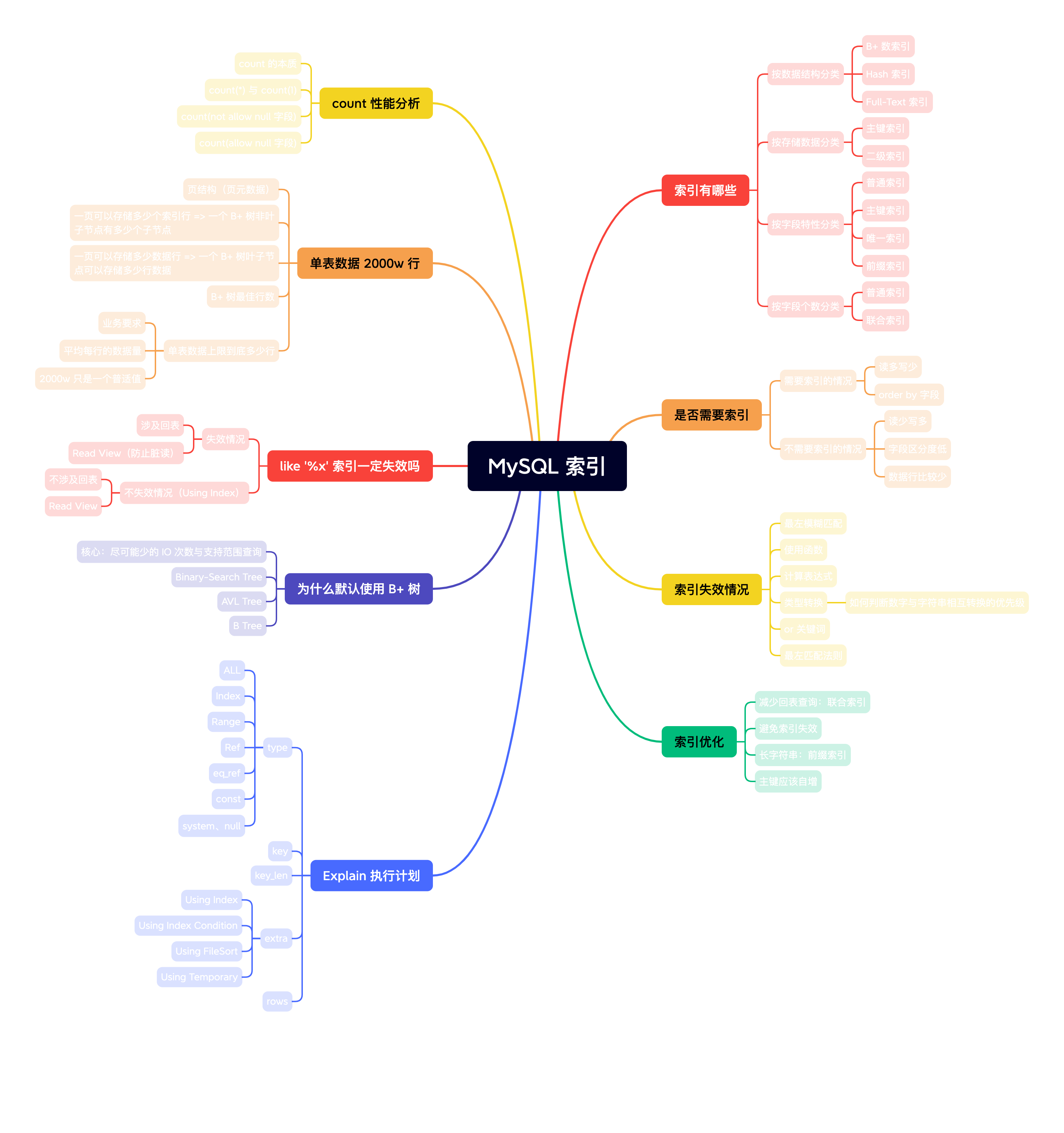
索引有哪些?
