如何理解 TCP 面向字节流?
由于 TCP 的滑动窗口机制(发送窗口会动态变化),在发送数据时,原数据可能发生分片
举个例子:原数据为一个字符串 “114514”
经过分片后,接收方可能收到多个 TCP 报文,假设为:
- “11”
- “4”
- “514”
内核在收到这些数据后,会将数据载荷部分扔到接收缓冲区,等待应用程序调用 read 取走数据
由于分片机制,我们 不能认为一个 TCP 报文对应一个原始的用户数据,因此,我们说 TCP 是面向字节流的
相反,对于 UDP 协议而言,在传输层不存在分片机制,即使在 IP 层分片,接收方也会将分片后的数据重组为原数据,因此,我们说 UDP 是面向报文的
如何解决粘包问题?
例如,发送方发送了两条数据:
- “114514”
- “niuma”
如果使用 TCP 协议,并且发送窗口比较大,TCP 为了提高效率,会将这两条数据合并发送,接收方收到的数据就是 “114514niuma” 了
问题是,接收方并不知道这个数据,实际上是两条,这就是所谓的粘包问题
如何解决?
- 固定长度消息:双方约定每条消息的长度(不灵活,一般不用)
- 添加分隔符(如 HTTP 协议的 \n)
- 自定义消息格式:可以定义一个消息体,包含数据的字节数信息:
struct { u_int32_t message_length; char message_data[]; } msg;
为什么 TCP 每次的初始 Seq 都要不一样?
主要原因是:避免历史报文被现有连接错误接收
这个问题主要是针对同一个四元组连接
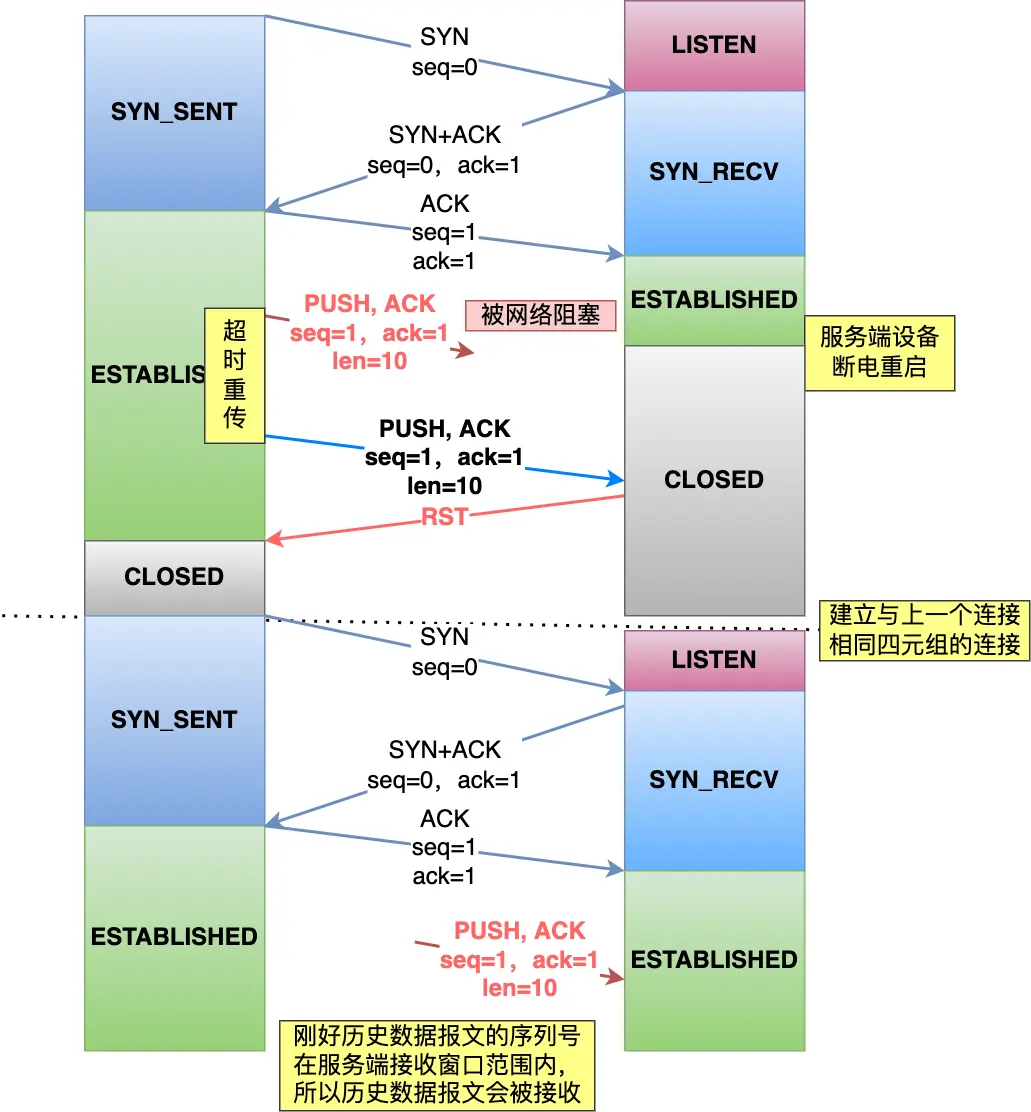
如果每次初始的 Seq 都不一样,就可以 很大程度 避免这个问题
注意:并不是绝对避免,因为 Seq 存在「回环」问题
在 TCP 建立连接的时候,客户端和服务端都会各自生成一个初始序列号,它是基于时钟生成的一个随机数,来保证每个连接都拥有不同的初始序列号。初始化序列号可被视为一个 32 位的计数器,该计数器的数值每 4 微秒加 1,循环一次需要 4.55 小时。
如果 Seq 循环了一次,那还是有可能发生这个问题的:
- TCP 连接建立的时间很长,回环
- 带宽大,每次发送的数据包很大,序列号用完了,回环
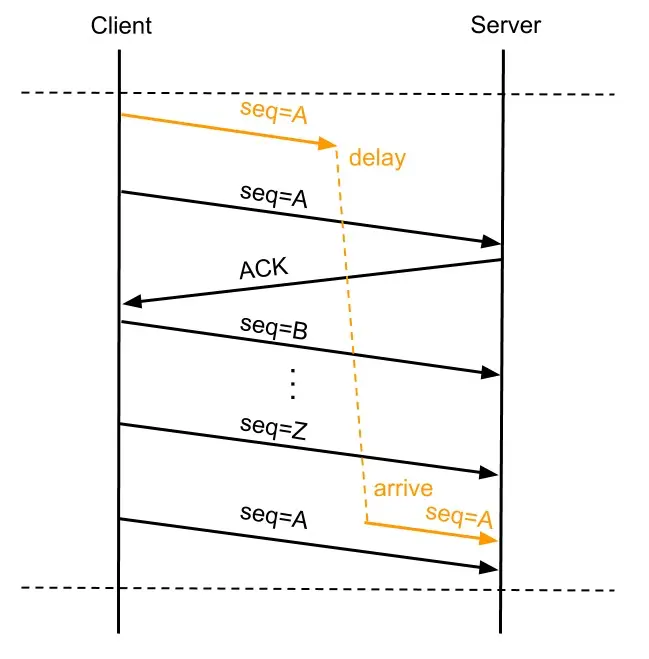
为了解决这个问题,TCP 又引入了 时间戳(32 位) 的概念,以及 PAWS 算法
PAWS 算法会在收到一个数据包时,将数据包内的时间戳(A)与上一个包的时间戳(B)做比较,如果:
- A > B:有效,接收
- A <= B:过期,丢弃
因此,初始 Seq 随机 + 时间戳 可以有效避免历史报文的错误接收问题
SYN 报文什么时候可能会被丢弃?
