什么是 Buffer Pool
如果每次增删查改都要直接操作磁盘,会严重拖慢性能
因此 InnoDB 引入了 Buffer Pool,用于提高 DB 的读写性能
有了 Buffer Pool 以后:
- 读取数据,可以看看要读取的数据页有没有在 buffer pool,如果在,直接读取就行,不用访问磁盘
- 写入数据,可以看看要写入的数据页有没有在 buffer pool,如果在,直接写入就行,并标记为「脏页」,不用访问磁盘
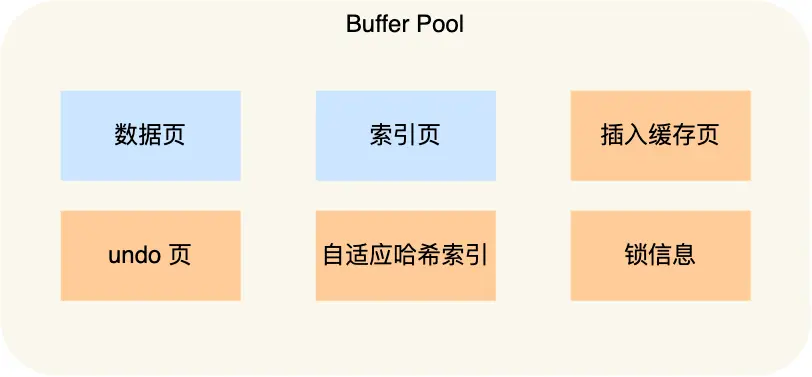
Buffer Pool 缓存什么
Buffer Pool 主要缓存以下内容:
- 数据页
- 索引页
- undo 页
- 插入缓存页
- 自适应哈希索引
- 锁信息
如何管理 Buffer Pool
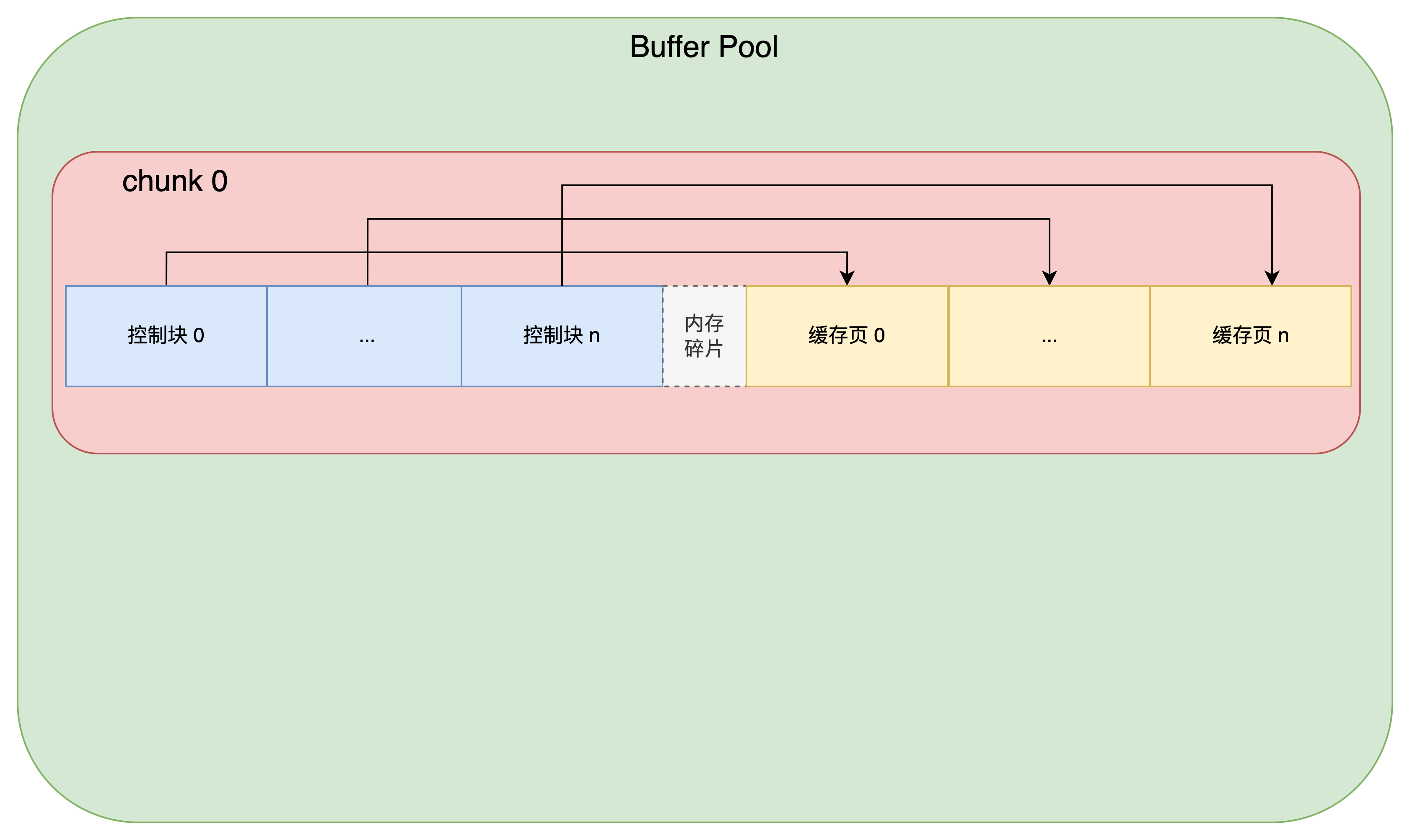
为了管理众多的页面,Buffer Pool 为每一个缓存页都创建了一个 控制块
控制块记录了一些元数据:
- 数据页信息:包括:表空间 id、页码、指向数据页的指针
- 脏标记:记录了该页是否修改过
- …
分配给 Buffer Pool 的内存空间通常是 连续 的,且控制块在 Buffer Pool 的最前面:
Free 链表
起初,分配给 Buffer Pool 的内存很多都是没有使用的,也就是说,存在很多 空闲页