B+ 树索引、Hash 索引、Full-Text 索引、聚集索引、二级索引、主键索引、唯一索引、普通索引、前缀索引、单列索引、联合索引……
感觉有点懵 😳,下面来分析一波
按数据结构分类
索引按照数据结构,大致分为三类:
- B+ 树索引
- Hash 索引
- Full-Text 索引
B+ 树索引结构如下:
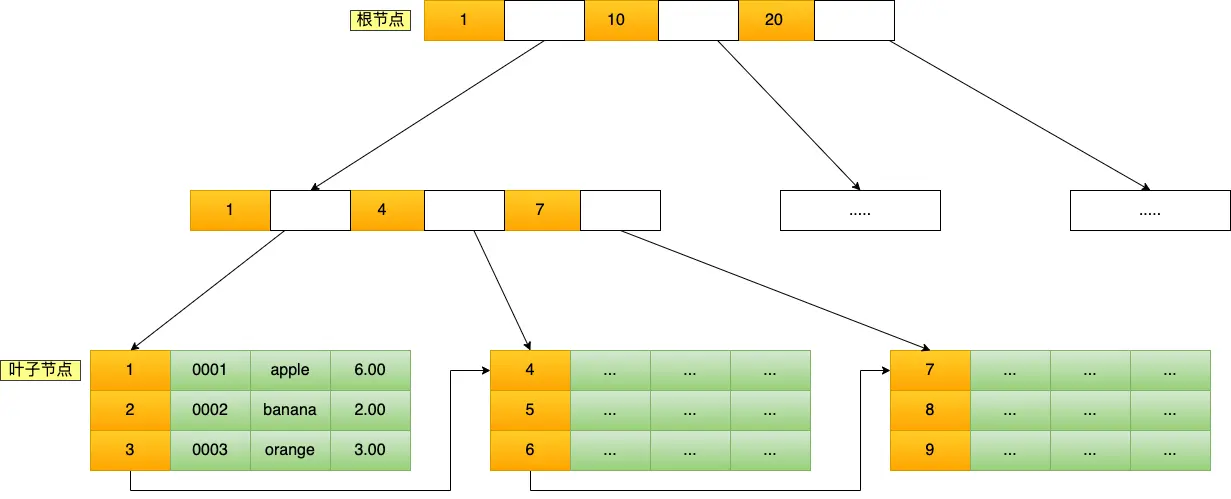
图片来自小林 coding 注意,叶子节点之间构成的双向链表,图中有误
B+ 树索引结构的 非叶子节点存储索引数据
- 如果是主键索引,叶子节点存储行数据
- 如果是二级索引,叶子节点存储主键 id
B+ 树索引结构相比 B 树、AVL 树而言,树的深度更浅(看起来更矮胖),这意味者只需要 更少的磁盘 IO 次数,就可以找到想要的数据
而 Hash 索引最大的优势在于可以在期望时间复杂度为 O(1) 的情况下,查找数据,但是 无法范围查询
Full-Text 索引主要用于大文本的索引
在不指定索引类型的情况下,创建索引时,InnoDB 默认创建的是 B+ 树索引
按存储数据分类
如果按照存储数据分类,可以分为:
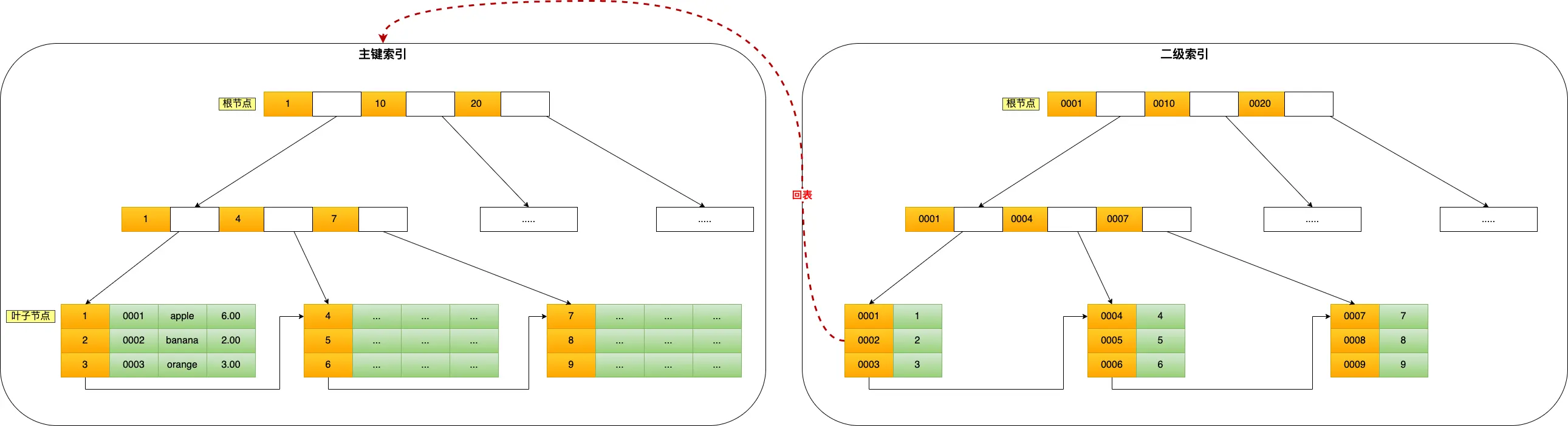
- 聚集索引,叶子节点存储行数据
- 二级索引,叶子节点存储主键 id
如果查询时,走的是二级索引,就有可能涉及到 回表查询:
按字段特性分类
如果按照字段特性分类,可以分为:
- 主键索引
- 唯一索引:以 unique 字段建立的索引
- 普通索引
- 前缀索引:在索引数据时,仅索引前面的部分数据
唯一索引
CREATE UNIQUE INDEX index_name
ON table_name(index_column_1,index_column_2,...);
前缀索引
使用前缀索引的目的主要是减少占用空间
CREATE INDEX index_name
ON table_name(column_name(length));
按字段个数分类
如果按照字段个数分类,可以分为:
- 单列索引
- 联合索引
联合索引指为多个字段建立索引,例如:
CREATE INDEX index_product_id_name ON product(product_id, name);