tcp_tw_recycle
启用 tcp_tw_recycle,就会快速回收处于 TIME_WAIT 状态的连接
但如果开启了 tcp_tw_recycle + 时间戳机制,就会启用 pre-host 的 PAWS,这个与之前的 PAWS 不同,它是对「对端 IP」做 PAWS 检查,而不是「对端 IP + Port」
假设客户端的网络使用了 NAT,就会产生麻烦,这里假设客户端 A、B 处于同一个 NAT 下:
- B(11.45.1.4:1146) 先与 Server 建立连接
- A(11.45.1.4:1145) 后与 Server 建立连接,但 SYN 报文比 B 先到达,Server 保存 A SYN 报文的时间戳
- 此时,B 的 SYN 报文到达,但 B 的时间戳比 A 小(因为先建立连接),由于启用了 NAT(A、B IP 是一样的),并且 Server 启用 pre-host 的 PAWS(只检查对端 IP),就会认为 B 的 SYN 报文是过期报文,丢弃
可见,tcp_tw_recycle 在 NAT 下是不安全的,存在潜在的错误丢弃 SYN 报文的可能性
并且,当今网络多层 NAT 的使用非常普遍
因此,4.12 版本之后的 Linux,取消了 tcp_tw_recycle
半连接队列溢出
在不开启 syn_cookies 的情况下,如果半连接队列满了,也会丢弃 SYN 报文
全连接队列溢出
如果全连接队列溢出,会丢弃新的连接请求
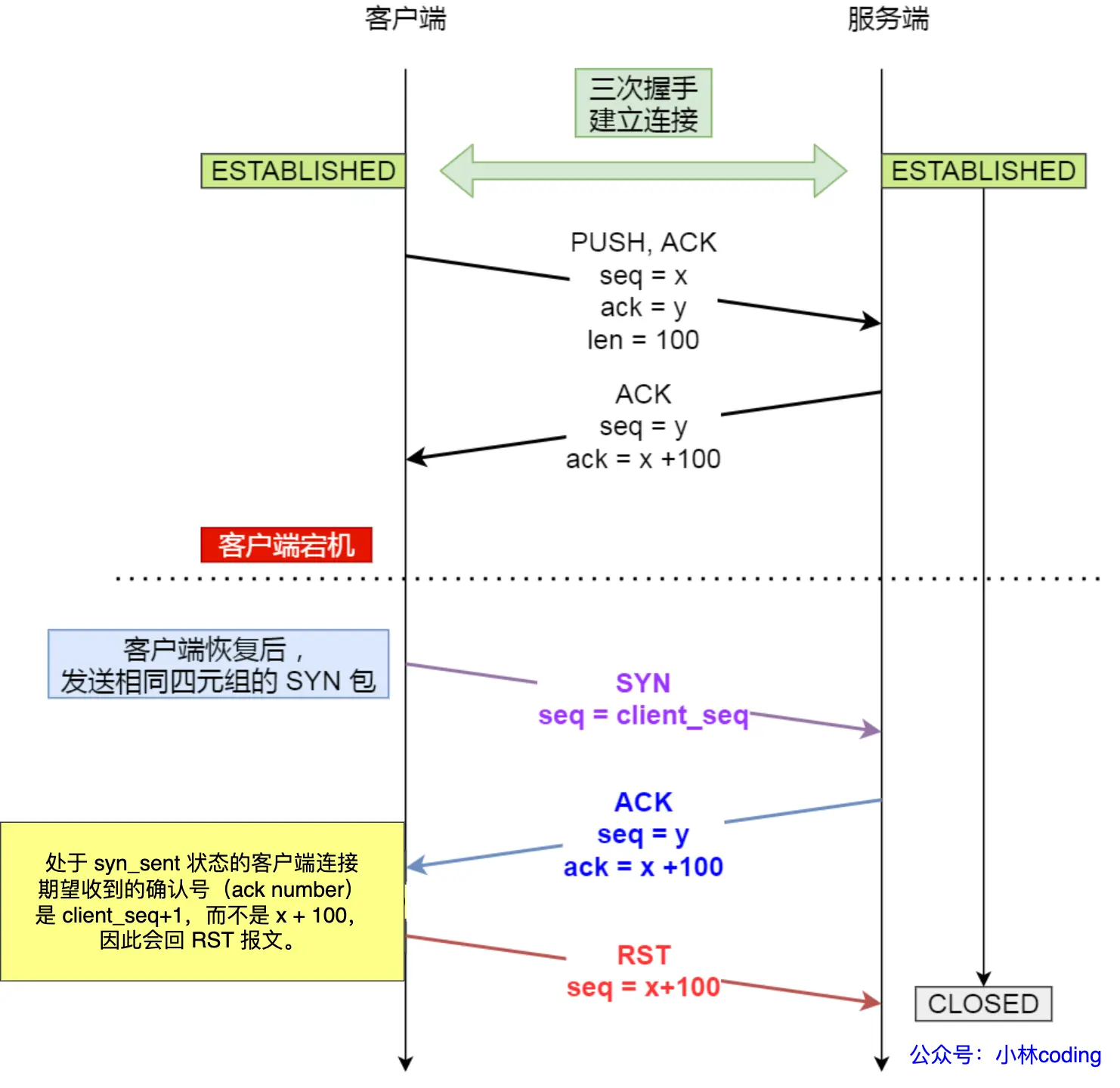
已建立连接的 TCP,收到 SYN 报文会发生什么?
这个要分两种情况,客户端发送 SYN 报文的端口号与之前是否一致:
如果不一致
Server 会认为这是一个新的连接请求,当然会回复 SYN + ACK 给对方
如果一致
说明客户端可能宕机,重启后再次用相同的 port 与 Server 建立连接
由于初识 Seq 为随机值,基本上不可能与服务端的 last ack 的值相等
当服务器返回 ack 后(这个 ack 对应的值基本上不可能等于 clnt_seq + 1),由于 ack 的 seq 不合法,client 会发生 RST 报文,终止 TCP 连接
如何关闭一个 TCP 连接?
- 直接关闭进程:内核会自动关闭进程存在的 TCP 连接
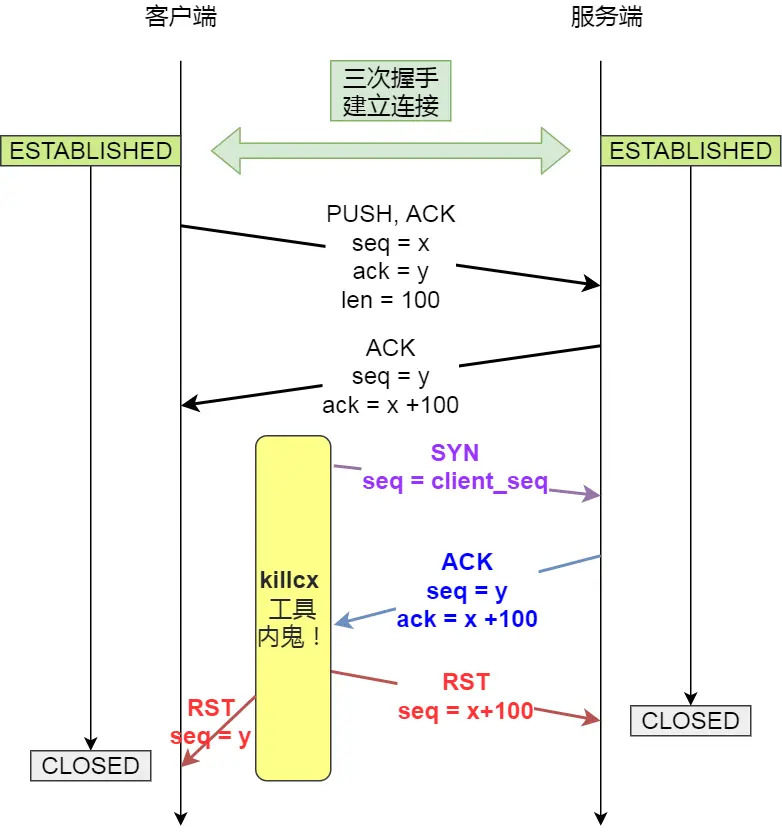
- killcx
- tcpkill
killcx 与 tcpkill 的原理都是基于伪造 RST 报文实现的,只不过获取伪造 RST 报文 seq 的方式不同
注意:如果 RST 报文的 seq 与预期不一致,会丢弃该报文
killcx
killcx 的原理是:根据提供的「源 IP + 源 Port」模拟一个 Client 向「目的 IP + 目的 Port」的 Server 发起一个 SYN 报文
当 Server 收到这个 SYN 报文,会返回 ACK 报文(包含了 seq 以及 ack 的值)
killcx 收到 seq 和 ack,可以反推:
- 原客户端的 seq(就是 server 返回的 ack)
- Server 的 seq(就是 server 返回的 seq)
于是,拿到这两个 seq,就可以分别向 Client、Server 发送伪造的 RST 报文,达到关闭 TCP 连接的效果
tcpkill
与 killcx 有点不同,tcpkill 获取伪造 RST 报文 seq 的方式是被动的,即监听对应的 TCP 连接
只有当待 kill 的 TCP 连接有数据包的发送,才能获取 seq
因此,tcpkill 只能关闭活跃的 TCP 连接
四次挥手中收到乱序的 FIN 报文怎么处理?
看下场景:
TCP 里面那个 shutdown 函数主动方调用只关闭写端情况下,假如服务端在二三次挥手之间发的数据,或者是四次挥手之前的数据包,因为网络阻塞导致第三次挥手的 FIN 包比数据包先到主动关闭方,那么主动关闭方收到 FIN 是否就会进入 timewait 状态?这时候那个延迟的数据包到了还能正常接收并处理么?
意思就是:在 FIN_WAIT_2 状态下,如果 FIN 报文比 data packet 先到达,是否还能正确处理 data packet?会不会丢数据?