这也是为什么刚开始启动 MySQL 时,虚拟内存占用相对较高,但物理内存占用相对较低的原因
如果想要缓存数据到 Buffer Pool,肯定要选择一个空闲的缓存页来存放
我们不可能遍历每一块缓存页来判断是否空闲,效率太低了
InnoDB 使用 Free 链表来管理空闲页(free page)
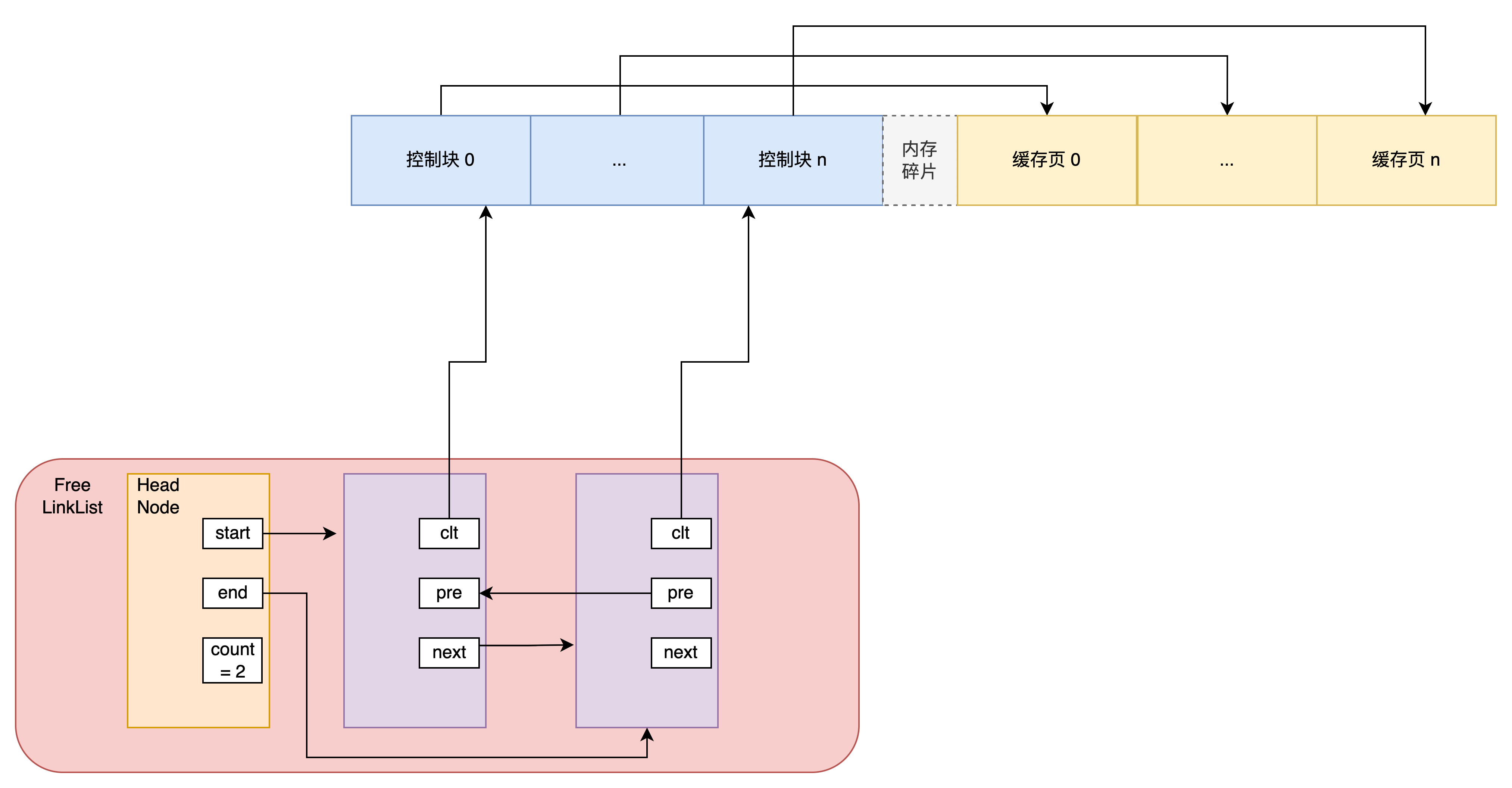
Free 链表记录了空闲页对应控制块的指针,这样,需要分配缓存页时,就可以遍历 Free 链表来获取可以分配的空闲页
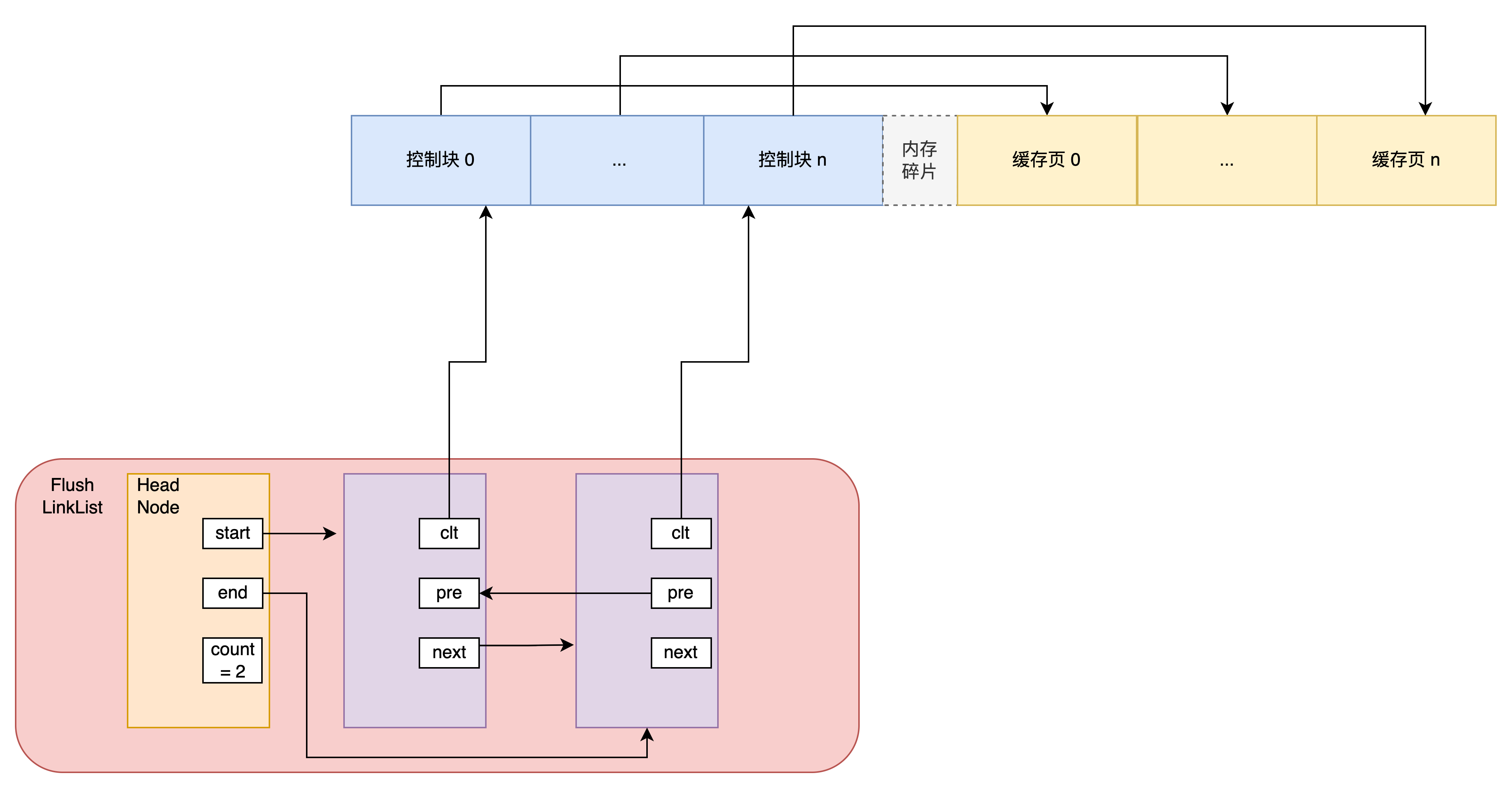
Flush 链表
Buffer Pool 中的「脏页」是需要在「合适的时候」刷到磁盘的
与空闲页的管理一样,也有一个 Flush 链表来管理等待刷到磁盘的脏页:
LRU 链表
缓存肯定不能一直存放在内存中:如果有源源不断的数据被缓存,那么 Buffer Pool 的空闲页肯定会被用完
因此,需要考虑在空闲页用完之前,淘汰一些使用频率较低的缓存数据
可以想到使用 LRU 算法来实现内存淘汰:
基本 LRU 算法的思想:
- 使用一个链表管理所有正在使用的缓存页
- 当一个新的页面被缓存,将其插入到链表 头部
- 若要淘汰缓存页,优先淘汰链表尾部的
预读失效