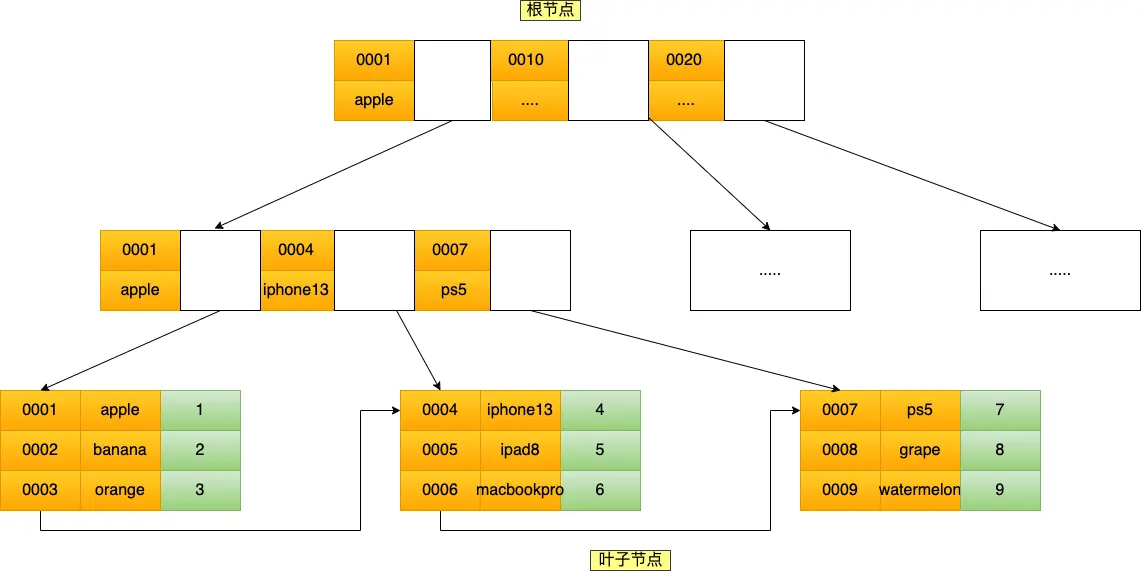
每个非叶子节点,存储的是 product_id、name 两个字段的值,且排序规则为:先按照 product_id 排序,如果 product_id 相同,再按 name 排序
对于 name 字段来说,是 整体无序,局部有序 的
因此,联合索引遵循 最左匹配法则
最左前缀法则:查询从联合索引的 最左列 开始,并且不跳过索引中的列如果跳过某一列,该列后面的索引将失效
- 对于 where product_id=1 and name = ‘iphone’,索引有效
- 对于 where name = ‘iphone’,索引无效
因此,在建立联合索引时,应该 将使用频率较高的字段放在前面,防止索引失效
此外,就算遵循最左匹配法制,联合索引也有可能失效
具体来说,联合索引中,出现范围查询(即 < 和 >),范围查询右侧的列索引失效
举个例子,假设有联合索引(profession,age,status)
-- 遵循最左匹配法则:profession,age,status 都存在
explain
select * from tb_user where profession = 'Engineer' and age > 20 and tb_user.status = 1;
输出:

key_len = 85,说明 status 索引没有用于加速
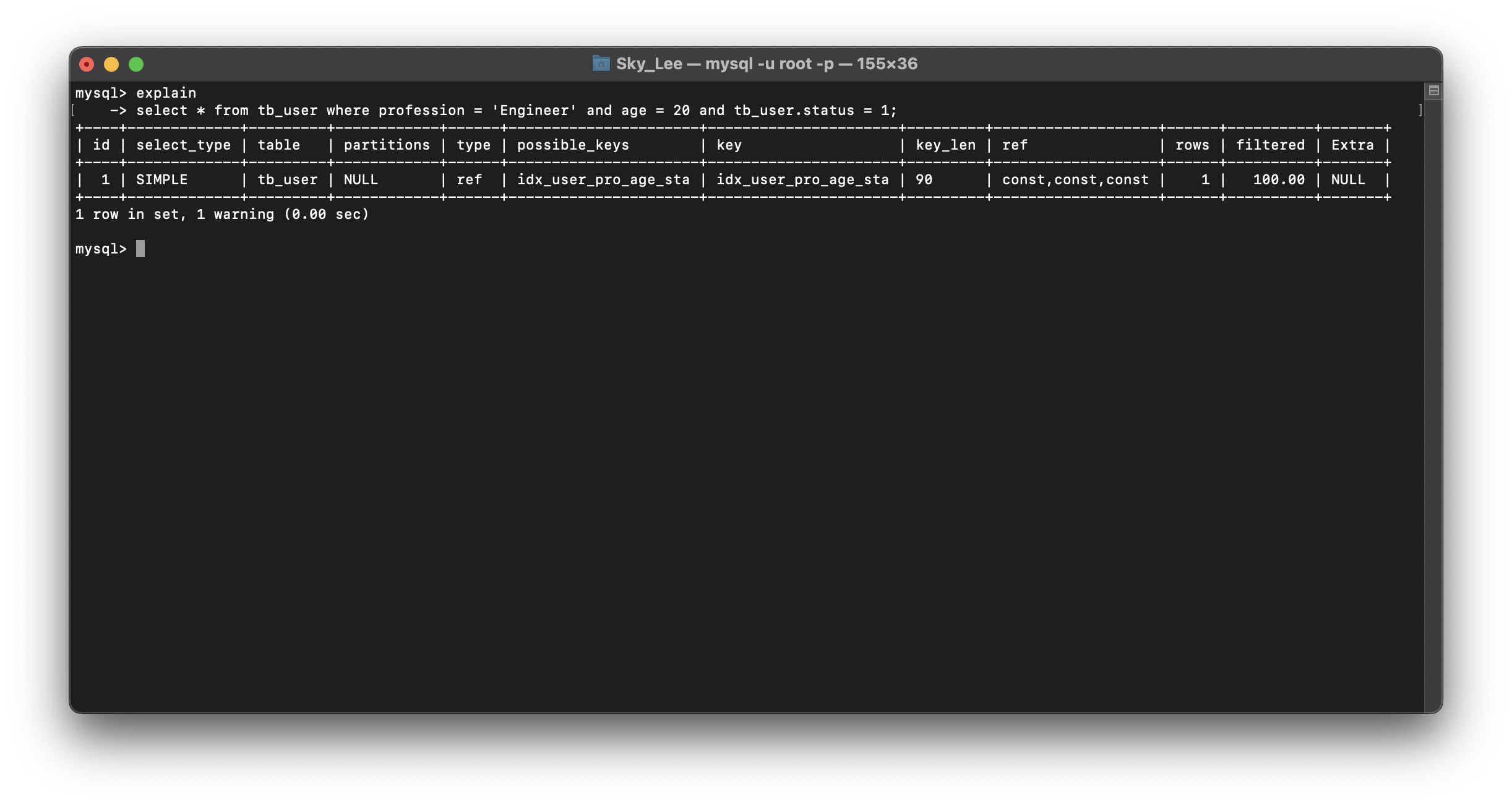
如果将 > 改成 >=,输出:

key_len = 90,说明 status 索引用于加速
因此,如果业务逻辑允许 >= 和 <=,尽量使用,避免索引失效
2024.3.31 更新
虽然使用
>=,key_len = 90,看起来 status 部分被用于加速了但是我们要关注 Extra 部分:Using Index Condition,说明使用了索引下推,在判断 status = 1 时,还是回表了的(在存储引擎层做的)
因此,这个 key_len = 90,更像是一种显示上的假象,status 部分并没有被用于加速
而 status 部分真正用上,输出应该像这样:
什么时候需要创建索引?什么时候不需要?