答案是:不会
在 FIN_WAIT_2 状态下,收到一条消息,内核会做以下步骤:
- 检查当前消息的 seq 是否符合预期(也就是是否乱序)
- 如果符合预期,判断消息是否包含 FIN
- 如果包含 FIN:
- 发送 ack 给对方,并进入 TIME_WAIT
- 清空「乱序队列」
- 如果不包含 FIN:将消息写入 buffer,判断「乱序队列」中是否有「符合条件的消息」
- 如果有,判断是否包含 FIN
- 如果包含 FIN,发送 ack 给对方,并进入 TIME_WAIT
- 否则,一并写到 buffer
- 如果有,判断是否包含 FIN
- 如果包含 FIN:
- 否则,写到「乱序队列」
- 如果符合预期,判断消息是否包含 FIN
符合条件是指 seq 是否等于 lastSeq + lastLen
处于 TIME_WAIT 的连接,收到 SYN 报文怎么处理?
如果收到的是不同的 源 IP + Port 组,那么属于不同连接,直接建立即可,否则:
这个主要是判断 SYN 报文的「合法性」
- 如果 SYN 报文合法,复用连接,跳过 TIME_WAIT,进入 SYN_RECV
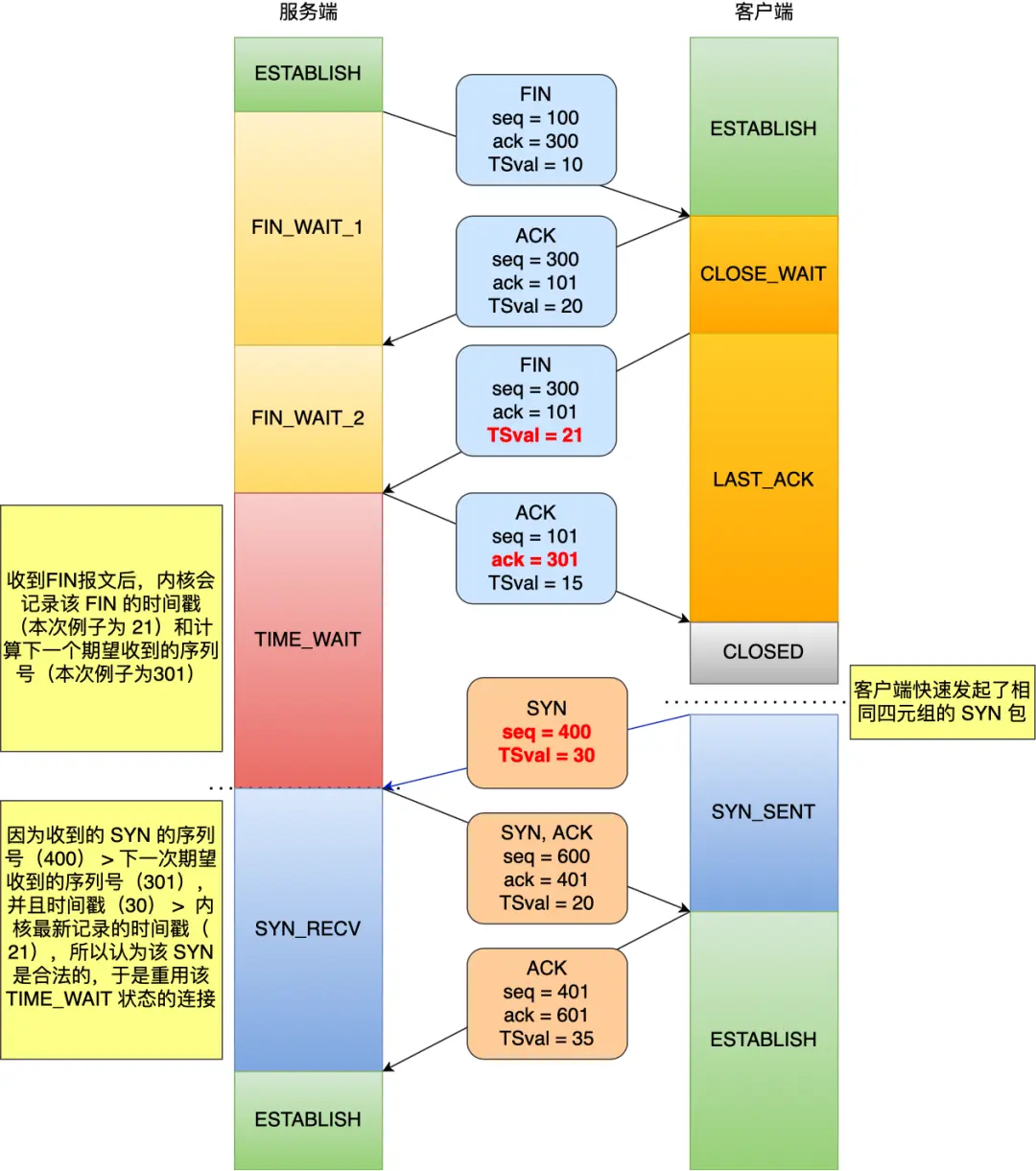
- 如果 SYN 报文不合法,发送 RST 报文给对方
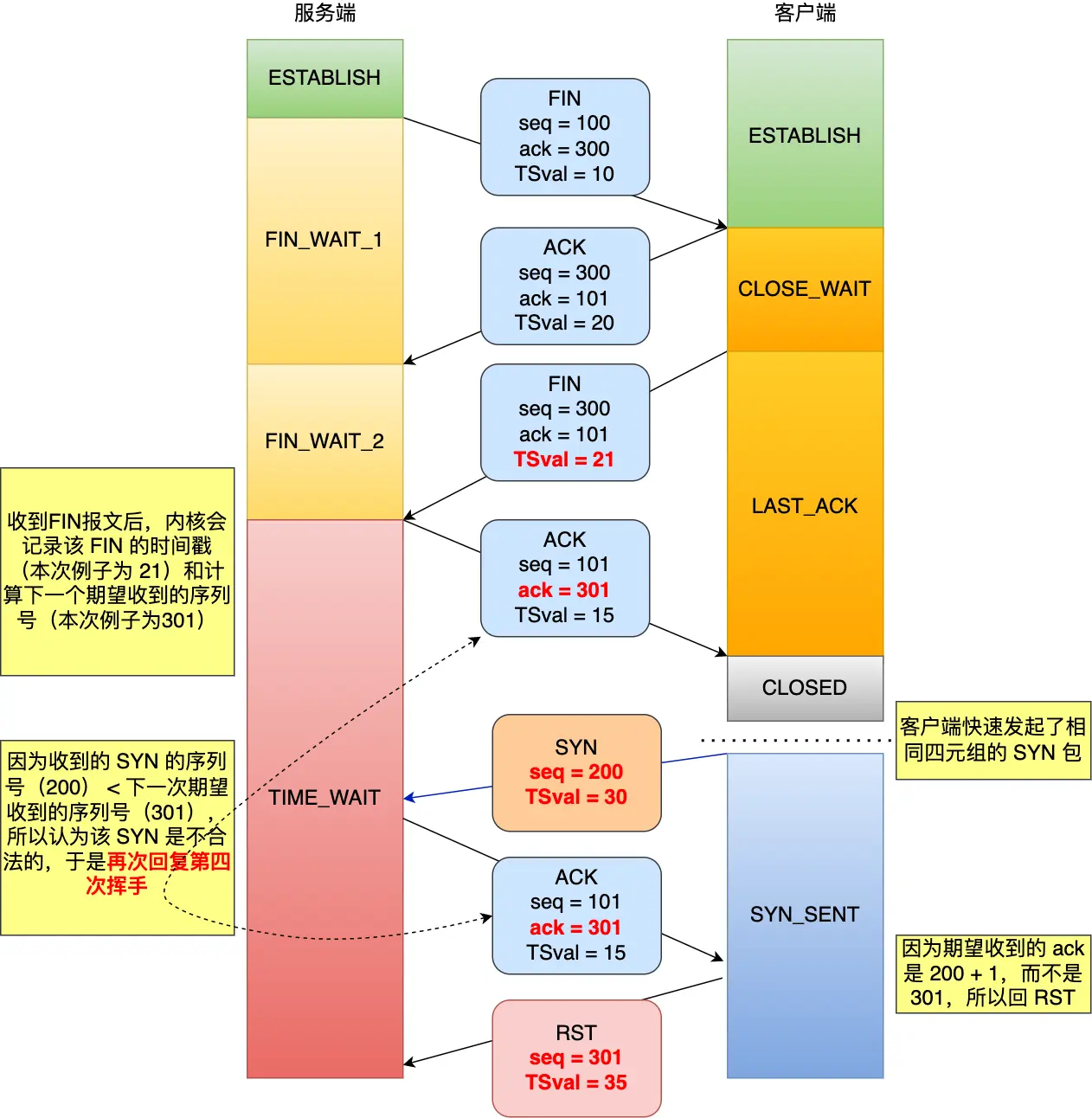
这里的合法是指:SYN 报文的 Seq 比 Server 期望的 Seq 大
如果启用了时间戳机制,那么 还要保证 SYN 报文的 timestamp 比 Server 期望的 timestamp 大
处于 TIME_WAIT 的连接,收到 RST 报文怎么处理?