MySQL 有一种 预读机制:基于 局部性原理,当前访问的页面的接下来几个页面很有可能也会被访问
于是,在从磁盘读取数据时,除了读取目标页以外,可以 预读 接下来的若干页到 Buffer Pool 中
这看起来很美好,但是考虑一个场景:预读进来的页一直没有被使用
这种场景除了 浪费缓存空间 以外,还会 存在热点数据被淘汰 的可能:
如果使用传统的 LRU 算法,就会把预读页放到 LRU 链表头部,而当 Buffer Pool 空间不够的时候,还需要把末尾的页淘汰掉。
如果这些预读页如果一直不会被访问到,就会出现一个很奇怪的问题,不会被访问的预读页 却占用了 LRU 链表 前排 的位置,而末尾 淘汰的页,可能是 频繁访问 的页,这样就大大 降低了缓存命中率。
为了避免这种情况,InnoDB 将 LRU 链表分为两个部分:
- young
- old
old 区域占整个 LRU 链表长度的比例可以通过 innodb_old_blocks_pct 参数来设置,默认是 37,代表整个 LRU 链表中 young 区域与 old 区域比例是 63:37。
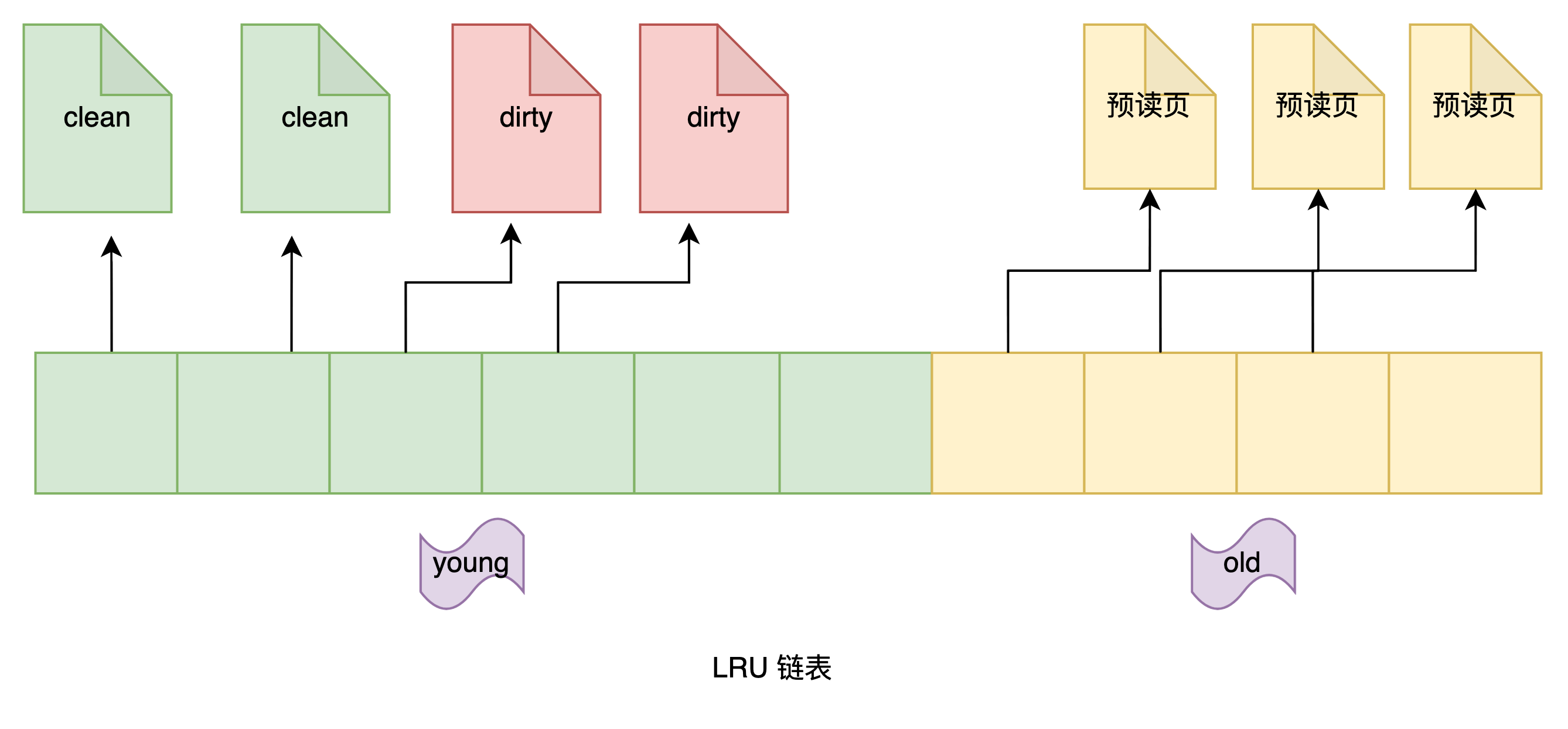
分区后,目标页还是放在 young 的头部,而 预读页放在 old 头部
当预读页被 第一次 访问时,就加入到 young 的头部
