主从复制
常见主从模型
常见的主从模型有以下几种:
- 一主一从
- 一主多从
- 互为主从

主从复制原理
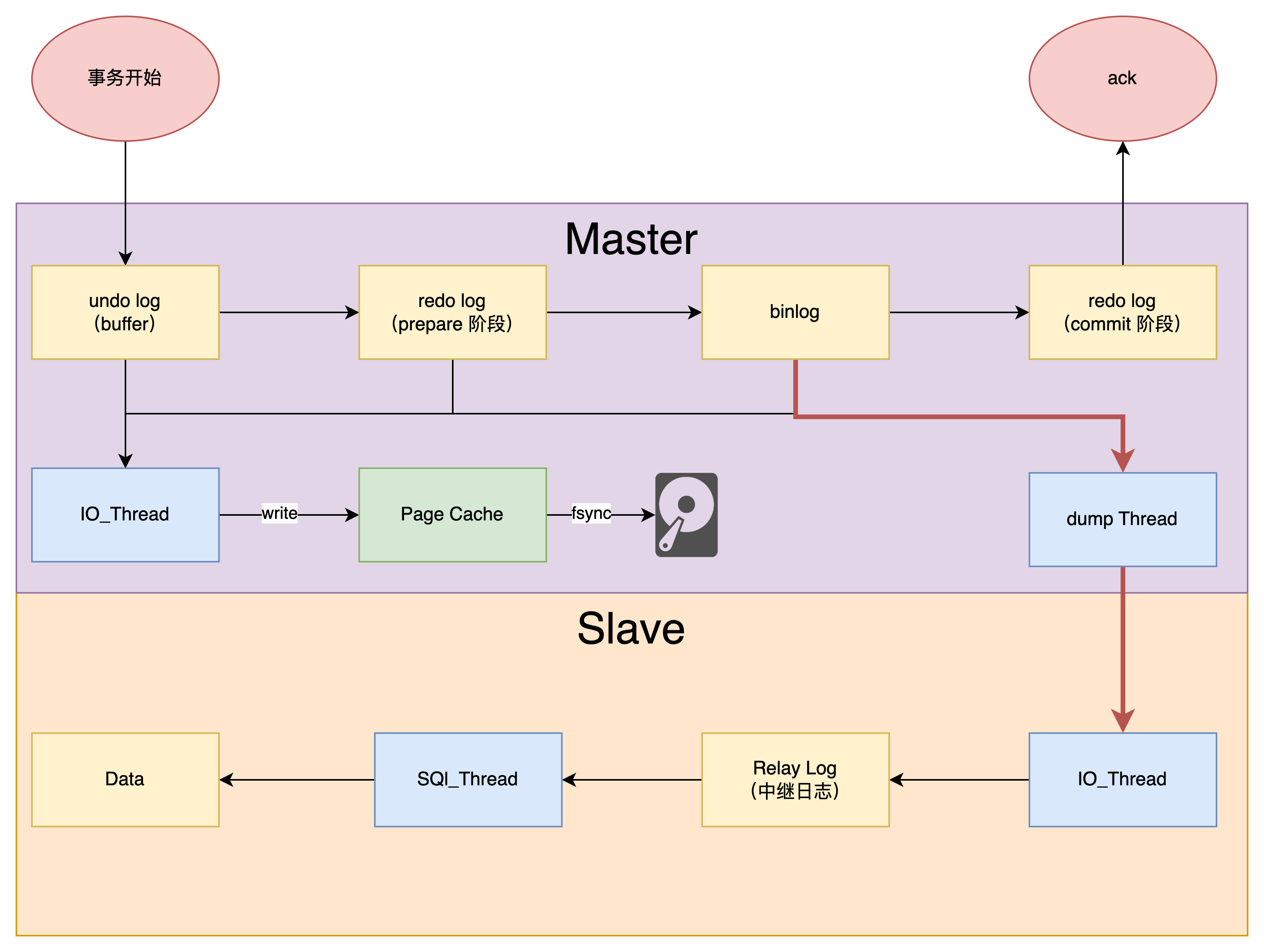
简单来说,就是从库的 IO_Thread 将主库发来的 binlog 写到本地的 relay log,然后由 SQL_Thread 负责拉取 relay log 完成主从复制
binlog 是主库主动推送,还是从库主动拉取?