在 RST 报文合法的前提下,处理方式与 tcp_rfc1337 参数有关
- 0: 提前结束 TIME_WAIT,关闭 TCP 连接
- 1: 丢弃 RST 报文
默认值为 0,但建议修改成 1
TIME_WAIT 是我们的朋友,它是有助于我们的,不要试图避免这个状态,而是应该弄清楚它。 —《UNIX 网络编程》
虽然 TIME_WAIT 状态持续的时间是有一点长,显得很不友好,但是它被设计来就是用来避免发生乱七八糟的事情。
TCP 连接,客户端进程崩溃与断电,分别发生什么?
客户端进程崩溃
客户端进程崩溃,内核会自动关闭进程建立的 TCP 连接
客户端断电
服务端对客户端断电是无感的,分两种情况考虑:
- 如果有数据传输,那么服务器会因为收不到 ack,而持续重传,直到重传次数上限
- 如果没有数据传输,那么只能依靠 TCP 的 keep-alive 机制来断开连接了
客户端拔掉网线后,原本的 TCP 连接还存在吗?
存在
拔掉网线,并不会直接影响已存在的 TCP 连接
如果客户端与服务器之间 没有数据传输 ,那么断开网线的过程,对双方都是无感的,当然,甚至,如果没启用 keep-alive,TCP 连接将一直建立
当然,如果二者之间存在数据传输,那么会由于重传次数到达上限导致 TCP 连接断开
Linux 为什么默认关闭了 tcp_tw_reuse 选项?
首先弄清楚 tcp_tw_reuse 选项的作用
如果启用了 tcp_tw_reuse,对于 客户端 而言,在调用 connect 时,若 connect 的「四元组」处于 TIME_WAIT 状态,并且 时间超过 1s,就可以重用该四元组建立新的连接
ps:启用 tcp_tw_reuse,需要同时开启 tcp_timestamp
如果启用 tcp_tw_reuse,对于客户端而言,就相当于没有 TIME_WAIT,或者时间很短
TIME_WAIT 的作用:
- 防止历史报文对现有连接的干扰
- 保证被动关闭方能正确关闭
第二点好理解,但第一点呢?
不是开启了 timestamp 吗?就算序列号「回环」了,也不会有历史报文的干扰啊?
事实上,对于 RST 报文,timestamp 规则不再适用
It is recommended that RST segments NOT carry timestamps, and that RST segments be acceptable regardless of their timestamp. Old duplicate RST segments should be exceedingly unlikely, and their cleanup function should take precedence over timestamps.
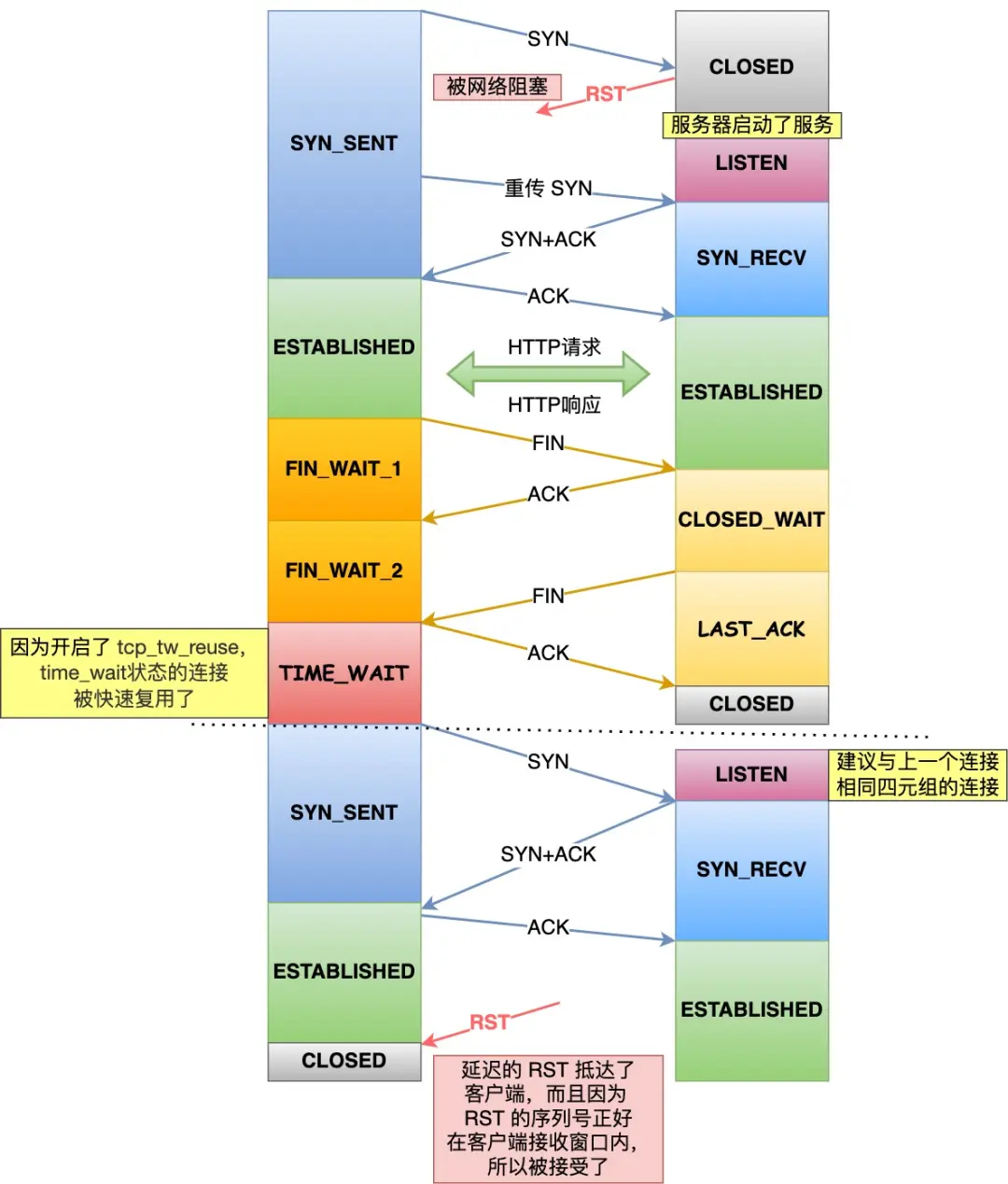
这导致了连接的非正常关闭
因此,为了 TIME_WAIT 能正常发挥作用,Linux 默认关闭了 tcp_tw_reuse
HTTPS 中,TCP 三次握手与 TLS 握手能同时进行吗?
