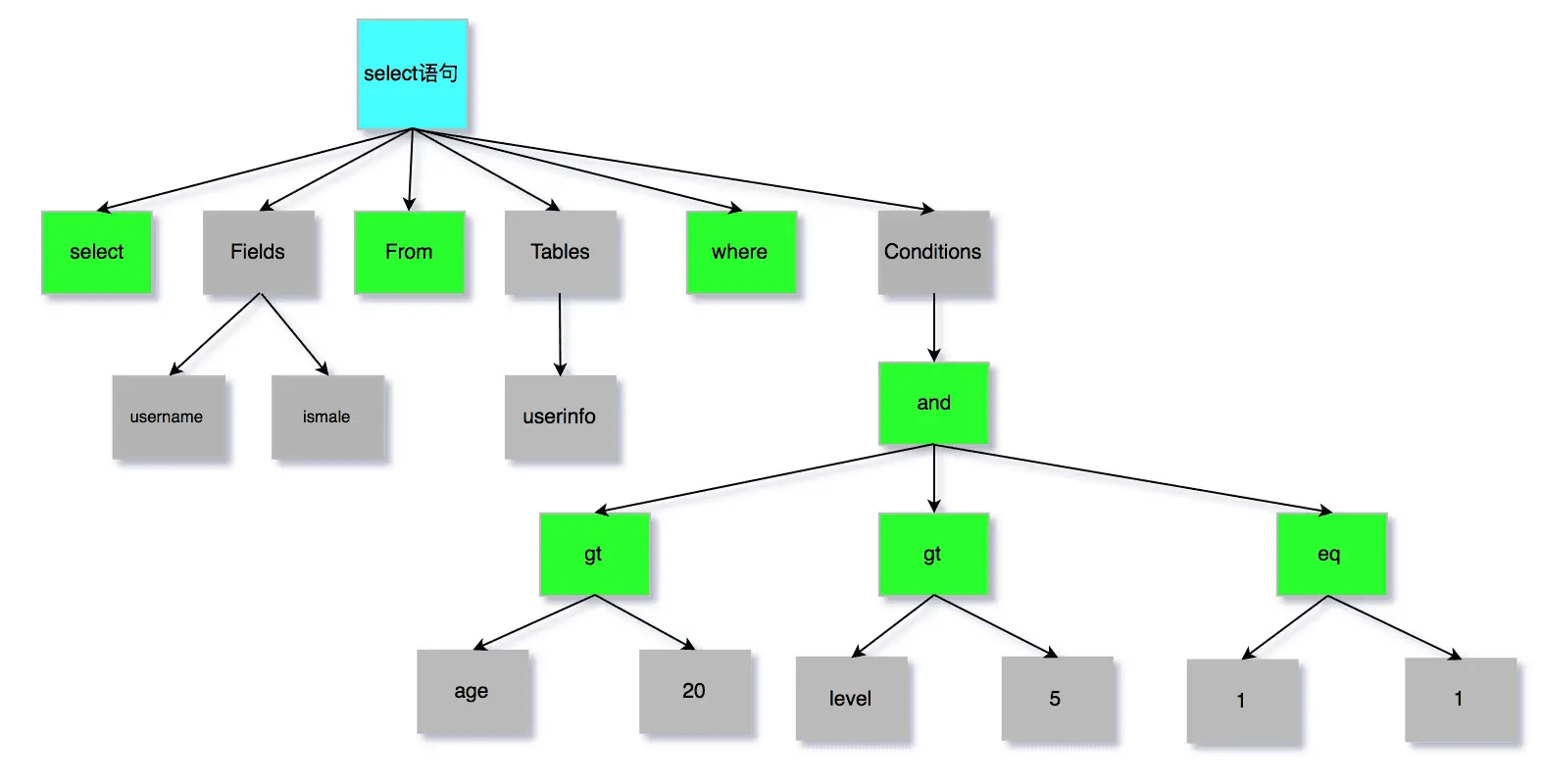
执行 SQL 语句
预处理器
预处理器会基于之前构建的语法树来 判断表、字段在数据库中是否存在

优化器
在执行之前,还要确定 执行计划
由于一个 SQL 语句使用到的索引可能有多个,优化器需要选择一个查询性能较高的索引
例如,假设有一个 user 表:
create table User
(
id int auto_increment
primary key,
name varchar(10) not null,
sex char null,
phoneNum varchar(20) null
);
并且有两个索引:
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| User | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
| User | 1 | idx_name | 1 | name | A | 0 | NULL | NULL | | BTREE | | | YES | NULL |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
如果执行 select id, name from User where id > 1 and name like 'f%';,会用到哪个索引呢?