一开始创建主备关系的时候,是由备库指定的。
比如基于位点的主备关系,备库说“我要从 binlog 文件 A 的位置 P”开始同步, 主库就从这个指定的位置开始往后发。
而主备复制关系搭建 完成以后,是 主库 来 决定“要发数据给备库” 的。
所以主库有生成新的日志,就会发给备库。
循环复制
生产上常常使用双主(互为主从)结构,这样主节点宕机了,还可以切换到从节点,保证可用性
但双主结构存在一个 循环复制 的问题:
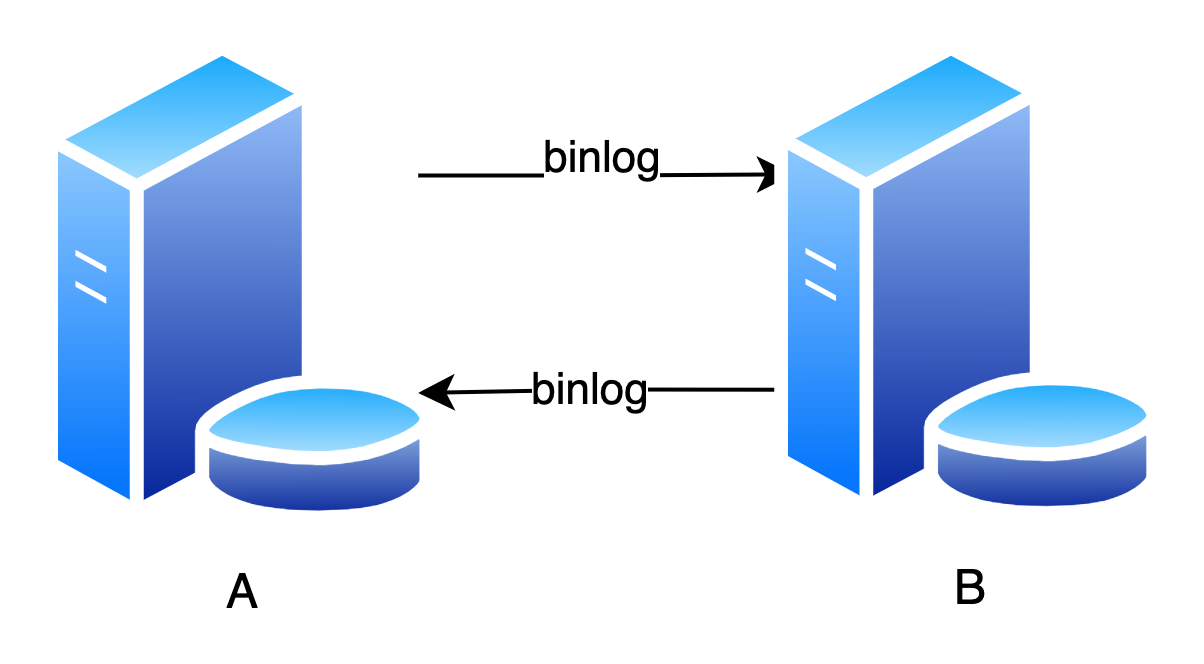
假设一个业务代码向 A 库写入了一个数据,那么 A 库会产生相应的 binlog,并发送给 B 库
B 库收到 A 库的 binlog,也会写入这个数据,并生成相应的 binlog(建议将 log_slave_updates 设置为 on,表示从库执行 relay log 以后,也会生成 binlog)
B 库当然要把最新的 binlog 发给 A 库,但这个 binlog 记录的数据是 重复 的
如果 A 库再执行一次这个 binlog,就相当于循环复制了
如何解决这个问题?
事实上,binlog 还 记录了生产该日志的 server id,如果收到的 binlog 的 server id 与自己是一样的,就不执行
因此,要避免循环复制,需要:
- 每个库的 server id 不同
- 从库重放 binlog 时,生成的新 binlog 的 server id 必须与原 binlog 一致
那么,保证了上面两点就能绝对避免循环复制吗?
并不是
场景一
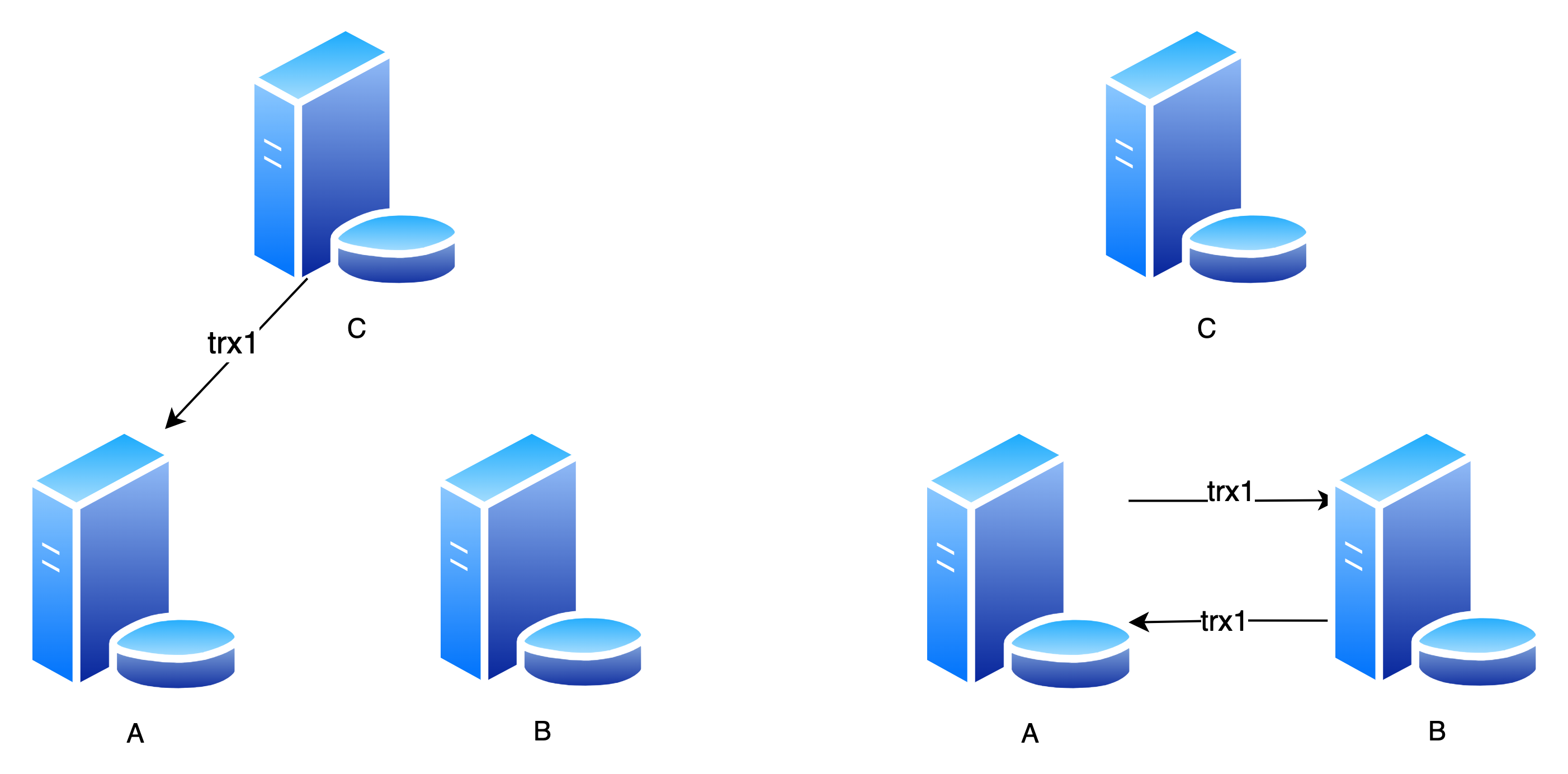
trx1 是在 C 库执行的,server_id 为 C 库的 server_id
然后,A、B 搭建成双主结构,由于 server_id 不是 A、B,因此循环复制
解决方法就是:临时忽略 C 库的 server_id
可以在 A 或者 B 上执行:
stop slave;
CHANGE MASTER TO IGNORE_SERVER_IDS=(server_id_of_C);
start slave;
这样这个节点收到这个 binlog 就不会执行,也就避免了循环复制
同步完毕以后再改回来
场景二
如果主库发送完 binlog 之后,修改了自己的 server id,等 binlog 传回来以后,就会认为自己的 server id 与 binlog 中的 server id 不一致,造成循环复制
那为什么还要允许运行时修改 server id 呢?设置为只读不就解决了?
逆向修改 server_id,反而可以解决死循环问题