在淘汰数据时,先淘汰的肯定是 old 区域的,只有 old 部分都淘汰完了才会淘汰 young 部分的,这样就避免了热点数据被淘汰的风险
缓存污染
当一个 SQL 语句 扫描了大量数据,在 Buffer Pool 的空间比较有限的情况下,可能会 把热点数据替换掉,大大降低缓存命中率,产生大量磁盘 IO,这就是缓存污染问题
为什么会这样?
如果采用上面的 young-old 分区策略,当一个 SQL 语句 扫描了大量数据:
- 扫描第一页,预读接下来 2、3、4… 页
- 扫描第二页,由于第二页已经在 old 区,提升 到 young 区,预读接下来 5、6、7 …页
- 扫描第三页,由于第三页已经在 old 区,提升 到 young 区,预读接下来 8、9、10 …页
可以发现,在这种情景,预读页也跑到了 young 区,可能导致热点数据被挤到 old 区,甚至淘汰
而这种全表扫描的 SQL,缓存页往往就访问那么一两次,为了这么一个 SQL 淘汰热点数据太不划算了
究其原因,还是预读页提升门槛太低,仅仅读一次就可以提升到 young 区
InnoDB 为了提高预读页进入 young 区的门槛,是这样做的:进入到 young 区域条件增加了一个停留在 old 区域的时间判断
- 第一次访问,仍然在 old 区域,不提升 到 young 区