可以使用 explain 来看看:
+----+-------------+-------+------------+-------+------------------+----------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+------------------+----------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | User | NULL | range | PRIMARY,idx_name | idx_name | 46 | NULL | 1 | 75.00 | Using where; Using index |
+----+-------------+-------+------------+-------+------------------+----------+---------+------+------+----------+--------------------------+
可以看到,使用了 idx_name,而不是聚集索引(主键索引)
因为使用 idx_name,对于这个 SQL 语句来说,不涉及回表查询,相当于是覆盖索引了,相对主键索引,性能更好
如果是 select * from User where id > 1 and name like 'f%',那么就要走主键索引了,避免一次回表查询
执行器
确定了执行计划,Server 层就会与存储引擎层交互了
以两个例子来说说交互过程:
- 全表查询
- 索引下推
全表查询
例如:select * from user where sex = 'F';
- 执行器第一次查询,让存储引擎读取表中第一条记录
- 执行器会判断这个记录是否符合条件
- 如果不符合,跳过
- 如果符合, 将结果返回给客户端
- 一直重复上述过程,直到数据全部读取过一遍
可以发现,执行器每得到一个合法数据,就会返回给客户端,之所以客户端显示的是所有记录,是因为客户端会在查询全部执行完毕后,才会将结果返回给用户
索引下推
索引下推是 MySQL5.6 版本引入的策略,用于联合索引的优化
具体来说,索引下推将回表这个操作下放到了存储引擎层,而不是 Server,减少回表次数,提高效率
例如假设有一个联合索引(age,salary)
执行 select * from user where age > 10 and salary = 1000
根据查询条件,联合索引会部分失效:age 字段可以用到索引,但 salary 不能
如果不启用索引下推:
- 执行器调用 API,使存储引擎定位到 age > 10 的第一条记录
- 存储引擎获取主键值,执行回表查询,将完整的查询结果返回给 Server
- Server 来判断 salary 是否等于 1000,如果相等,返回给 Client
如果启用索引下推:
- 执行器调用 API,使存储引擎定位到 age > 10 的第一条记录
- 由于建立联合索引,存储引擎可以自己判断 salary 是否等于 1000,如果相等,根据主键 id 执行回表查询,将完整的查询结果返回给 Server
- Server 判断其它条件是否满足(本例没有其它条件)如果满足,将结果返回给 Client
可以发现,如果不启用索引下推,当满足 age > 10,就要回表查询;而启用索引下推,只有当 salary = 1000 时才会回表查询
可以使用 explain 执行计划看看有没有使用索引下推:

如果出现 Using Index Condition,说明使用了索引下推
MySQL 一行记录是如何存储的?
下面的示例都是基于 MySQL8.1 版本
MySQL 的数据存放在哪里?