例如上面的示例:可以将 A 库的 server_id 临时修改成 C,不就避免了死循环吗
主从延迟
从库要想同步主库的数据,肯定需要一定的时间,这段时间就叫做主从延迟时间
主从延迟期间,如果有客户端读取从库的数据,可能会读取到旧数据,因此,需要尽可能缩短主从延迟
可以通过在从库执行
show slave status来查看 seconds_behind_master(SBM)的值
出现场景
将整个主从复制分为三个时间点:
- 主库完成一个事务,写入 binlog,这个时刻记做 T1
- 从库收到主库的 binlog,记做 T2
- 从库执行完这个事务,记做 T3
那么主从延迟的时间 T = (T2 - T1) + (T3 - T2)
T2 - T1 比较好理解:就是 网络延迟时间,如果网络波动比较大,有可能造成主从延迟时间较长,一般来说,网络延迟时间是比较短的,也不太好优化
所以,主从延迟的原因主要取决于:从库接收到 binlog 到处理完事务的时间差
T3 - T2 又可以细分:
- IO_Thread 写入 relay log 的过程
- SQL_Thread 执行 relay log 的过程
来讨论一下一些导致 T3 - T2 时间较长的场景:
从库性能太差
一般来说,为了保证业务的可用性,我们总是偏向于提高主库的配置,从库的配置可能较低
例如:主库使用 SSD,而从库使用 HDD,写入速度太慢,IO 造成瓶颈
解决方案:
现在一般讲究一个「对称部署」,为了保证可用性,主库挂了,从库随时要来顶住,因此主库与从库配置相同
从库压力太大
我们遇到的大多场景都是读多写少
如果做读写分离:主库 write only,从库 read only
从库同步的过程中,如果读的 QPS 太高了,从库压力太大,CPU、IO 都被大量读请求占用,自然主从延迟就变高了
解决方案:
部署多个从节点,将读请求分发到不同的从节点上,降低单个从节点的压力(当然数据不一致的可能也相应增加)
大事务
例如一个事务在主库执行 10min,那么只有等到这个事务执行完毕以后,才会写入 binlog
从库收到这个 binlog,也需要花较长时间才能执行完这个事务,这个期间,主从都是不同步的
因此,总是听到:“不要一次性 delete 太多数据”
解决方案也很简单:就是避免大事务的产生
从库的并行复制能力
这里的「复制」指的是 SQL_Thread 执行 relay log 的过程
早期的 MySQL(5.6 版本之前)SQL_Thread 是单线程的
如果 binlog 很多,单线程可能就处理不过来了,造成积压,主从延迟升高
为什么从库会延迟好几个小时?