- 第二次访问,如果与第一次访问的时间间隔 低于某个阈值,也不提升到 young 区
全表扫描时,预读页「前后访问时间间隔」通常很短,使用这种策略,就可以避免「缓存污染」问题
这个阈值可以通过 innodb_old_blocks_time 来修改,默认为 1000ms
详细说说「淘汰」这一过程
在淘汰页面时,需要判断这个页是干净页还是脏页:
- 如果是 clean page:直接淘汰即可,无需任何其它处理
- 如果是 dirty page:需要 回写磁盘 再淘汰
如果按照上面的逻辑,在 LRU 淘汰脏页需要涉及磁盘 IO
为了尽可能少的涉及磁盘 IO,InnoDB 会优先选择淘汰干净页,迫不得已才会淘汰脏页
最后再来理一下 LRU 的过程:
- Free 链表为空,说明没有空闲页,于是来 LRU 链表
- 第一次扫描:从尾部扫描 LRU 链表,如果该页面为 clean,淘汰,将其加到 Free 链表
- 如果第一次扫描后,剩余的空闲页还不够(第一次只扫描 100 个页),执行第二次扫描:深度扫描 LRU 链表,单页刷新(目的是尽可能快的获取足够的空闲页),淘汰,将其加到 Free 链表
可以看出:空白页的数目与脏页数目是影响 LRU 性能的关键因素
脏页什么时候回写磁盘
从 LRU 淘汰机制可以看出:在空白页紧张的情况下,如果脏页之前没有及时回写,会影响 LRU 的性能
那么脏页回写磁盘的时机是什么呢?