可以,但有前提
我们知道,传统的 HTTPS 的建立,需要经过 TCP 三次握手 + TLS 四次握手
但是,如果
- 打开了 TCP 的快启动(TFO),以及使用 1.3 版本的 TLS
- Client 与 Server 已经通信过一次
就可以实现「同时」进行
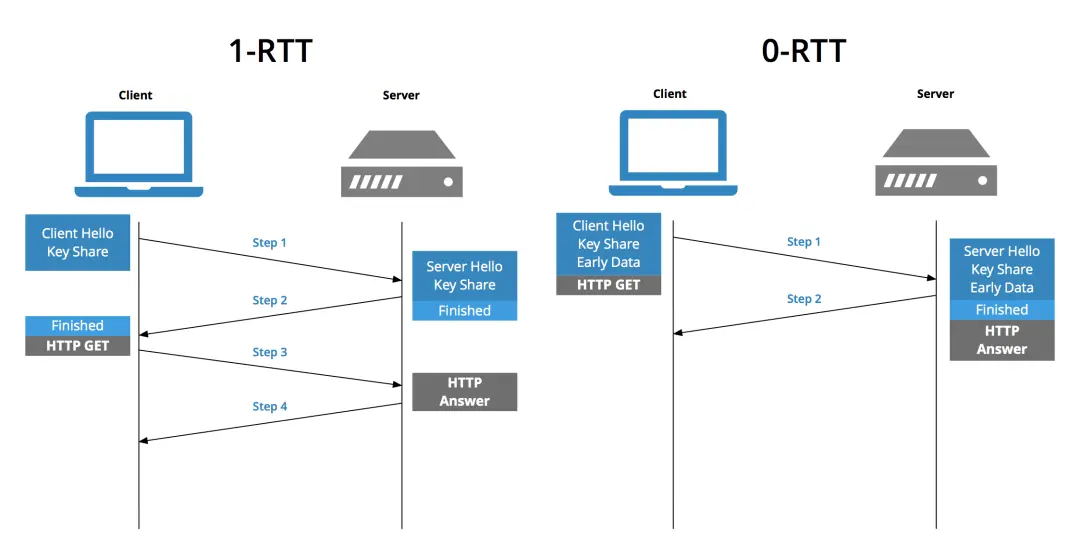
TLS 1.3 引入了 会话恢复 机制,在第二次建立连接,只需要 0-RTT
结合 TFO,在第一次握手时,携带 Cookie + TLS1.3 的 Client Hello,Server 就可以在三次握手结束前,发送 Server Hello,建立 TLS 连接
TCP 的缺点
- 实现在传输层,如果需要修订,需要动内核
- 建立连接繁琐
- 存在「队头阻塞」
- 不支持连接迁移
QUIC 协议
概念
QUIC 是基于 UDP,在应用层实现的具有可靠传输、流量控制、拥塞控制的协议
目前,HTTP/3 的实现就是基于 QUIC 协议的
结构
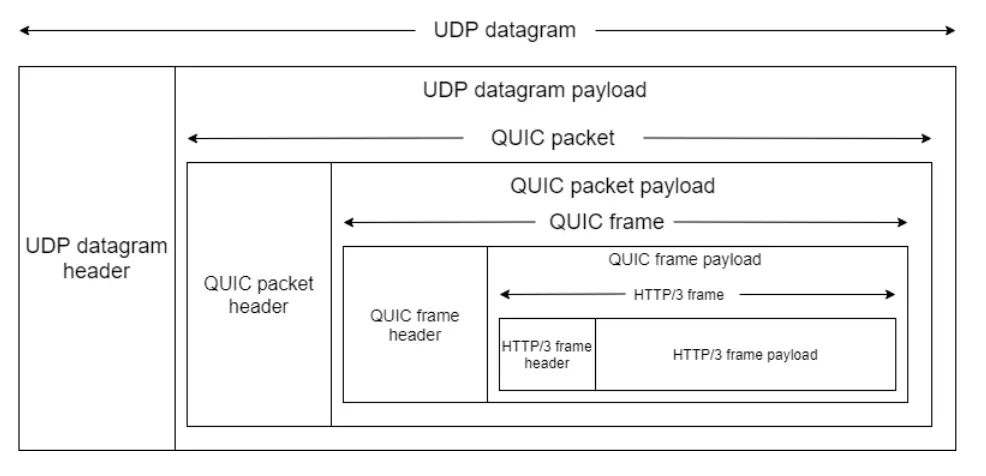
Packet
首先是 Packet Header,有两类:
- Long Packet Header:初次建立连接使用
- Short Packet Header:后续通信使用
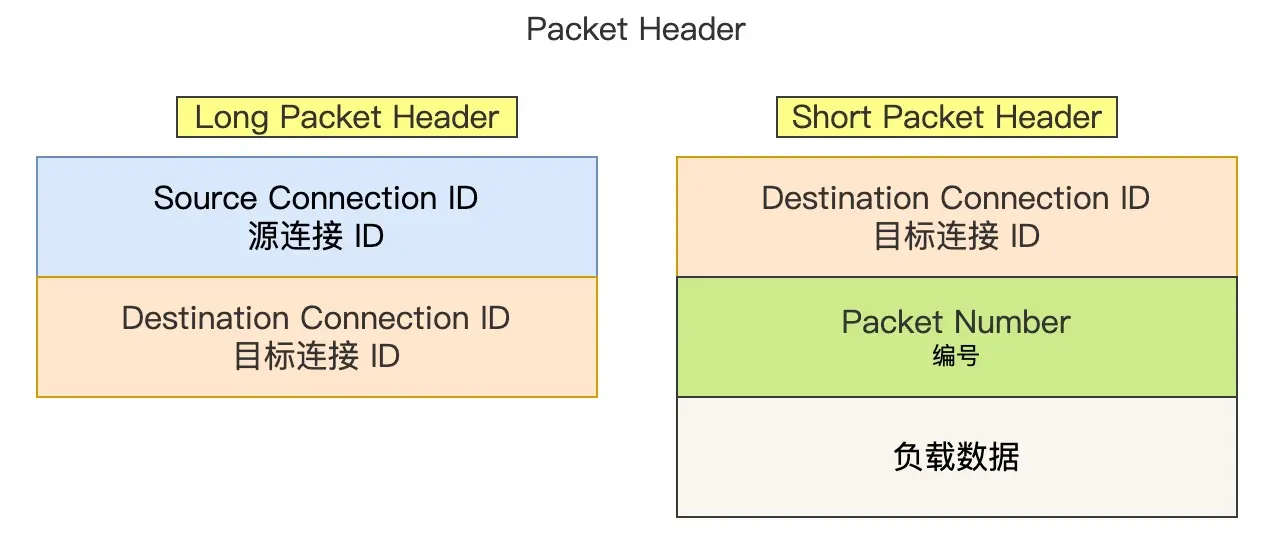
QUIC 使用 ConnectionID 来标明每一个连接
每一个 packet,都有一个 唯一的 PacketNumber,这个值是严格递增的
使用严格递增的 PacketNumber,相较于 TCP 的 Seq,有两个优点:
- 支持乱序确认
- 更精确的计算 RTT,从而得到更精确的 RTO
Frame
每一个 Packet 中,包含了若干个 Frame
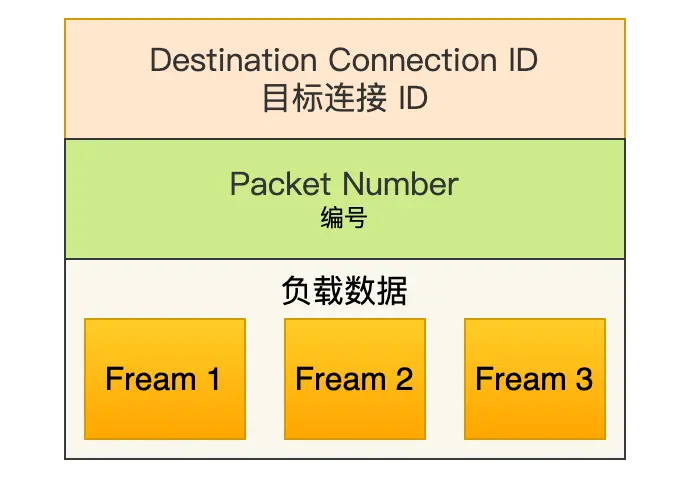
Frame 有多种类型,这里仅介绍 Stream 类型
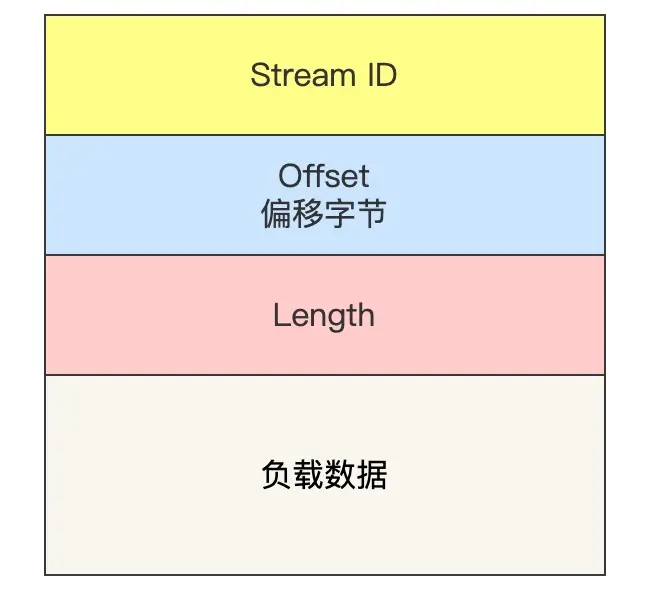
- StreamID:区别多个并发的 HTTP 连接
- Offset:类似 TCP 的 Seq,保证 同一个 Stream 内数据的有序性
- Length:负载数据的长度
三次握手
QUIC 协议的连接整合了 TCP 的三次握手和 TLS1.3 的安全握手。
-
客户端发送 Initial 包:客户端首先生成一个独特的 Connection ID,并将其包含在 Initial 包中。这个包还包含一个 TLS 客户端 Hello 消息,内含用于握手和认证的相关参数。
-
服务器回应 Initial 包:收到 Initial 包后,服务器会生成自己的 Connection ID,并回传一个 Initial 包,包含 TLS 服务器 Hello 消息,并可能还包含 TLS 的证书和 Finished 信息。
-
客户端发送第二个 Initial 包:客户端会解密服务端发来的 Initial 包,并验证其中所包含的服务器证书。在验证通过后,客户端会产生一个新的 Initial 包,其中包含 TLS 的 Finished 信息,以确认握手的完成。此后,双方就建立起了一个加密的通信连接。
重传机制
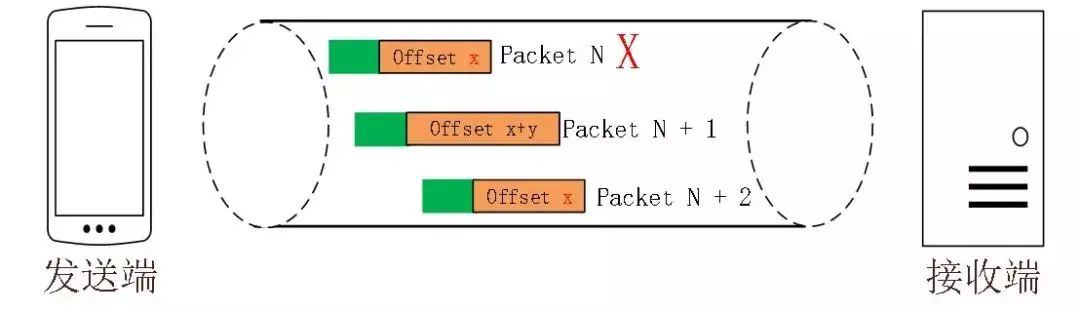
你可能会想:QUIC 的每个包的 PacketNum 都不一样,重传时,接收方怎么判断一个报文是新的 packet,还是重传的 packet?