如果从库的 复制能力太弱,就有可能出现这种延迟几个小时的情况
为了提高复制能力,很容易想到多线程处理
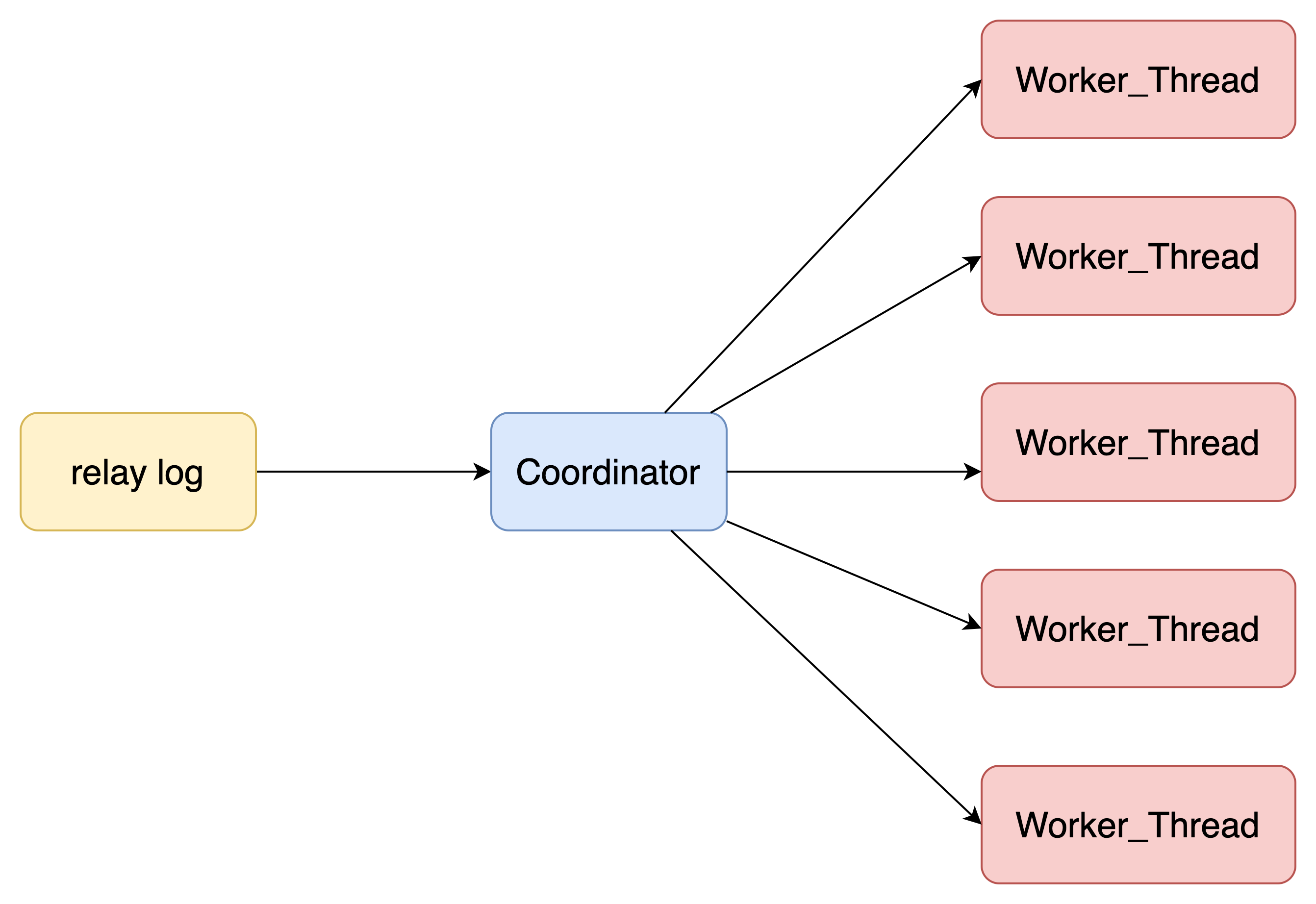
SQL_Thread 变成了一个 Coordinator 和若干个 Worker Thread
Coordinator 不负责 relay log 的实际处理,而是负责将 relay log 分发到不同的 Worker
Worker 就专注于执行事务就可以
那么重点来了:Coordinator 分配 relay log 的原则是什么?
- 不能产生更新覆盖,这就要求对同一行的更新事务,必须放在同一个 Worker 中
- 同一个事务不能拆开,只能由一个 Worker 处理
第一点的「更新覆盖」的场景:
两个事务,都想修改第 row 行的数据
- 事务 A 先执行,将这一行的数据修改为 data0
- 事务 B 后执行,将这一行的数据修改为 data1
在主库,更新顺序为 A->B,那么在从库,这个顺序也应该是 A->B,否则可能出现主从不一致问题
5.6 版本 MySQL 解决方案
5.6 版本的 MySQL 引入了并行复制,即 SQL_Thread 变成了多线程,但是粒度比较粗,是 基于「库」的,不同库的事务肯定是可以并行执行的
这个方式在每个库的负载都比较均衡的场景下比较有用,能起到不错效果
但是,如果业务上就一个库,或者不同 DB 的热点不同,比如一个是业务逻辑库,一个是系统配置库,那就起不到并行的效果。
5.7 版本 MySQL 解决方案
因此,5.7 版本的 MySQL 又额外引入了一种策略:LOGICAL_CLOCK,基本思想如下:
- 如果主库的两个事务都处于 prepare 状态,那么这两个事务可以在从库上并行执行
- 如果主库的两个事务,一个处于 prepare,一个处于 commit,那么这两个事务可以在从库上并行执行
只要若干个事务同时处于 prepare 状态(包括 commit 状态),那么说明这些事务肯定是客户端发起了 commit 请求,自然可以并行执行
这种方案比起 5.6 版本的方案,更具有适用性