- redo log 满了:如果 redo log 满了(write pos 追上了 checkpoint),那么 MySQL 会停下来,执行脏页回收
- LRU 淘汰过程:如果淘汰掉所有的 clean page 还不够,那么就要触发脏页回写了
- MySQL 认为当前空闲:如果 MySQL 认为当前比较空闲,也会将触发脏页回写
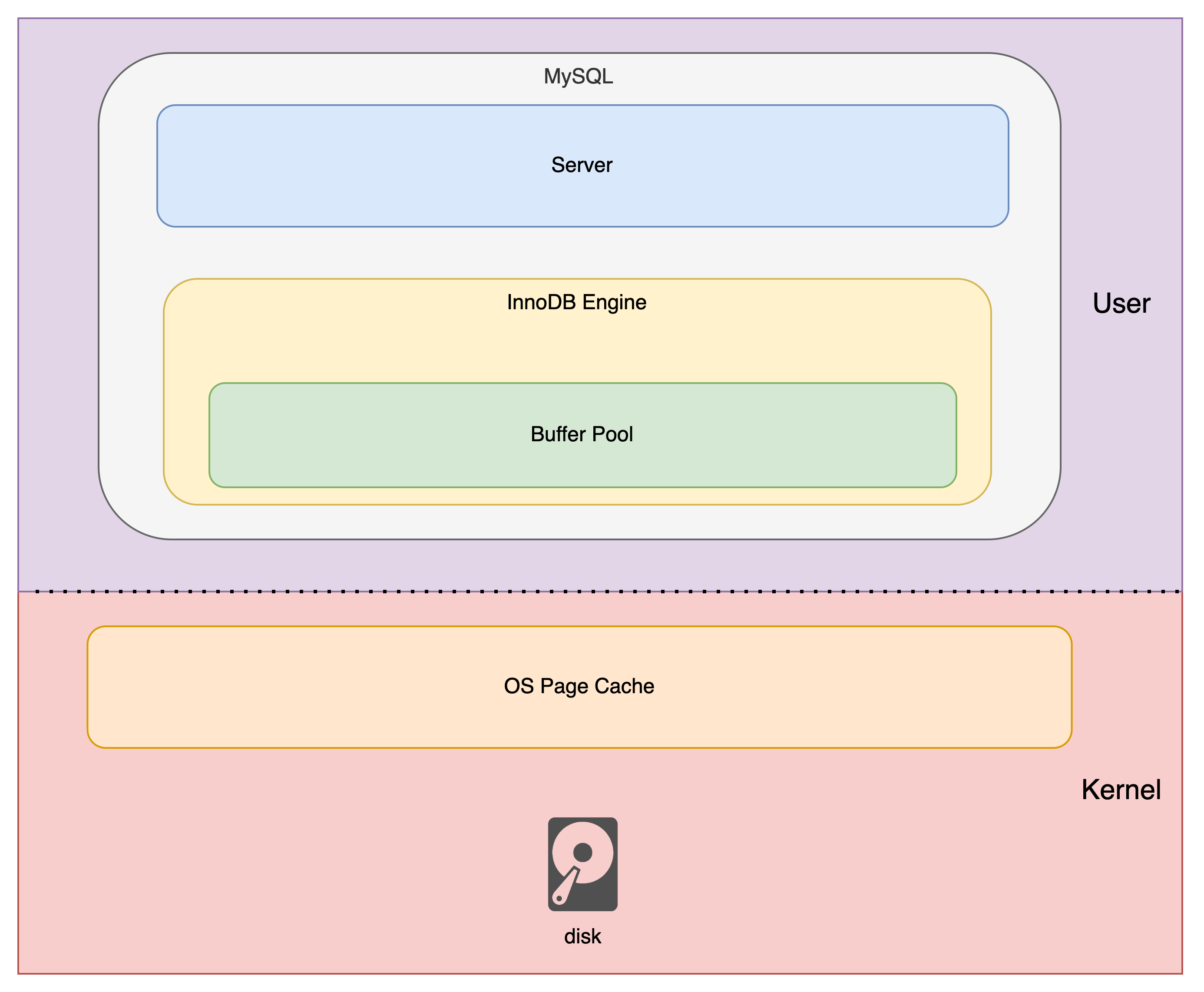
- MySQL 退出时:正常关闭 MySQL,肯定需要将脏页回写到磁盘,保证持久性(Buffer Pool 是处于用户空间的)
如果偶尔发现一些慢 SQL,可能就是因为脏页回写导致的「抖动」,此时可以调整 Buffer Pool 和 redo log 的大小
补充:
淘汰的是脏页,则此时脏页所对应的 redo log 的位置是随机的,当有多个不同的脏页需要刷,则对应的 redo log 可能在不同的位置,这样就需要把 redo log 的多个不同位置刷掉,这样对于 redo log 的处理不是就会很麻烦吗?(合并间隙,移动位置?) 另外,redo log 的优势在于将磁盘随机写转换成了顺序写,如果需要将 redo log 的不同部分刷掉(刷脏页),不是就在 redo log 里随机读写了么?