可以使用 SHOW VARIABLES LIKE 'datadir'; 来查看 MySQL 数据的存储位置:
mysql> SHOW VARIABLES LIKE 'datadir';
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| datadir | /var/lib/mysql/ |
+---------------+-----------------+
1 row in set (0.09 sec)
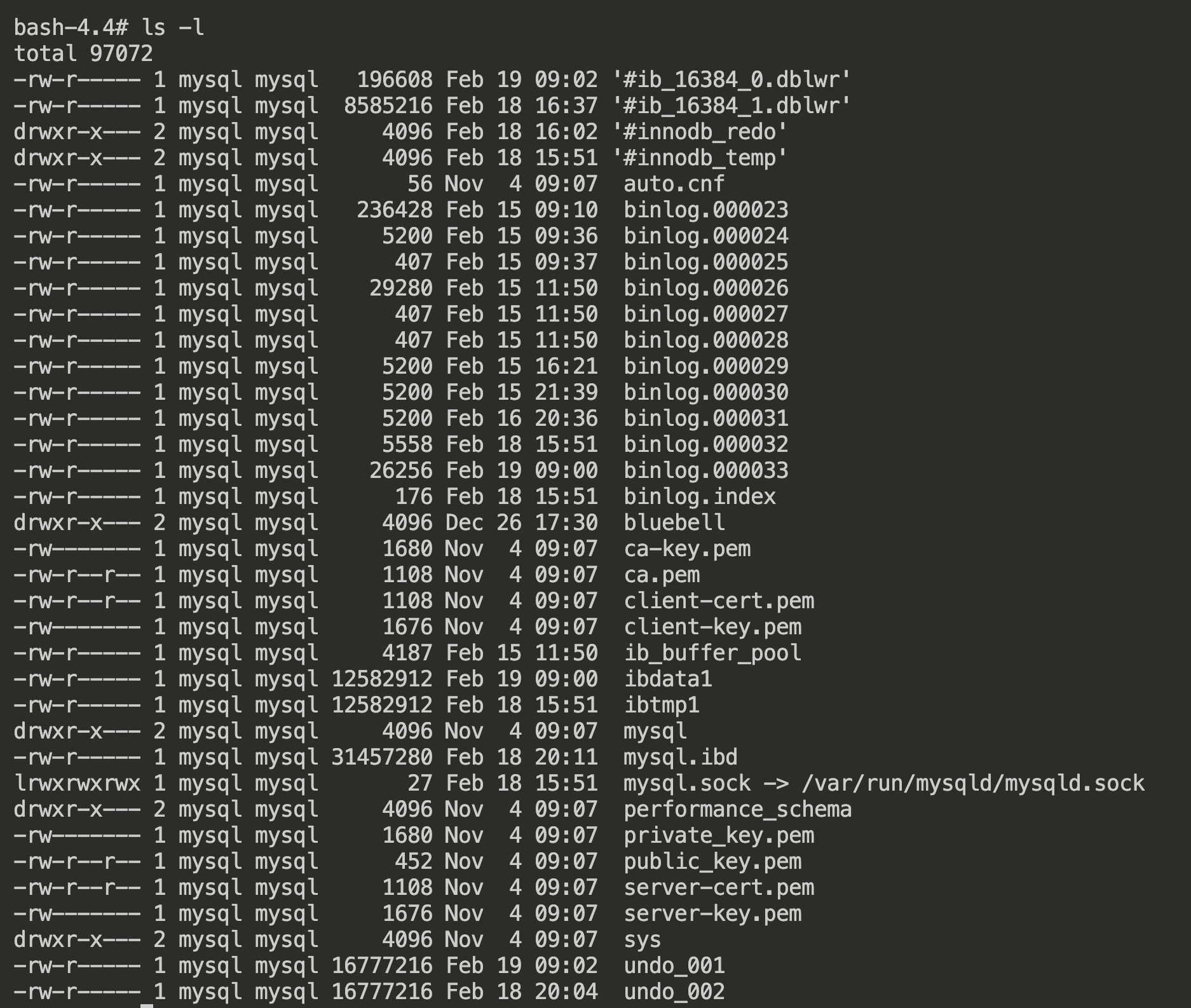
这个文件夹内存放了 MySQL 存储的所有数据,这里面还有若干个子目录,每个子目录代表一个 db,存储了表数据
bash-4.4# cd bluebell/
bash-4.4# ls -l
total 3420
-rw-r----- 1 mysql mysql 114688 Feb 18 20:11 comment_contents.ibd
-rw-r----- 1 mysql mysql 114688 Feb 18 20:11 comment_indices.ibd
-rw-r----- 1 mysql mysql 114688 Feb 18 20:11 comment_subjects.ibd
-rw-r----- 1 mysql mysql 131072 Feb 18 20:11 comment_user_hate_mappings.ibd
-rw-r----- 1 mysql mysql 147456 Feb 18 20:11 comment_user_like_mappings.ibd
-rw-r----- 1 mysql mysql 147456 Feb 18 20:11 communities.ibd
-rw-r----- 1 mysql mysql 114688 Jan 11 16:37 expired_post_scores.ibd
-rw-r----- 1 mysql mysql 114688 Feb 15 09:10 fts_000000000000042e_00000000000000ac_index_1.ibd
-rw-r----- 1 mysql mysql 114688 Nov 4 09:08 fts_000000000000042e_00000000000000ac_index_2.ibd
-rw-r----- 1 mysql mysql 114688 Nov 4 09:08 fts_000000000000042e_00000000000000ac_index_3.ibd
-rw-r----- 1 mysql mysql 114688 Nov 4 09:08 fts_000000000000042e_00000000000000ac_index_4.ibd
-rw-r----- 1 mysql mysql 114688 Nov 4 09:08 fts_000000000000042e_00000000000000ac_index_5.ibd
-rw-r----- 1 mysql mysql 114688 Feb 15 09:10 fts_000000000000042e_00000000000000ac_index_6.ibd
-rw-r----- 1 mysql mysql 163840 Feb 15 09:10 fts_000000000000042e_00000000000000b3_index_1.ibd