实际上,QUIC 使用 StreamID + Offset 来唯一确定
即使两个包的 packetNum 不同,但只要 StreamID + Offset 相同,就认为这两个包是相同的
流量控制
QUIC 也使用窗口来进行流量控制,有两个维度:
- Stream
- Connection
Stream
对于同一个 Packet 的多个 Stream 而言,每个 Stream 有自己独立的接收(发送)窗口
因此,QUIC 可以实现基于 Stream 的细粒度的流量控制
Connection
可以认为有一个「大」的窗口来控制整个 QUIC 连接的流量,其大小为所有 Stream 的窗口大小之和
如何解决队头阻塞
前面提到每个 Stream 有自己独立的接收(发送)窗口
Stream 之间是独立的,没有关联(理解成并行的 HTTP 连接)
因此,即使某个 Stream 的数据出现了丢失,也不会影响其它 Stream
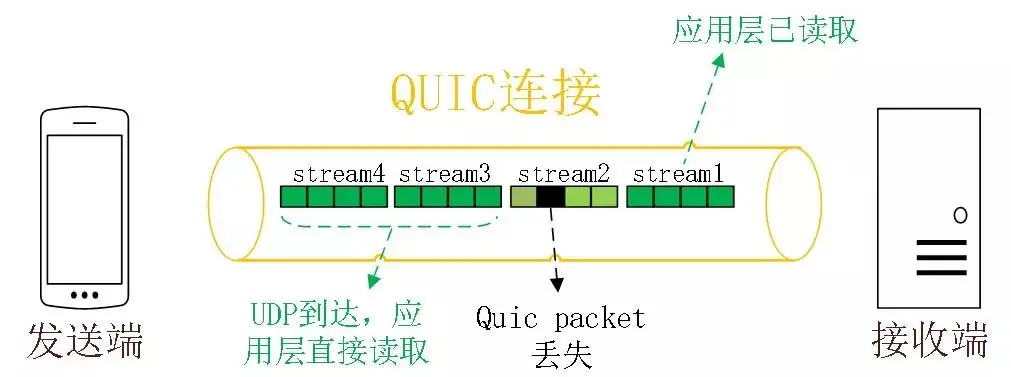
所以说 QUIC 解决了不同 Stream 间的队头阻塞问题,实现了「真正的」并行
连接迁移
前面提到,QUIC 基于 ConnectionID 来标识每一个 QUIC 连接
当用户的网络更改(如 WLAN 切换到 5G),也不用重新建立连接,复用 Connection ID 等上下文信息即可
优势
经过上面的分析,可以总结:相较于 TCP,QUIC 有以下优势:
- 基于应用层实现,便于修订
- 更快的连接建立:整合三次握手 + TLS 握手
- 细粒度的流量控制:解决队头阻塞,实现「并行」传输
- 支持连接迁移
参考资料:如何基于 UDP 协议实现可靠传输
端口问题
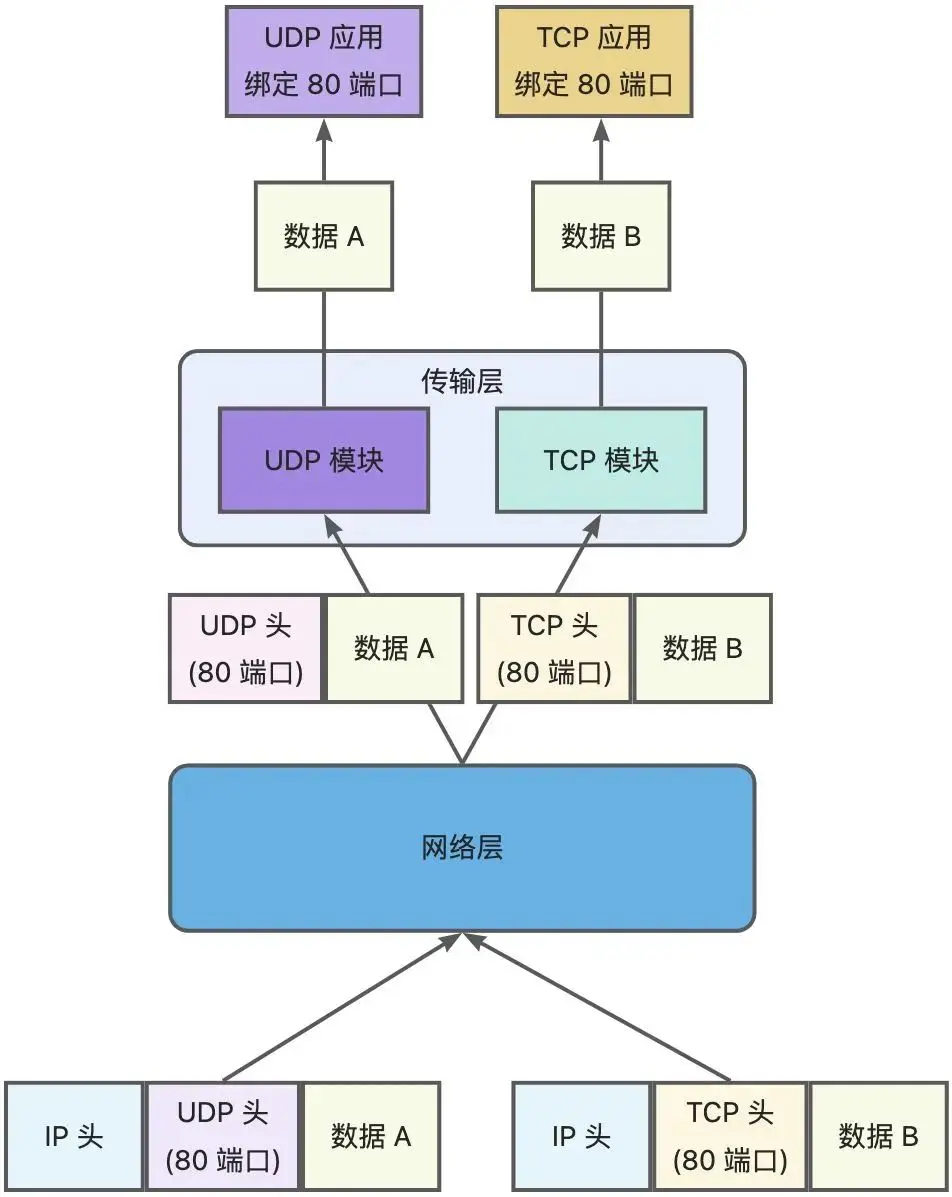
TCP 和 UDP 可以使用同一个端口吗?
可以
TCP 与 UDP 为传输层的不同协议,接收数据时,当有数据从网卡过来,会在网络层判断这个数据包是哪个协议的,进而送到不同协议栈去处理
多个 TCP 服务进程可以使用同一个端口吗?
分情况
- 如果两个 TCP 服务进程的监听的 IP + Port 都相同,就不能使用同一端口
- 如果监听的 IP 不同,就可以使用同一端口
注意:如果某个进程监听的 IP 为 0.0.0.0,第二个原则就失效了,因为监听 0.0.0.0 意味着监听了本机的所有 IP
如何解决服务器快速重启,出现 “Address already in use”?
这个问题的出现,是因为快速重启时,监听的 IP、监听的 Port、目的 IP *、目的端口 * 四元组对应的连接还处于 TIME_WAIT 状态
因此,会提示地址被占用
服务器可以在设置 socket 的时候加上 SO_REUSEADDR 选项,以复用处于 TIME_WAIT 的连接
多个 TCP 客户进程可以使用同一端口吗?