其实淘汰的时候,刷脏页过程不用动 redo log 文件的。
这个有个额外的保证,是 redo log 在「重放」的时候,如果一个数据页已经是刷过的,会识别出来并跳过。
Buffer Pool 的并发性能
问题来了,在实际开发中,肯定有多个线程会并发访问同一个 Buffer Pool,那怎么保证多个线程之间的同步呢?
InnoDB 的实现很简单:给 Buffer Pool 实例加一个锁,线程要想访问 Buffer Pool,必须持有锁
可以认为:对单个 Buffer Pool 的访问是 串行 的
串行的效率不会低吗?
并不会,Buffer Pool 的操作几乎是纯内存操作,IO 是很快的,这点就像 Redis 一样,核心处理部分采用单线程,效率也很高
当然,实际开发中,如果内存充足,可以配置 多个 Buffer Pool 实例,提高并发性能
每个 Buffer Pool 缓存的数据是一样的吗?
不是,如果缓存一样的数据,虽然提高了并发性能,但是内存利用率不高
每个 Buffer Pool 缓存的数据是不一致的:
- 在缓存一个 page 的时候:使用 hash function 计算该页应该缓存到哪个 Buffer Pool
- 在读取一个 page 的时候:使用 hash function 计算该页在哪个 Buffer Pool
基于 Buffer Pool 的数据页访问过程
使用 hash function 可以确定一个 page 在哪个 Buffer Pool,但是如何快速确定这个 page 的存储地址呢?
InnoDB 为每个 Buffer Pool 实例分配了一个 hash table,以 表空间号+页号 为 key,存储地址 为 value
确定了 Buffer Pool 以后,就可以根据 hash table 获取 key 对应的 控制块的存储地址
拿到控制块的存储地址,就可以得到这个 page 的地址了
如果 cache miss,就要从磁盘读取这一页的数据到 Buffer Pool:
- 看看有没有足够空白页,如果有,分配即可,如果没有:
- 基于 LRU 淘汰机制 ,淘汰掉不常使用的页面,腾出空白页
Buffer Pool 预热
关闭 MySQL 服务时,有时需要等待较长时间才能关闭,这是为啥?
除了上文提到的 MySQL 会在退出时,将 Buffer Pool 的脏页刷盘以外,还有没有其它因素?
有的
在刚启动 MySQL 时,Buffer Pool 为空,执行 SQL 时,由于目标页没有在 Buffer Pool,于是需要 从磁盘读取目标页 到 Buffer Pool
Buffer Pool 的数据从无到业务热点数据的这个过程称为 Buffer Pool 预热
如果 Buffer Pool 比较大,并且业务热点数据也比较多,那么预热的过程可能很长,这也是 MySQL 刚启动时,性能没那么好的原因
为了缩短预热时间,MySQL 会在 关闭 Server 时,将 Buffer Pool 的数据保存到磁盘,这样再次启动时,就可以根据这些数据加速预热过程了
可以通过配置 innodb_buffer_pool_dump_at_shutdown 和 innodb_buffer_pool_load_at_startup 来控制这个行为
默认情况下,这两个选项都是开启的
调整 Buffer Pool 大小
如果在运行过程中,想要将 Buffer Pool 的空间调大一点,怎么做?
比如一开始 Buffer Pool 的空间为 2G,要调整成 4G,是不是需要先分配一块 4G 大小的内存空间,然后将旧数据迁移过去?