索引虽然可以带来读取速度的提升,但是也会带来一定的不良影响:
- 需要占用物理空间
- 降低增删改的效率,因为创建索引、维护索引需要时间
因此不是什么时候都能创建索引,使用索引的原则如下:
可以创建索引
- 字段有唯一性限制的
- 经常作为 where 条件的,如果有多列,可以建立联合索引
- 经常用于 order by 的字段,避免 file sort
不要创建索引
- 读少写多的场景:相比读取性能的提升,写操作性能下降可能更严重,收益不高
- 字段区分度低:比如性别字段,索引的区分度很小,字段的值分布均匀,无论搜索哪个值都可能得到一半的数据。在这些情况下,还不如不要索引。MySQL 有一个查询优化器,查询优化器发现某个值出现在表的数据行中的百分比(惯用的百分比界线是"30%")很高的时候,它一般会忽略索引,进行全表扫描。
- 表中数据少:全表查询也很快,建立索引反而浪费空间
在哪些情况下,索引会失效?
对索引字段使用最左模糊匹配
例如:where name = '%ack 或者 where name = %ack%
这两种情况,都会导致索引失效,转而使用全表查询
因为为 name 建立索引时,是按照 name 的 ascii 码排序的(从前往后,例如 ab < b < cd,最左模糊匹配当然会导致索引失效
对索引字段使用函数
例如 select id from users where length(name) = 6;
即使对 name 建立索引,走的仍然是全表查询,因为并没有给 length(name) 建立索引
MySQL8.0 开始支持了函数索引,可以单独对 length(name) 建立索引:
alter table user0 add key idx_len_name((length(name)))

对索引字段使用计算表达式
例如 select id from users where age - 1 = 10;
即使对 age 建立索引,走的仍然是全表查询,因为并没有给 age - 1 建立索引
MySQL 没有实现「优化」计算表达式,即将上面的 SQL 优化成 select id from users where age = 11;,而是需要我们自己优化
对索引字段隐式类型转换
例如 select id, phone from users where phone = 114514,其中 phone 的类型为 varchar(20)

虽然走了索引,但是类型为 index,还是要扫描整个索引树,与全表查询差不多,性能差
上面的 SQL 语句,实际上被翻译成:
select id, phone from users where CAST(phone AS signed int) = 114514
相当于对 phone 字段使用了函数,当然会造成索引失效
而对于:
select id, phone from user0 where id = '1';
是会走索引的:

因为翻译过来就是:
select id, phone from user0 where id = CAST("1" AS signed int);
并没有对 id 使用函数
补充:如何判断 MySQL 类型转换规则
执行下面的 SQL:
select '10' > 9
- 如果结果为 1,说明默认将字符串转换为数字
- 如果结果为 0,说明默认将数字转换为字符串
我本地执行的结果为 1,说明默认将字符串转换为数字,这也印证了上面 id,即主键索引没有失效
联合索引不遵循最左匹配法则
联合索引指为多个字段建立索引,例如:
CREATE INDEX index_product_id_name ON product(product_id, name);
每个非叶子节点,存储的是 product_id、name 两个字段的值,且排序规则为:先按照 product_id 排序,如果 product_id 相同,再按 name 排序
对于 name 字段来说,是 整体无序,局部有序 的
如果不遵循最左匹配法则,即跳过 product_id,直接使用 name 作为查询条件,由于 name 整体无序,联合索引自然失效
where 子句的 or
例如:select id from users where name = 'Jack' or age > 10,其中 name 建立了二级索引,但 age 没有索引
name 索引会失效,因为 OR 的含义就是两个只要满足一个即可,因此只有一个条件列是索引列是没有意义的,只要有条件列不是索引列,就会进行全表扫描。
怎么优化索引?