一样的,对于同一个四元组对应的连接,只要连接建立,端口就不能复用
相反,只要连接不同(如服务器 IP 不同),就可以使用相同的端口
Server 没有调用 listen,Client 发起连接,会发生什么?
如果 Server bind 了某个 IP + Port,但 没有 listen,当 Client 发送 SYN 给 Server,Server 不会回 ACK 给 Client
Client 会一直重试,直到重试次数达到上限
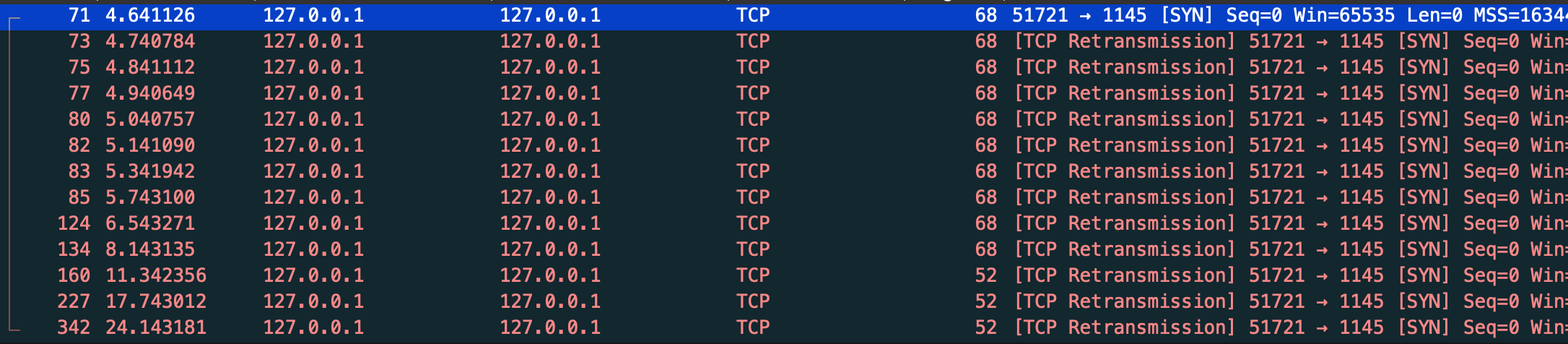
但是,如果 Server 没有 bind 客户端的目的 IP + Port ,Client 发起连接,Server 会直接发一个 RST 报文给对方

通常情况下,当一个连接请求到达本地却没有相关进程在目的端口侦听时就会产生一个重置报文段。
UDP 协议规定,当一个数据报到达一个不能使用的目的端口时就会产生一个 ICMP 目的地不可达(端口不可达)的消息。TCP 协议则使用 重置报文段 来代替完成相关工作。
-- 《TCP/IP详解 卷1:协议(原书第2版)》第 13.6.1 节
半连接队列、全连接队列的本质?
虽然都有「队列」二字,但二者 实际上都不是队列
- 当一个连接请求到来,内核会将连接元数据存到 半连接队列,发送 ack
- 收到某个连接的 ack 的 ack 后,从半连接队列中取出该连接,发送 ack,并放到 全连接队列 中
- 服务进程调用 accept,取出一个建立好的 TCP 连接
“收到某个连接的 ack 的 ack 后,从半连接队列中取出该连接”的「取出」过程是一个随机的过程,因为这个 ack 的顺序并不固定
如果半连接队列设计成线性结构,那么取出对应连接就需要 O(n) 的时间
因此,半连接队列实际上是一个哈希表,取出对应连接的期望时间是 O(1)
而全连接队列实际上是一个链表,当然,也可以理解成队列(毕竟队列也有基于链表实现的)
没有 accept,可以建立 TCP 连接吗?
弄清楚 accept 的本质:从全连接队列中取出一个 已经建立好的连接,处理接下来的请求
也就是说,在 accept 前,TCP 连接就已经建立好了
因此,accept 与建立 TCP 连接之间没有关系,没有 accept,当然可以建立 TCP 连接
没有 listen,为什么可以建立连接?
以 TCP 自连接为例:
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <errno.h>
#define LOCAL_IP_ADDR (0x7F000001) // IP 127.0.0.1
#define LOCAL_TCP_PORT (1145) // 端口
int main(void)
{
struct sockaddr_in local, peer;
int ret;
char buf[128];
int sock = socket(AF_INET, SOCK_STREAM, 0);
memset(&local, 0, sizeof(local));
memset(&peer, 0, sizeof(peer));
local.sin_family = AF_INET;
local.sin_port = htons(LOCAL_TCP_PORT);
local.sin_addr.s_addr = htonl(LOCAL_IP_ADDR);
peer = local;
int flag = 1;
ret = setsockopt(sock, SOL_SOCKET, SO_REUSEADDR, &flag, sizeof(flag));
if (ret == -1) {
printf("Fail to setsocket SO_REUSEADDR: %s\n", strerror(errno));
exit(1);
}
ret = bind(sock, (const struct sockaddr *)&local, sizeof(local));
if (ret) {
printf("Fail to bind: %s\n", strerror(errno));
exit(1);
}
ret = connect(sock, (const struct sockaddr *)&peer, sizeof(peer));
if (ret) {
printf("Fail to connect myself: %s\n", strerror(errno));
exit(1);
}
printf("Connect to myself successfully\n");
//发送数据
strcpy(buf, "Hello, myself~");
send(sock, buf, strlen(buf), 0);
memset(buf, 0, sizeof(buf));
//接收数据
recv(sock, buf, sizeof(buf), 0);
printf("Recv the msg: %s\n", buf);
sleep(1000);
close(sock);
return 0;
}
运行,抓包结果如下:

可以发现,自连接也是需要三次握手建立连接
- 当发起 connect 系统调用,内核会将连接信息放到一个全局 hash 表中,再将连接消息发出,
- 由于是一个回环地址(127.0.0.1),消息又回到传输层
- 内核检测有没有进程 bind 了该 IP + Port,有
- 于是直接从全局 hash 表取出连接信息,发现源 IP、Port 与目的 IP、Port 相等,直接建立连接
用了 TCP,数据就一定不会丢失吗?
建立连接丢包
如果 Server 的半连接队列或者全连接队列满了,会丢弃新的连接请求
流量控制丢包
事实上,数据在被发送前,还需要排队
qdisc 是"queueing discipline"的缩写,也就是排队规则,位于网络模型的链路层和网络层之间,它主要在操作系统内核对数据包进行排队,策略路由,速率限制等操作。
qdisc 有容量限制,如果应用发送速率太快,导致队列的数据包太多,超过容量限制,内核就会丢弃这些数据包
可以使用 tc 查看某个设备是否因为流量控制丢包:
[skylee@localhost Test]$ tc -s qdisc show dev ens33
qdisc pfifo_fast 0: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 6092849 bytes 20768 pkt (dropped 0, overlimits 0 requeues 1)
backlog 0b 0p requeues 1
网卡丢包
接收数据时,网卡会先将数据放到 ringbuffer 中
如果 ringbuffer 满了,还有新的数据包到来,就会丢包
可以使用 ifconfig 查看是否因为 ringbuffer 满了导致丢包:
[skylee@localhost Test]$ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.124.114 netmask 255.255.255.0 broadcast 192.168.124.255
RX packets 127108 bytes 177474834 (169.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
RX dropped 为 0,说明没有发生
可以通过 ethtool 查看网卡配置:
[skylee@localhost Test]$ ethtool -g <device name>
Ring parameters for ens33:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 256
RX Mini: 0
RX Jumbo: 0
TX: 256
ringbuffer 的大小为 4096,但是只用了 256
可以使用 ethtool 修改 ringbuffer 的大小:
[root@localhost Test]# sudo ethtool -G ens33 rx 4096 tx 4096
接收缓冲区满导致丢包
如果接收缓冲区满了,接收方通常会发送一个「零窗口通告」报文
但发送方如果仍继续发送数据,那么将会导致丢包
不过这种情况一般不会出现,收到「零窗口通告」,发送方应该停止发送数据
两端中间节点丢包
数据包的传输,需要经过许多节点,如果这些节点出现问题(如路由器负载高),可能发生丢包