-rw-r----- 1 mysql mysql 114688 Nov 4 09:08 fts_000000000000042e_00000000000000b3_index_2.ibd
-rw-r----- 1 mysql mysql 114688 Nov 4 09:08 fts_000000000000042e_00000000000000b3_index_3.ibd
-rw-r----- 1 mysql mysql 114688 Nov 4 09:08 fts_000000000000042e_00000000000000b3_index_4.ibd
-rw-r----- 1 mysql mysql 114688 Nov 4 09:08 fts_000000000000042e_00000000000000b3_index_5.ibd
-rw-r----- 1 mysql mysql 294912 Feb 15 09:10 fts_000000000000042e_00000000000000b3_index_6.ibd
-rw-r----- 1 mysql mysql 114688 Nov 4 09:08 fts_000000000000042e_being_deleted.ibd
-rw-r----- 1 mysql mysql 114688 Nov 4 09:08 fts_000000000000042e_being_deleted_cache.ibd
-rw-r----- 1 mysql mysql 114688 Feb 15 09:10 fts_000000000000042e_config.ibd
-rw-r----- 1 mysql mysql 114688 Feb 18 16:53 fts_000000000000042e_deleted.ibd
-rw-r----- 1 mysql mysql 114688 Nov 4 09:08 fts_000000000000042e_deleted_cache.ibd
-rw-r----- 1 mysql mysql 262144 Feb 18 20:11 posts.ibd
-rw-r----- 1 mysql mysql 163840 Feb 19 09:00 users.ibd
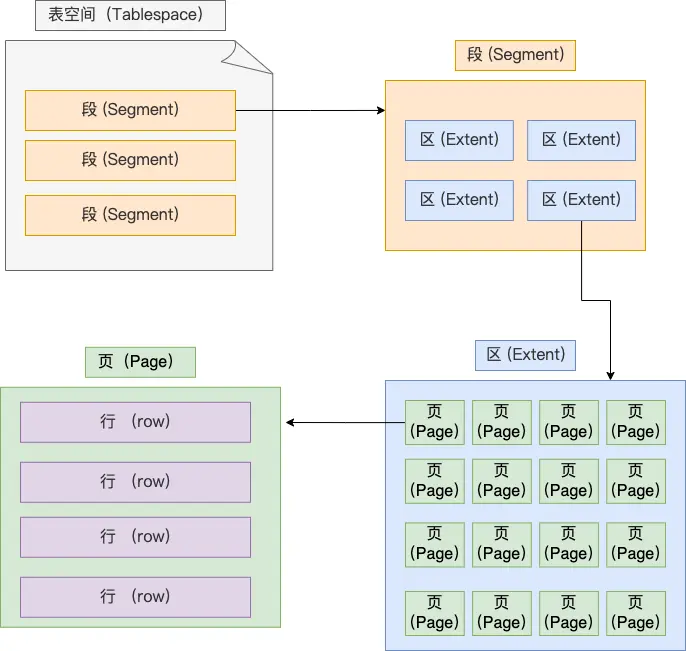
MySQL 的表空间结构?
表空间由:段、区、页、行 这四个基本结构组成
行(row)
数据库的 record 都是按照 行 来存储的
页(page)
如果数据读取的基本单位是 行 的话,每次只能读极少数据,会增加很多 IO 次数,效率低
InnoDB 存储引擎读取数据的基本单位是 页,一页的大小默认是 16K
数据页内,存储了很多行
每次读取数据,最少都要读取一页到内存,也就是 16K
区(extent)
B+ 树的每个节点就是一个数据页,其中,每层之间的节点组成一个双向链表
在查询时,可能涉及到读取多个数据页,如果这些数据页在磁盘不是连续的,那么会带来很多随机 IO,严重降低读写性能
因此,当数据量较大时,为索引分配空间就不能以页来分配了,而是按照 区 作为基本单位
一个区的大小默认为 1M,可以存放 64 个页,在这个区内的所有数据页的物理位置都是连续的
段(segment)
表空间是由若干个 段 组成的,一般分为:
- 索引段:存放索引数据
- 数据段:存放记录的数据
- 回滚段:用于 MVCC
InnoDB 的行格式有哪些?