前缀索引优化
对于比较长的字段,如果要建立索引,可以建立前缀索引,以减少空间占用
但前缀索引也有局限性:
- order by 无法使用前缀索引,而是直接 file sort
- 无法实现覆盖索引(即避免回表查询)
上面两点不难理解,其本质原因还是因为字段的不完整性
覆盖索引优化
尽量使用覆盖索引,减少回表查询,例如 select id, name from users where name like 'n%';,其中 id 为主键,name 为普通索引
这句话就使用到了覆盖索引:在查询时,走 idx_name,不需要回表查询
此外,如果一个 SQL 要查询多个字段,如:select name, phone, sex from users where name like 'n%';,可以建立联合索引 idx_name_phone_sex 来避免回表查询
主键索引尽量自增
在设计主键时,最好保证主键是递增的
如果使用非递增主键,那么插入数据时,主键 id 完全是随机的,必须移动业内的其它数据来插入新的数据,还有可能出现一种叫做「页分裂」的现象
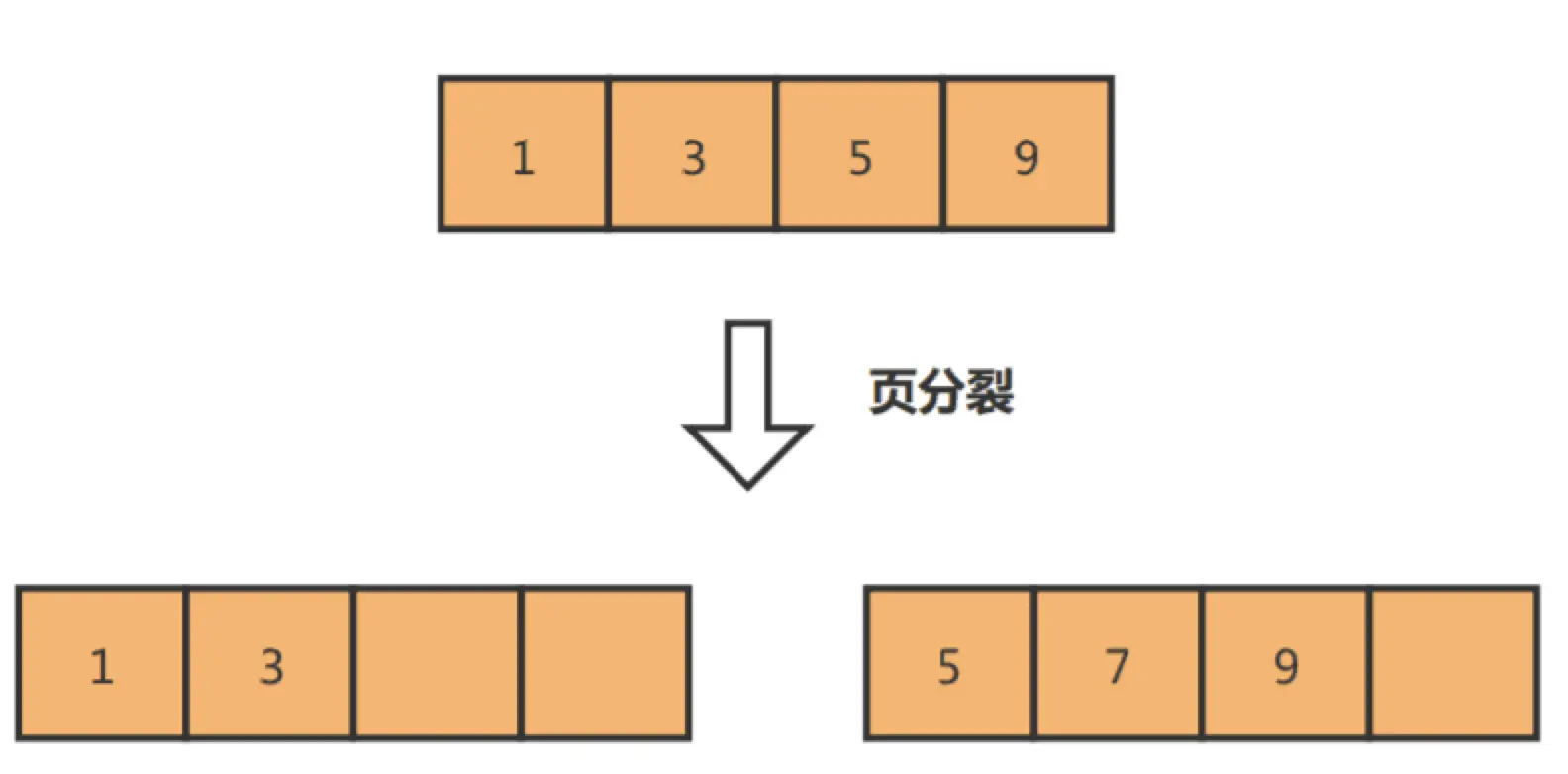
这种现象不仅影响性能,还会产生内存碎片,空间利用率不高
索引字段尽量 NOT NULL
索引列存在 NULL 就会导致优化器在做索引选择的时候更加复杂,更加难以优化
避免索引失效
设计索引时,要结合业务需求,避免建立的索引失效,不仅不能提高查询效率,还会降低增删改的性能
如何判断一个查询语句的索引使用情况?