可以使用 mrt(my trace route)工具来查看是否出现这个问题:
[root@localhost Test]# mtr -r baidu.com
Start: Wed Jan 31 11:13:41 2024
HOST: localhost.localdomain Loss% Snt Last Avg Best Wrst StDev
1.|-- gateway 0.0% 10 0.4 0.6 0.4 0.8 0.0
2.|-- 192.168.0.1 0.0% 10 1.9 8.1 1.5 62.3 19.0
3.|-- 192.168.1.1 0.0% 10 2.8 2.8 2.3 3.6 0.0
4.|-- 100.69.0.1 0.0% 10 6.1 6.9 4.9 12.5 2.2
5.|-- 110.190.151.153 50.0% 10 9.7 6.9 5.6 9.7 1.5
6.|-- 171.208.198.185 40.0% 10 8.2 8.4 7.8 9.0 0.0
7.|-- 202.97.78.189 20.0% 10 31.5 31.9 30.8 32.9 0.5
8.|-- 202.97.17.74 30.0% 10 35.9 36.8 35.9 37.8 0.0
9.|-- 221.183.128.137 30.0% 10 36.1 37.0 36.1 38.7 0.7
10.|-- 221.183.94.21 60.0% 10 38.5 39.1 38.5 39.8 0.0
11.|-- 221.183.49.122 0.0% 10 36.5 37.5 36.0 38.9 0.8
12.|-- 111.13.188.38 0.0% 10 37.5 37.9 37.3 38.9 0.0
13.|-- 39.156.27.1 20.0% 10 37.6 37.6 37.0 38.9 0.0
14.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.0
15.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.0
16.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.0
17.|-- ??? 100.0 9 0.0 0.0 0.0 0.0 0.0
18.|-- 39.156.66.10 0.0% 9 40.1 40.1 39.1 41.7 0.5
最后一行是 0,说明没有丢包(不用管前面的)
但是,如果不是 0,例如:
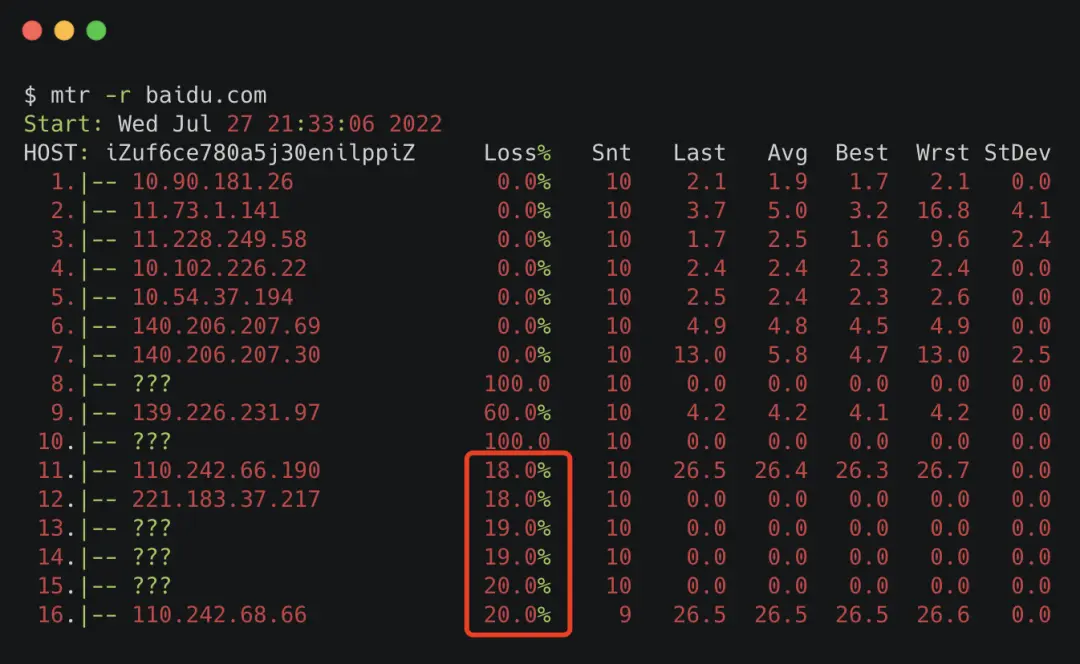
说明丢包是从最接近的那一行产生的(这个示例为 11 行)
如果这个 IP 是内网的话,就可以根据 IP 排查一波
当然,由于 TCP 的重传机制,即使中间节点丢包,只要不超过最大重传次数,TCP 也可以保证数据的可靠到达
回归问题
那么,使用了 TCP 就一定不会丢包吗?
经过前面的分析,可以发现:
- 建立连接时,如果半连接队列、全连接队列满了
- 流量控制,qdisc 满了
- 网卡的 ringbuffer 满了
都有可能导致丢包
当然,接收缓冲区满了,或者中间节点丢包,这两个问题,TCP 可以解决
但还有一种情况,就是在「应用层」发生了 “丢包”:
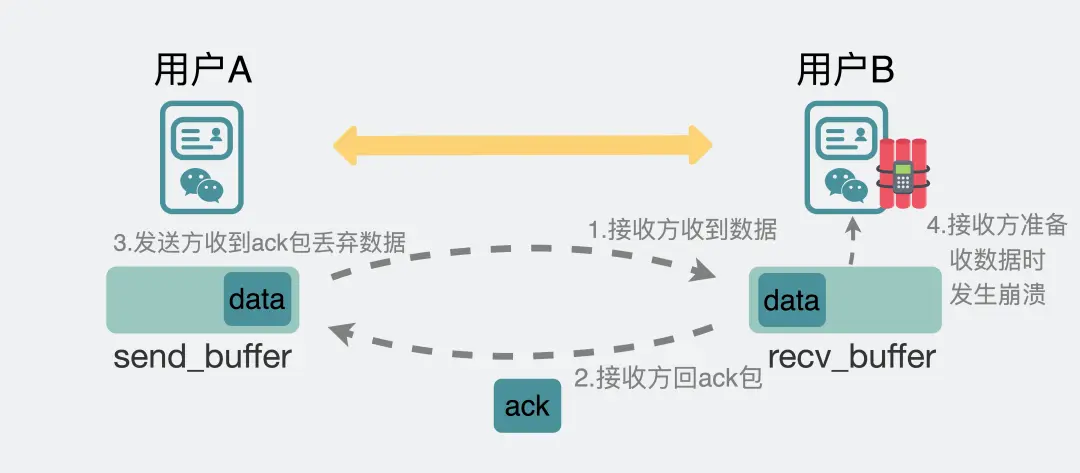
应用在从接收缓冲区取出数据,还没来得及本地持久化,就崩溃了
再次启动,会发现「消息」就丢失了
因此,TCP 只能保证传输层的「可靠」
如何解决?
- 建立连接产生的「丢包」,可以调整队列的容量(backlog、SOMAXCONN、tcp_max_syn_backlog)
- 流量控制产生的丢包,可以调整 qdisc 策略
- 网卡 ringbuffer 满了产生的丢包,可以调整 ringbuffer 的大小
对于上面提到的应用层丢包的示例,可以在发送接收双方添加一个 Server,消息先持久化到 Server,即使应用崩溃了,也可以在 Server 拉取同步数据
shutdown 与 close
shutdown 可以控制关闭 socket 的读端还是写端,而 close 是直接关闭 socket
// server.cpp
#include "TCPSocket.hpp"
#include <iostream>
int main(void)
{
auto serverSocket = new TCPSocket("127.0.0.1", 1145, 100);
auto socket = serverSocket->accept();
std::cout << "Linked with " << socket->getIP() << ":" << socket->getPort() << std::endl;
socket->send("hello");
sleep(100000);
// socket->close();
delete socket;
}
// client.cpp
#include "TCPSocket.hpp"
#include <cstdio>
int main(void)
{
auto clnt_sock = new TCPSocket();
clnt_sock->connect("127.0.0.1", 1145);
printf("connented with server\n");
clnt_sock->close();
sleep(100000);
}
Client 调用 close 后,如果 Server 在 CLOSE_WAIT 阶段向 Client 发送数据,Client 会发送 RST 报文给 Server,直接终止 TCP 连接

如果 Client 调用的是 shutdown,只关闭写端,那么是可以正常关闭 TCP 连接的
// client.cpp
#include "TCPSocket.hpp"
#include <cstdio>
int main(void)
{
auto clnt_sock = new TCPSocket();
clnt_sock->connect("127.0.0.1", 1145);
printf("connented with server\n");
int socket = clnt_sock->native_sock();
shutdown(socket, SHUT_WR);
std::cout << clnt_sock->receive() << "\n";
sleep(100000);
clnt_sock->close();
}

It’s important to note that shutdown() doesn’t actually close the file descriptor—it just changes its usability. To free a socket descriptor, you need to use close().
In contrast, close() will not only send a FIN packet but will also release the socket descriptor and any associated resources. It’s worth noting that if close() is called while data is still in the send buffer, the system will attempt to send this data to the peer before fully closing the connection.
Keep in mind, to ensure all resources are properly cleaned up, you should always close() a socket when you’re done with it, even if you’ve already called shutdown().
shutdown 只是改变了文件描述符的「可用性」,要真正释放资源,必须调用 close,总结如下:
- 作为被动关闭方,直接调用 close
- 作为主动关闭方,如果有读/写的需求(这需要双方的协商,即自定协议),可以先使用 shutdown,但 最后一定要调用 close 关闭 socket