还可以调整 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 参数(这两个参数是用于控制 fsync 的),来延长 prepare 状态的时间,以此产生更多「同时」处于 prepare 状态的事务,进而提交从库的并发度
但是这个方式还存在局限:
假设一个主库,单线程插入了很多数据,过了 3 个小时后,我们要给这个主库搭建一个相同版本的备库。
由于已经过了 3 个小时,此时同时处于 prepare 状态的事务可以说是很少的,绝大多数事务已经被提交了
此时如果采用 LOGICAL_CLOCK 策略,从库的复制过程就退化成单线程了,效率不高
5.7.22 版本 MySQL 解决方案
为了解决上面这个场景的问题,5.7.22 版本 MySQL 引入了 WRITESET 策略,基本思想如下:
在主库,对于一个事务涉及到的 每一行,计算出这一行 库名 + 表名 + 索引名 + 值 的哈希值
将这些哈希值组成一个 write_set 集合,写到 binlog 里面
从库收到 binlog,coordinator 会看看两个事务的 write_set 有没有交集:
- 如果没有交集,说明这两个事务涉及完全不同的行,可以并行操作
主从切换
来看看主从切换的大体步骤:
- 从库循环检查自己的 SBM 是否小于某个值(比如 5s),如果小于,进入下一步
- 将主库设置为 Read Only
- 从库继续同步数据,知道 SBM 等于 0
- 将从库设置为可读写
- 将业务请求切换到从库
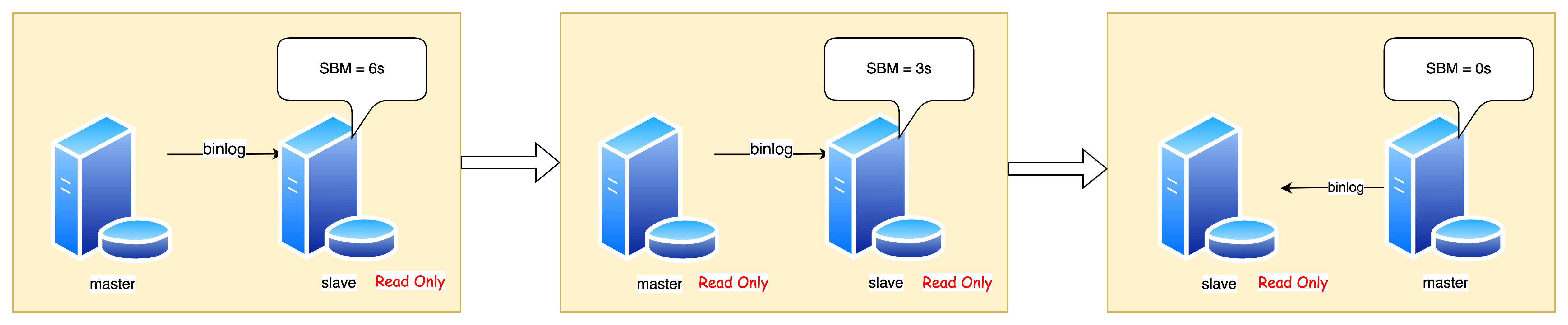
可以看到,在主从切换期间,是存在 服务不可用 的:主、从均处于 Read Only
如果要确实要保证下游服务的可用性,并且可以接受短期的数据不一致,可以直接将从库设置为可读写,然后把请求路由到从库,从库后台同步主库的数据,最后完成切换(不推荐)
可以看出 MySQL 的可用性,很大一部分因素在于主从延迟,如果一开始 SBM 就比较短,那么整个切换过程中,服务不可用的时间就很短了
主库出问题,从库怎么办?
主库出问题,从库怎么办?
按照正常流程,应该要选举出一个从节点,然后走主从切换的流程
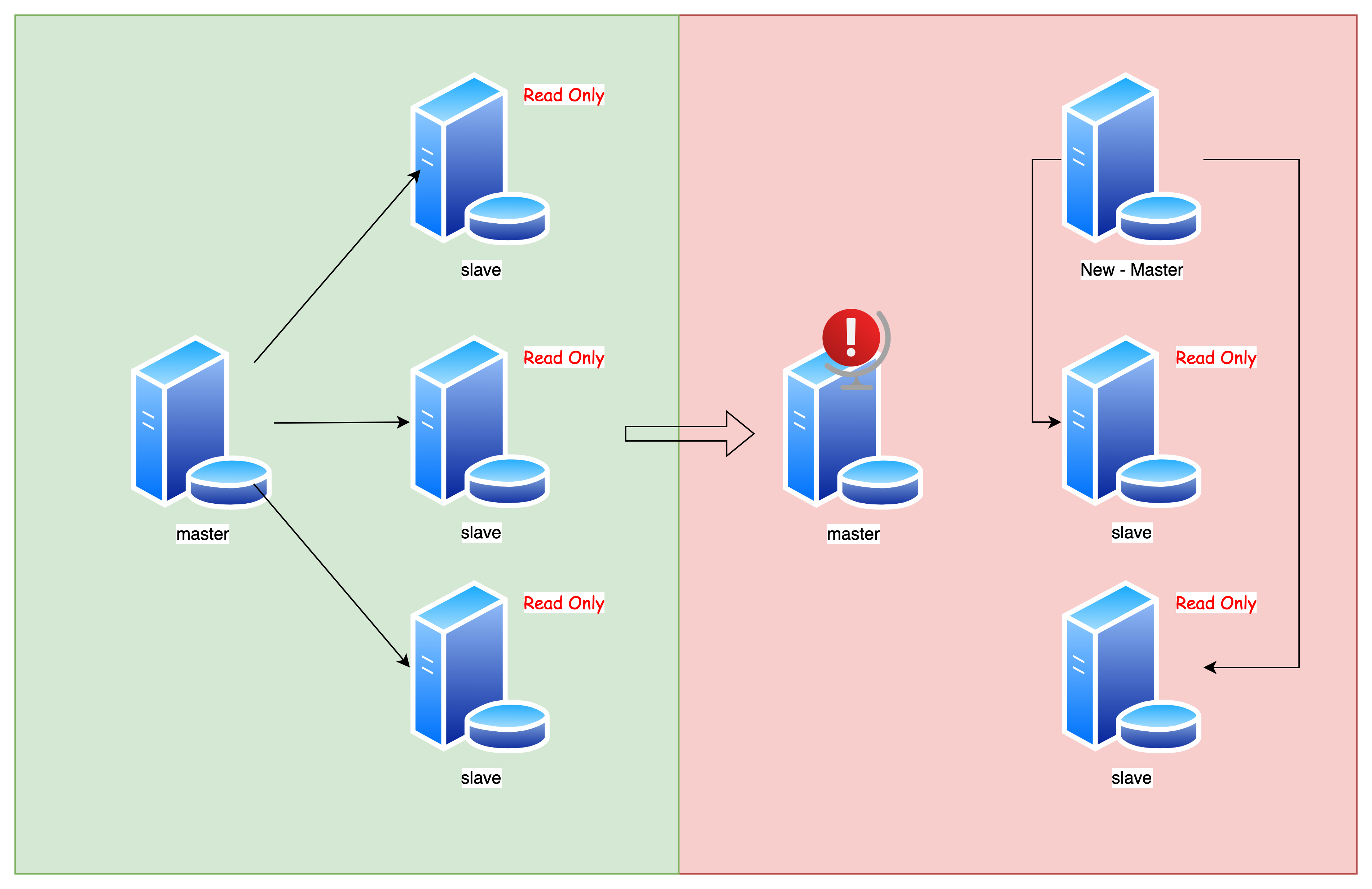
但问题是:其它从节点应该怎么去同步新的主节点的数据呢?