使用 explain 执行计划可以查看一个 SQL 语句索引的使用情况
例如:
explain
select * from User order by id;
输出:
mysql> explain
-> select * from User order by id;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| 1 | SIMPLE | User | NULL | index | NULL | PRIMARY | 4 | NULL | 4 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
type(重点)
在 MySQL 的 EXPLAIN 查询计划中,type 字段表示查询操作使用的访问类型(Access Type)。type 字段的值描述了 MySQL 优化器选择用于执行查询的访问方法,它是评估查询性能和优化查询的关键指标之一。
以下是 type 字段可能出现的常见值及其含义:
-
ALL:全表扫描,表示查询将扫描全表的所有行。这是最慢的访问类型,通常应该尽量避免。 -
index:索引扫描,表示查询将扫描整个索引树,但不需要访问表的数据行。这比全表扫描快,但仍需要较多的 IO 操作。例如上面的示例,基于 id 来排序 -
range:范围扫描,表示查询将在索引树中扫描一个范围的索引值,而不是整个索引。 -
ref:基于非唯一索引的等值查找,表示查询将使用一个非唯一索引来定位数据行。 -
eq_ref:基于唯一索引的等值查找,表示查询将使用一个唯一索引来定位数据行。 -
const:常量查找,表示查询使用一个常量条件(例如主键或唯一索引条件),只返回一行结果。 -
system:表中只有一行(或零行),表示查询将只访问一行数据。 -
NULL:在一些特殊情况下,type字段的值可能为NULL,表示查询无效或无法优化。
一般来说,我们希望查询使用 const、eq_ref 或 ref 等基于索引的访问类型,而不是 ALL 或 index 这样的全表扫描或索引扫描类型。
其它
- possible key(重点):可能用到的索引
- Key(重点):实际使用的索引,如果为 NULL,则没有使用索引。
- Key len(重点):表示索引中使用的字节数,该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好。
- rows:MySQL 认为必须要执行查询的行数,在 innodlb 引擎的表中,是一个估计值,可能并不总是准确的。
- filtered:表示返回结果的行数占需读取行数的百分比,filtered 的值越大越好。
还有一个 Extra 字段也需要关注:
- Using filesort:通常出现在 order by 中,如果 order by 的字段没有建立索引(或者建立的是前缀索引),那么就会出现 filesort,意味着可能在文件内进行排序,效率低,应该避免
- Using temporary:使用临时表保存中间结果,MySQL 在对查询结果排序时使用临时表,常见于排序 order by 和分组查询 group by。效率低,要避免
- Using Index Condition:虽然用了索引,但是还是要回表查询(索引下推)
- Using Index:所需数据只需在索引即可全部获得,即覆盖索引,不需要回表
MySQL 为什么默认使用 B+ 树存储索引和数据?
一步一步分析
MySQL 除了支持精确查询外,还支持 范围查询,对查询数据 排序
也就是说,MySQL 的查询需求:
- 尽量少的磁盘 IO
- 支持精确查询,也要支持范围查询,还能高效排序
二叉搜索树
二叉搜索树可以满足第二个需求,在精确查询某个数据,期望时间复杂度是 O(logn),n 待查询数据的深度
也可以范围查询:先查询第一个边界值,然后中序遍历直到第二个边界值
也可以高效排序:二叉搜索树的中序遍历本身就是有序的
但是,二叉搜索树存在 失衡问题,即树的高度可能失衡,退化成一个链表,这样查询数据的最坏时间复杂度就为 O(n) 了,效率低
AVL 树
为了避免二叉搜索树的失衡,出现了 AVL 树,即自平衡的二叉搜索树
虽然解决了失衡问题,但是随着数据的增多,树的深度也更深,这意味着可能需要更多的磁盘 IO 次数才能读取到目标页
B 树
AVL 树,本质还是一棵二叉树,只有两个子节点
而 B 树就不一样了,在 AVL 树的基础上,引入了「阶」的概念,即可能有多个子节点,这在一定程度上解决了 AVL 树的深度问题
B+ 树
单点查询
B 树的每个节点除了包含索引数据外,还包含了记录(行数据),这意味着:在页的大小相同的情况下,存放的索引数据较少,那么子节点的数目更少,存储相同的数据,树的深度更深
而 B+ 树只有叶子节点存放记录,非叶子节点只存放索引数据,那么一个非叶子节点就可以有更多的子节点,使得 B+ 树的深度比 B 树更浅,看起来更加「矮胖」
这样,查询单个数据,平均磁盘 IO 的次数 相较 B 树更少
范围查询
如果要范围查询,B 树需要中序遍历很多节点,性能不太理想
而 B+ 树的叶子节点之间构成「双向链表」,如果要范围查询,只需要定位到第一个叶子节点,然后遍历链表直到不满足范围要求
数据的插入与删除
B 树在插入和删除数据时,树形变化可能较大,这会带来一定性能开销
而 B+ 树由于节点数据时冗余的,插入和删除数据时,树形变化较小
MySQL 单表行数不要超过 2000w 行?