InnoDB 提供了 4 种行格式,分别是 Redundant、Compact、Dynamic和 Compressed 行格式
- Redundant 太过古老,为 MySQL5.0 版本之前使用,性能不佳
- Compact 是一种紧凑的行格式,可以让一个页存放更多行数据
- Dynamic和 Compressed 是基于 Compact 改进的,在 5.7 版本后,默认使用的是 Dynamic 行格式
COMPACT 行格式

- 变长字段列表(可选):逆序 记录了每一变长字段的实际长度
- NULL 值列表(可选):逆序 记录了每列是否为 NULL
- 记录头信息(必需):包含信息较多,这里写几个重要的:
- delete_mask:标记该行数据是否删除(这里可以发现删除数据并不是马上删除)
- next_record:下一条记录的位置
- record_type:记录类型(普通记录、B+ 树非叶子节点记录、最小记录、最大记录)
- row_id(可选):如果没有主键,也没有 unique 列,那么 InnoDB 会为该表添加一个隐藏的 row_id 字段
- trx_id(必需):事务 id,记录了该行是哪个事务生成的
- roll_pointer(必需):指向上一个版本的指针
- 列 1、列 2…:记录每一列的数据
varchar(n) 的 n 的最大取值为多少?
首先弄清楚:n 并不是字节数,而是 字符数
MySQL 规定:除了 TEXT、BLOBs 这种大对象类型之外,其他所有的列(不包括隐藏列和记录头信息)占用的字节长度加起来不能超过 65535 个字节。
例如,假设要创建这样一个表:
CREATE TABLE test (
`name` VARCHAR(65535) NULL
) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT;
报错:

This includes storage overhead,这个 overhead 指的就是前面提到的:变长字段列表和 NULL 值列表
在这个示例中,NULL 值列表的大小为 1 字节(因为允许 name 为 NULL)
而变长字段列表的大小为 2 字节
「变长字段长度列表」所占用的字节数 = 所有「变长字段长度」占用的字节数之和。
所以,我们要先知道每个变长字段的「变长字段长度」需要用多少字节表示?具体情况分为:
- 条件一:如果变长字段允许存储的最大字节数小于等于 255 字节,就会用 1 字节表示「变长字段长度」;