难点:从库去同步新的主库的数据,不是全量同步,而是增量同步,如何寻找这个同步的「起始点」?
基于位点的主从切换
CHANGE MASTER TO
MASTER_HOST=$host_name
MASTER_PORT=$port
MASTER_USER=$user_name
MASTER_PASSWORD=$password
MASTER_LOG_FILE=$master_log_name -- 指定主库同步的文件
MASTER_LOG_POS=$master_log_pos -- 指定同步的位置
问题就是如何确定同步的起始位置
使用这种方法,只能获取一个 大概的 的位点:
- 等待新的主库将 relay log 同步完成
- 获取新的主库的 file(show mater status)
- 取原主库的故障时刻 T
- 使用 mysqlbinlog 解析新主库 file 在 T 时刻的位点
mysqlbinlog File --stop-datetime=T --start-datetime=T
基于 GTID 的主从切换
上面的方式太麻烦了,还容易出错
MySQL 5.6 引入了 全局事务 ID(GTID),是一个事务的唯一标识
在 GTID 模式下,从库获取新的主库的位点这件事情就在 MySQL 内部做好了:
CHANGE MASTER TO
MASTER_HOST=$host_name
MASTER_PORT=$port
MASTER_USER=$user_name
MASTER_PASSWORD=$password
master_auto_position=1 -- 指定使用 GTID 确定位点
想要更深入的了解 GTID 的实现,可以看看这篇文章:27 | 主库出问题了,从库怎么办?
读写分离
什么是读写分离
读写分离,指的是将 DB 的读写操作分配到不同的节点执行,例如:主库只进行写操作,从库只进行读操作
采用读写分离,可以提高整个 DB 集群的读能力
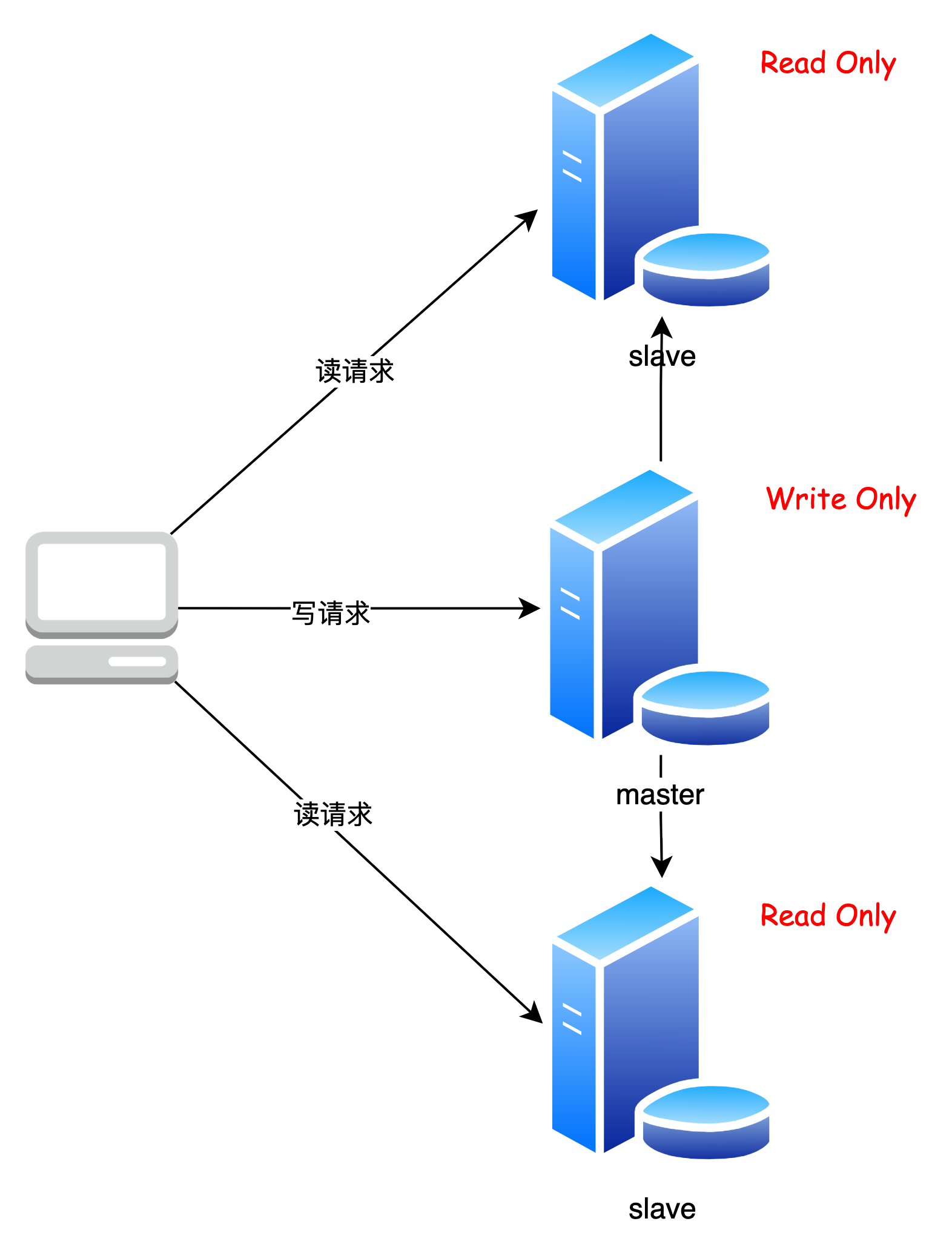
读写分离如何实现
在 MySQL 集群搭建完毕以后,应用层一般有两种方式实现读写分离:
- 应用层代码手动实现
- 基于 Proxy(代理层)实现
应用层代码手动实现
应用程序主动做负载均衡,这种模式下一般会把数据库的连接信息放在客户端的连接层。也就是说,由客户端来选择后端数据库进行查询。
这种方式的性能较好,缺点就是需要对已有代码进行修改
基于 Proxy(代理层)实现
这个方式就是在 Client 到 Server 之间引入一个代理,自动分发客户端的请求:
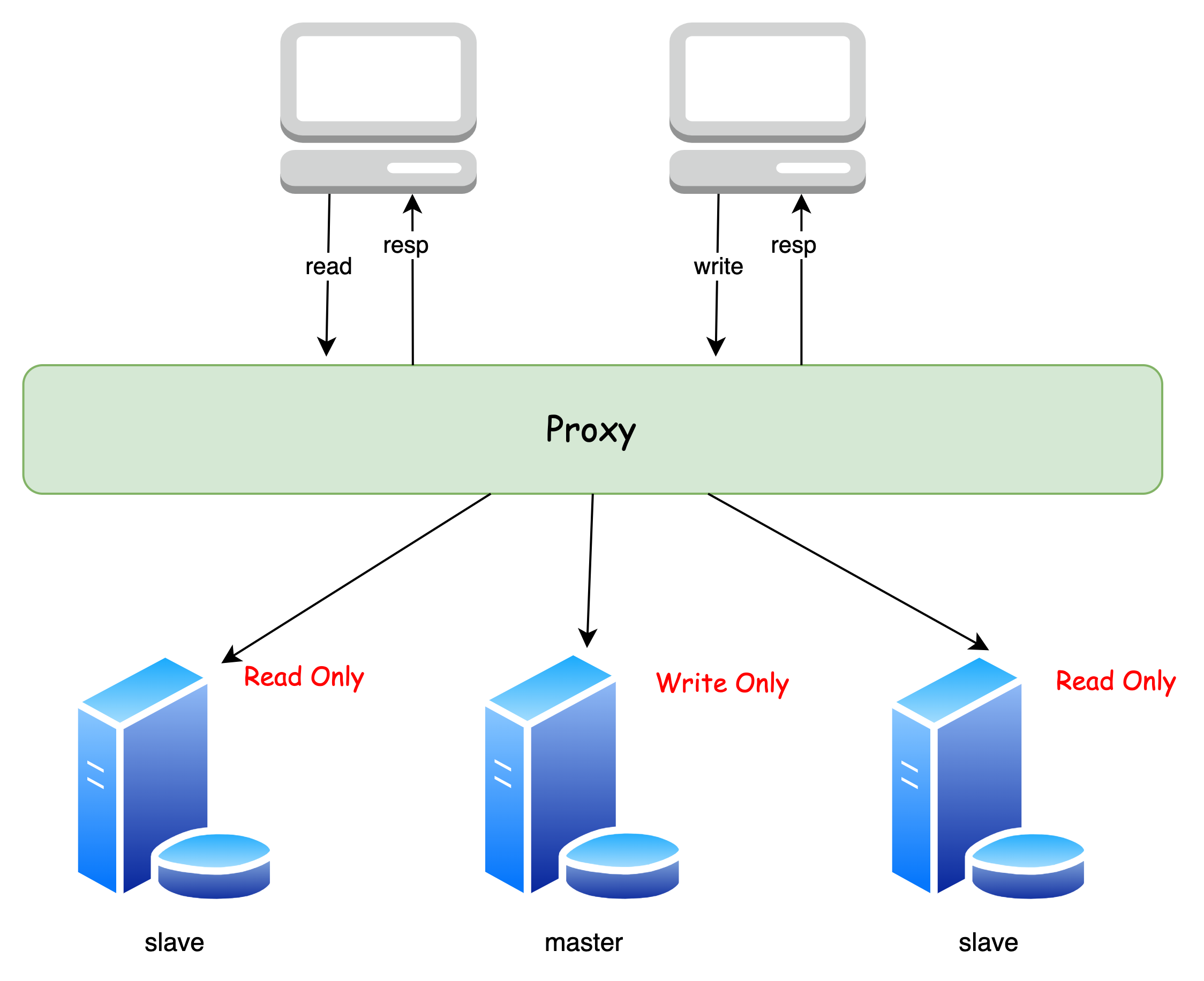
Proxy 会负责请求的分发与负载均衡
这种方式的优点就是不用修改已有代码,但是有一定的性能损耗
问题
引入读写分离,虽然可以提高读写性能,但会带来 数据不一致 的问题:
前面提到主从复制是需要时间的,当一个业务修改了表中的某一个数据,同步到其它从库需要时间
如果刚刚修改完数据,就去从库访问的话,就有可能访问到过期数据
如何解决?