页结构
首先来看看 MySQL 的页结构
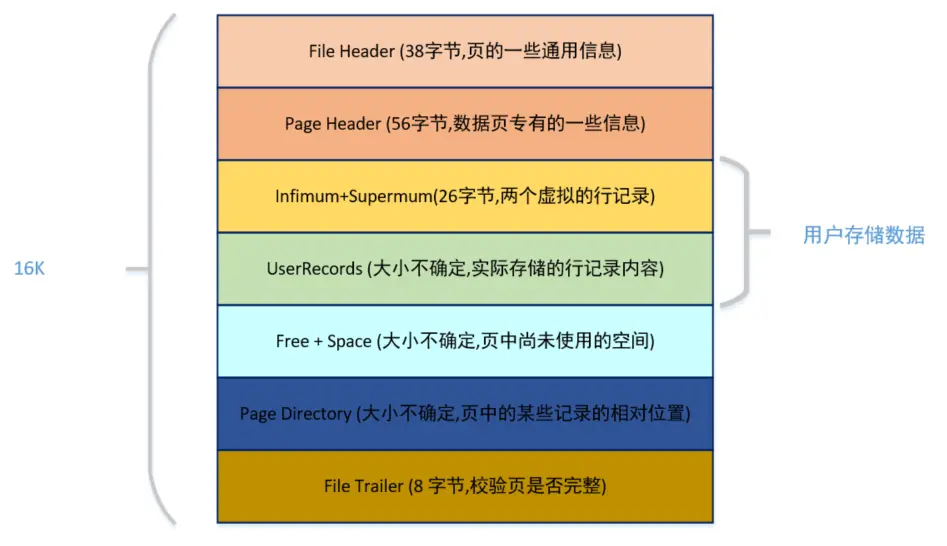
每一页记录的数据,除了包含我们的用户数据,还要包含其它元数据
索引结构
再来看看主键索引结构:
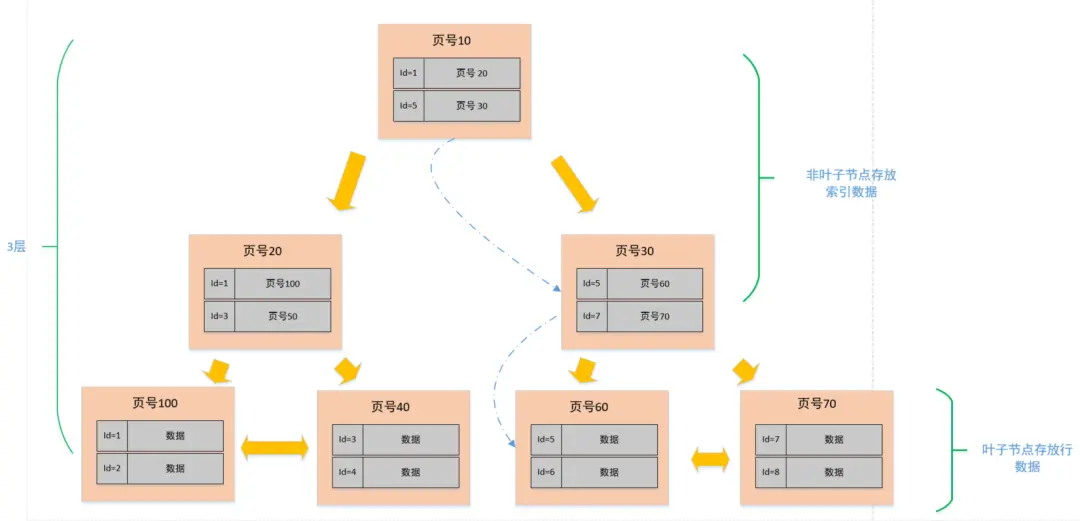
每个索引的非叶子节点记录了索引数据,即页号 + 对应页的主键 id 的最小值,在根据主键 id 查询数据时,就可以使用到这些节点加速
叶子节点记录了主键 id + 行数据
理论行数上限
假设:
- 非叶子节点记录的索引数据有 x 行
- 树的深度为 d
- 每个叶子节点能记录的数据有 y 行
那么,一颗深度为 d 的 B+ 树的理论行数为
x^(d-1)*y
那么 x、y 的值怎么确定呢?
下面的计算,页的大小都为 16K
x 的值
页结构告诉我们:每页的元数据大概会占用 1K 左右的空间
那么剩余空间还有 15K
每一个索引数据由 页号 + min_id 组成
假设页号占 4 字节,id 为 bigint,占 8 字节,那么一个索引数据就是 12 字节
因此,x 的值为:(16K - 1K) / (4 + 8) = 1280 行
y 的值
与非叶子节点一样,叶子节点用于记录真实行数据的空间也是 15K
由于每张表,字段不同,数据也不同,每一行的大小也不同,因此,y 的值也会有较大差异
这里假设每一行的数据为 1K,那么 y 的值为 15
理论行数上限
在上面的条件下,假设 B+ 树的高度为 3,那么理论行数上限值为:1280^(3-1)*15,约为 2450w 行,与「建议值 2000w」差不多
MySQL 单表行数不要超过 2000w 行?
如果树的高度超过 3,那么每查询一个行数据,就要多一次磁盘 IO,对性能的影响很大,因此,尽量让树的高度 <= 3
经过上面的分析,我们发现:在 单行数据约为 1K 的情况下,如果要保证树的高度 <= 3,那么最多就只能存放约 2450w 行的数据
因此这个 2000w 行还是有依据的,但是也要结合实际情况:
- 如果每行数据较大,那么在保证树的高度小等于 3 的情况下,单表行数就不能达到 2000w 行
- 如果业务可以接受较高延迟,那么单表也可以存放超过 2000w 行的数据
因此,2000w 这个值是一个普适性的建议值,能够保证基本查询性能,也符合大部分业务需求
MySQL 使用 like “%x“,索引一定会失效吗?
对于这个查询语句:
select * from user0 where name like '%ack';
如果 name 字段建立了索引 idx_name,索引一定会失效吗?