- 条件二:如果变长字段允许存储的最大字节数大于 255 字节,就会用 2 字节表示「变长字段长度」;
因此,在本例的条件下,name 能存储的的最大值为 65535-1-2=65532 字节
而我们采用的又是 ascii 编码,每个字符占 1 字节,因此,n 的最大值为 65532
mysql> CREATE TABLE test1 (
-> `name` VARCHAR(65532) NULL
-> ) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT;
Query OK, 0 rows affected (0.02 sec)
如果我们采用 utfm8 编码,n 的最大值就不是 65532 了,因为 utf8 编码,每个字符占 3 个字节,那么 n 的最大值应该为 65532/3=21844:
mysql> CREATE TABLE test1 (
-> `name` VARCHAR(65532) NULL
-> ) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8 ROW_FORMAT = COMPACT;
ERROR 1074 (42000): Column length too big for column 'name' (max = 21845); use BLOB or TEXT instead
此外,一个表通常有多个字段,即使采用 ascii 编码,n 的值也应该 < 65532
总结:
- n 代表的是字符数,而不是字节数
- n 的最大值限制于编码方式、表的字段数等
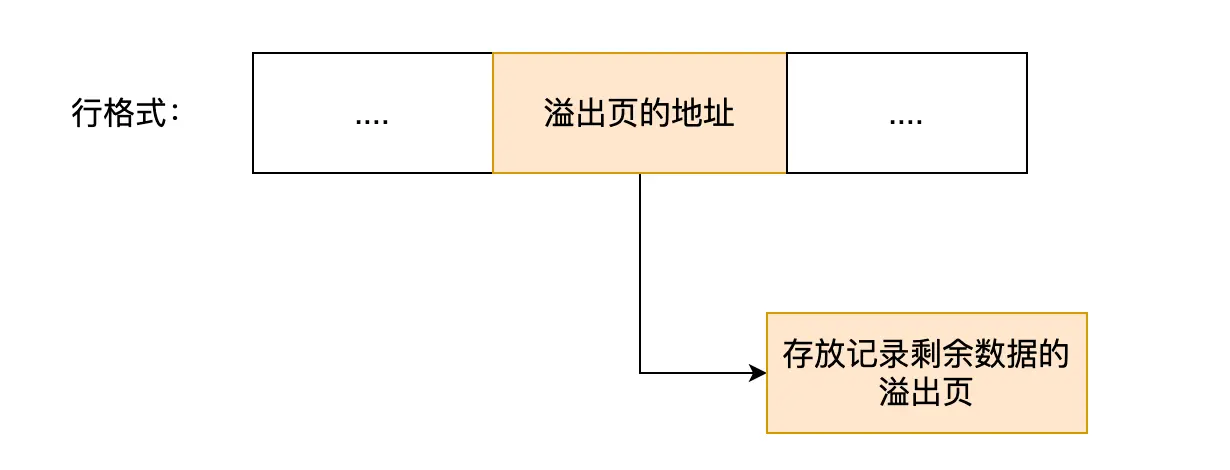
行溢出后,MySQL 是如何处理的?
如果表中包含了 TEXT、BLOB 字段,那么一行的数据可能会超过 65535 字节,此时就会发生行溢出
对于 COMPACT 行格式而言,如果发生行溢出,在记录的真实数据处,只会保存 该列 的 一部分数据,留 20 字节存储溢出页地址,多的数据会存储到溢出页中:
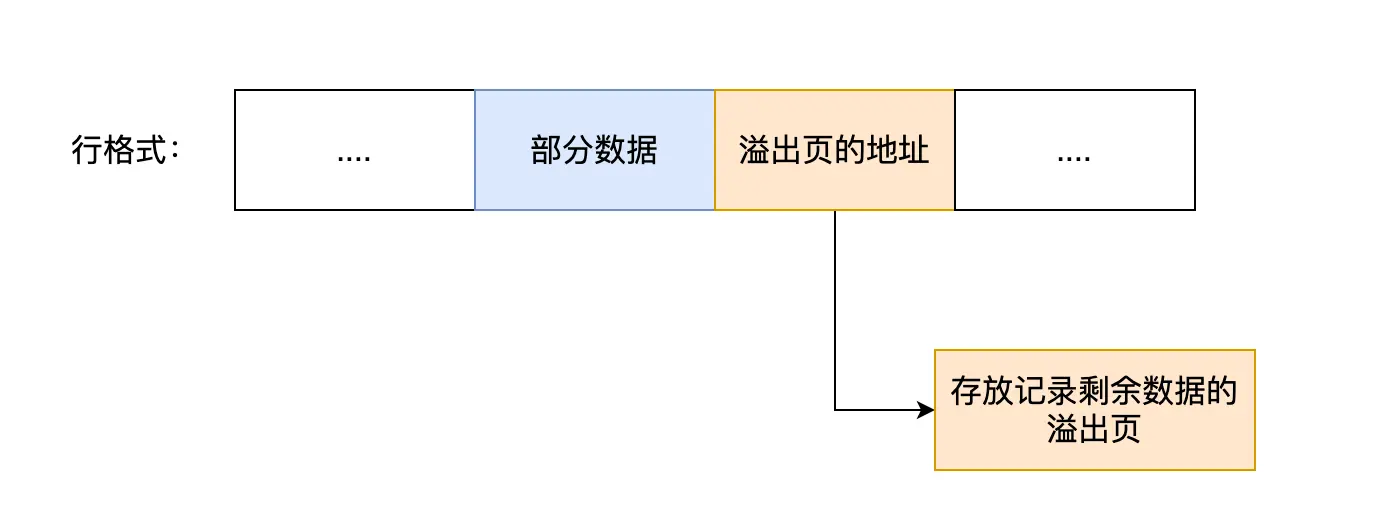
Compressed 和 Dynamic 这两个行格式和 Compact 非常类似,主要区别就在于对行溢出的处理
这两个行格式,如果发生行溢出,在记录的真实数据处,不会保存 该列 的数据,而是仅存储溢出页的地址,溢出页来负责存储实际数据