强制走主库
一些对数据一致性要求很高的业务(如金融),可以采取这种方式,保证绝对的数据一致性
这种方式比较简单,缺点就是:如果很多业务都有很高实时性要求,都走主库,会 对主库造成很大压力
Sleep
既然同步需要时间,那我们可以「sleep」一下,等它同步完了再去访问不就好了吗
例如,一个用户发布了一个商品,前端可以基于本地已有信息进行展示,就好像获取到了最新的数据一样
用户待会刷新页面,其实已经过了一段时间,也就达到了 sleep 的目的,只要等待时间内同步完成,访问的就是最新的数据
这种方式适用于对数据实时性要求低的业务,就算访问到过期数据也影响不大
缺点就是:我们无法保证在规定时间内主从同步完毕,还是 有访问到过期数据的可能性
判断主从无延迟方案
这种方式比较折中
- 在访问数据之前,判断主从是否同步完毕:
- 如果同步完毕,那么走从库,获取的是最新数据
- 如果没有,可以等待一段时间,重复第一个步骤
- 如果等待时间 超过一定阈值,那么根据实际需求,看看是走主库,获取最新数据;或者走从库,获取过期数据
这种方式看起来比较灵活,可以根据实际需求选择走主库还是走从库
如何判断主从是否同步完毕?
- 可以使用
show slave status查看 SBM,如果为 0,说明 可能 同步完毕。但这个方式判断不太精确- 可以对比位点确保主备无延迟
- 可以对比 GTID 集合确保主备无延迟
分库分表
什么是分库
分库,指的是将一个数据库的数据分散到不同的数据库上,以减轻单个 DB 的压力
分库有两种方式:
- 垂直分库
- 水平分库
垂直分库指的是:按照业务,将一个库的多个表分到不同的库上,不同业务使用不同的数据库
例如,一个数据库内有:User 表、Post 表、Comment 表,如果要垂直分库,就可以将这三张表分到不同的库中
水平分库指的是:同一个表,按照一定「分片规则」,分配到不同的库中
例如,一张 Comment 表,做水平切分,id 为 1 ~ 10000 的存在第一个 DB,id 为 10001 ~ 20000 的存在第二个 DB
什么是分表
分表,指的是将一张表的数据拆分成多张表,提高单表查询效率
分表也是两种方式:
- 垂直分表
- 水平分表
垂直分表指的是:将一张表按照不同的字段,拆分成多张表
例如 User 表有 name、sex、addr、phone、email 字段,可以将 User 表拆成 user_base(id, name, sex) 和 user_extra(id, addr, phone, email)
水平分表指的是:按照一定的「分片规则」,将一张表的若干行数据拆分成到不同的表,解决单表数据太多导致检索能力下降问题
例如,对于 User 表,id 为 1 ~ 10000 的存在表 user_0,id 为 10001 ~ 20000 的存在表 user_2
水平分表只能解决单表数据量太大的问题,为了提高整体的效率,一般与水平分库结合使用
什么时候需要分库分表
- 单表数据量太大,检索能力下降
- 数据库存放的数据太多,备份时间很长
- 并发请求高,一个 DB 扛不住
常见分片算法
哈希分片
根据指定 key(比如 id) 的哈希值,算出这个数据在哪个库(表)中
哈希分片算法比较适合 随机 查询的场景,并能 一定程度避免单个库上的热点问题,不适合范围查询
范围分片
按照指定范围区间来分配数据,例如,将 id 为 1 ~ 10000 的存在第一个 DB,id 为 10001 ~ 20000 的存在第二个 DB
范围分片算法比较适合 范围 查询的场景,但有可能 存在 单个库上的 热点问题
分库分表带来的问题
引入分库分表,除了性能的提升,还会带来一定麻烦:
- 无法使用 join 操作
- 事务问题:如果单个事务涉及到不同的 DB,就涉及到 分布式事务 了
- ID:分库分表以后,数据存在不同的 DB,那么自增 ID 就无法满足需求了(可能重复),需要引入分布式 ID
- 聚合查询:对于 order by、group by 变得很复杂
- 维护成本:分库分表会带来额外的维护成本
无法使用 join 操作其实也不能算缺点
很多大厂的资深 DBA 都是建议尽量不要使用 join 操作,效率不太理想
虽然不能用 join,但是可以在业务层做数据的组装,也能达到类似效果
分库分表后,数据如何迁移
第一种方案就是 停机迁移
在低峰期,可以挂一个公告,表示需要停机维护,然后做数据迁移即可
第二种方案是 双写,适用于无法停机,只能在线迁移的情况
- 老库的增删改操作,新库也要同步进行(双写),如果新库没有这个数据,需要先插入
- 双写在新库只会写入新的数据,旧数据需要新库在后台同步
- 持续上面的操作,直到数据迁移完毕
双写方案比较麻烦,很可能出问题
无论哪种方案,都要使用到 binlog