场景一
这是一个一般场景:
create table user1 (
id int primary key ,
name varchar(10),
age tinyint
);
create index idx_name on user1(name);
执行 explain 执行计划:
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | user1 | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
可以发现,索引失效了,走的全表查询
场景二
这个场景比较特殊:
create table user0 (
id int primary key ,
name varchar(10)
);
create index idx_name on user0(name);
可以发现:user0 只有两个字段
执行 explain 执行计划:
mysql> explain select * from user0 where name like '%ack';
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | user0 | NULL | index | NULL | idx_name | 43 | NULL | 1 | 100.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
可以发现,idx_name 并没有失效,type 为 index,即全扫描 idx_name 索引树
为什么?
因为 user0 只有 id、name 两个字段,select * from user0 这个操作 等价于 select id, name from user0,不涉及回表查询
由于二级索引相较于主键索引,更加轻量(主键索引的叶子节点还要记录 trx_id、roll_pointer),在 不涉及回表 的情况下,查询性能更好
因此,优化器决定使用 idx_name,而不是全表查询(即使用主键索引)
但是,即使使用了 idx_name,类型还是为 index,性能也是比较差的,只是比全表好一点点。。。
此外,对于 user1 表,如果是 select id, name from user1,还是会走 idx_name 的,理由与上面一致
补充
select * from user0 where name like '%ack' 一定会走索引 idx_name 吗?
实际上也不一定,前面提到了,idx_name(二级索引)不包含 trx_id、roll_pointer
如果直接走二级索引,可能出现「脏读」问题
MySQL 对于二级索引所在的数据页有一个 Page Header 的结构,里面含有一个名为 PAGE_MAX_TRX_ID 的字段,这个字段标明了修改当前索引页面的最大事务 ID,当查询进来的时候会先判断本次 Read View 的 min_trx_id 跟 PAGE_MAX_TRX_ID 的关系,如果 min_trx_id > PAGE_MAX_TRX_ID,说明 PAGE_MAX_TRX_ID 对应的事务已经提交了,就可以走二级索引,否则就要回聚簇索引里面拿更详细的信息做判断。
count(*)、count(1) 、count(主键字段) 、count(其它字段) 有什么区别?性能如何?
- count(*)
- count(1)
- count(主键字段)
- count(其它字段,not null)
- count(其它字段,可以为 null)
- count(其它字段,not null,有索引)
- count(其它字段,可以为 null,有索引)
首先要弄清楚 count 函数的作用:统计某个字段不为 NULL 的行数
其查询的本质是 遍历整个索引树 的叶子节点
count(*) 实际上与 count(1) 等价(包括性能),不涉及到任何字段,即统计整张表的行数
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
因此,count(*) 在遍历索引树节点时,每从 InnoDB 读取到一条记录,Server 不会将字段值取出来,而是直接将 count + 1
而 count(主键字段) 实际上作用与 count(*) 是一样的,都是统计整张表的行数,因为主键不能为 NULL
因此,count(主键字段) 的性能与 count(*) 基本一致
而 count(其它字段),就要看看是否允许该字段为 NULL 了:
- 如果不允许为 NULL,那么性能与
count(主键字段)基本一致 - 如果允许为 NULL,那么 Server 每从 InnoDB 读取到一条记录,需要将字段值取出来,判断是否为 NULL,如果不为 NULL,将 count + 1,性能较差
理论分析完毕,做个实验:
-- 创建 test 表
create table test(
id int primary key auto_increment,
col_not_null varchar(10) not null,
col_null varchar(10)
);
-- 创建存储过程,用于插入 100w 行数据
DELIMITER $$
CREATE PROCEDURE InsertTestData(i int, j int)
BEGIN
WHILE i <= j DO
INSERT INTO test (col_not_null, col_null) VALUES (CONCAT('Val', i), (CONCAT('Val', i)));
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
-- 插入 100w 行数据
CALL InsertTestData(1, 1000000);
现在依次执行:
select count(*) from test;
select count(1) from test;
select count(id) from test;
select count(col_not_null) from test;
select count(col_null) from test;
每条语句执行 5 次,平均查询时间如下:
| 类型 | 平均查询时间 |
|---|---|
| count(*) | 98.2ms |
| count(1) | 97.2ms |
| count(id) | 93.2ms |
| count(col_not_null) | 93.2ms |
| count(col_null) | 326.8ms |
可以发现,count(*)、count(1) 、count(主键字段)、count(其它字段,not null) 四者性能接近,而 count(其它字段,可以为 null) 的性能差
因此在 只有主键索引 的情况下,可以得出以下结论:
性能排行
count(*) = count(1) ≈ count(主键字段) ≈ count(其它字段,not null) >> count(其它字段,可以为 null)
此外,网上有人说:对于确实要统计可以为 null 的字段的 count,可以对这个字段建一个二级索引,避免走主键索引遍历(二级索引要轻量一些)
对 col_null 建一个二级索引后, count(col_null) 5 次平均执行时间为 313ms,看起来似乎快了一些
但是 业务需求如果就是查询该字段的 count,并且 表的数据量比较少(比如本例的 100w 行数据),建立索引带来的收益还比不上建立索引带来的开销
可以认为:建立索引基本上不会对 count 的性能有太大的提升
count 的性能主要取决于目标字段是否允许为 null
那如果就是要统计可以为 null 的字段的 count,怎么优化?
如果业务允许一定的误差,可以使用 explain 执行计划,来 模糊查询
mysql> explain
-> select count(col_null) from test;
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | test | NULL | index | NULL | idx_col_null | 43 | NULL | 998602 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+--------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
在 rows 字段,给出了模糊值 998602,整个统计时间为 0.00 sec,非常快