InnoDB 的实现并不是这样的,效率太低了
为了动态扩展 Buffer Pool 的大小,InnoDB 引入了 chunk 的概念:
一个 Buffer Pool 中可以有多个 chunk,每个 chunk 有自己的控制块和缓存页
多个 chunk 共享 Free 链表、Flush 链表、LRU 链表
如果需要动态扩容,只需要申请新的 chunk 就行了,默认情况下,每个 chunk 的大小为 128M(可以修改 innodb_buffer_pool_chunk_size 来调整)
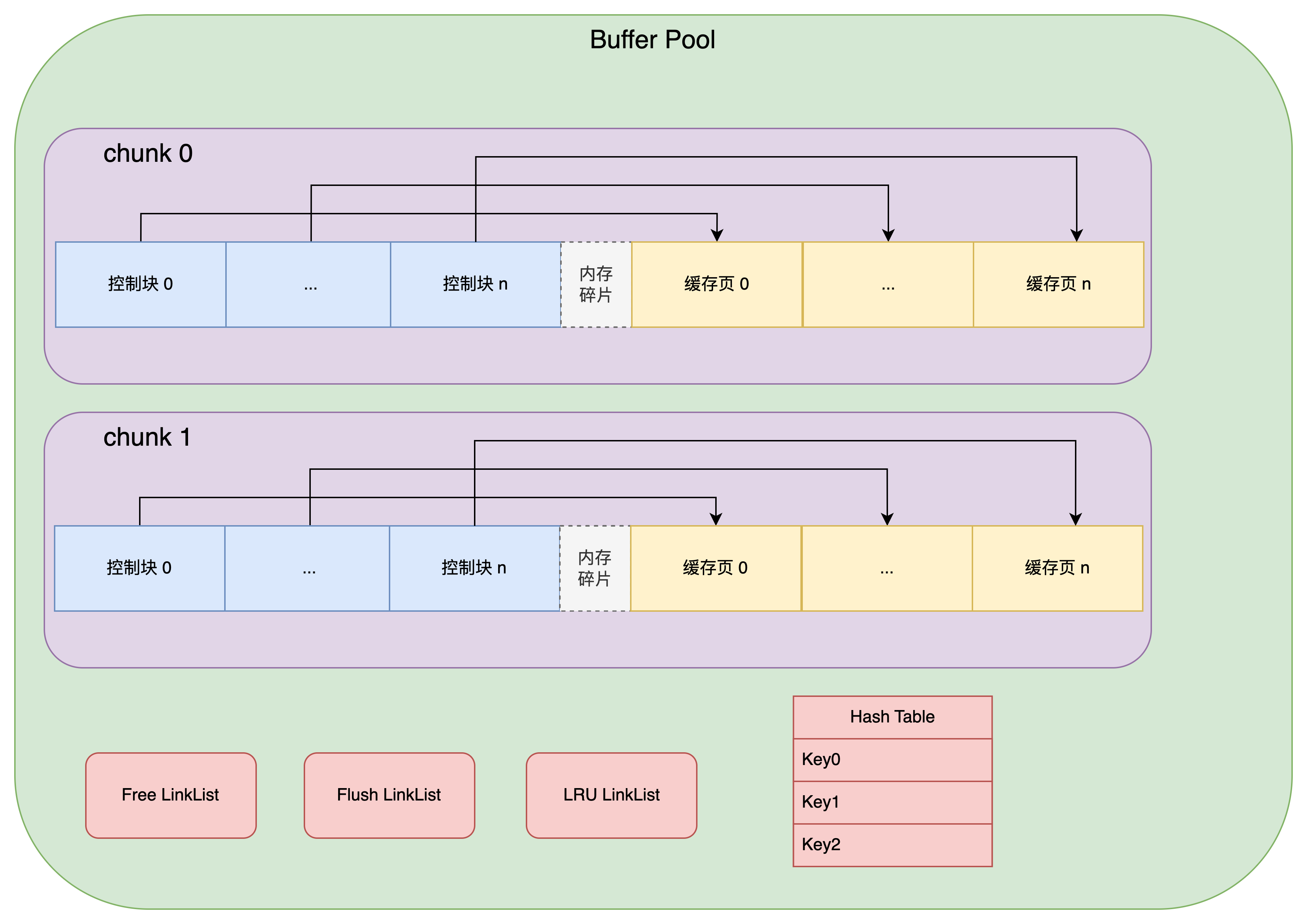
InnoDB Buffer Pool 架构图
最后给出一张 InnoDB Buffer Pool 的架构图(如有错误还请指出):