虚拟内存
为什么要有虚拟内存?
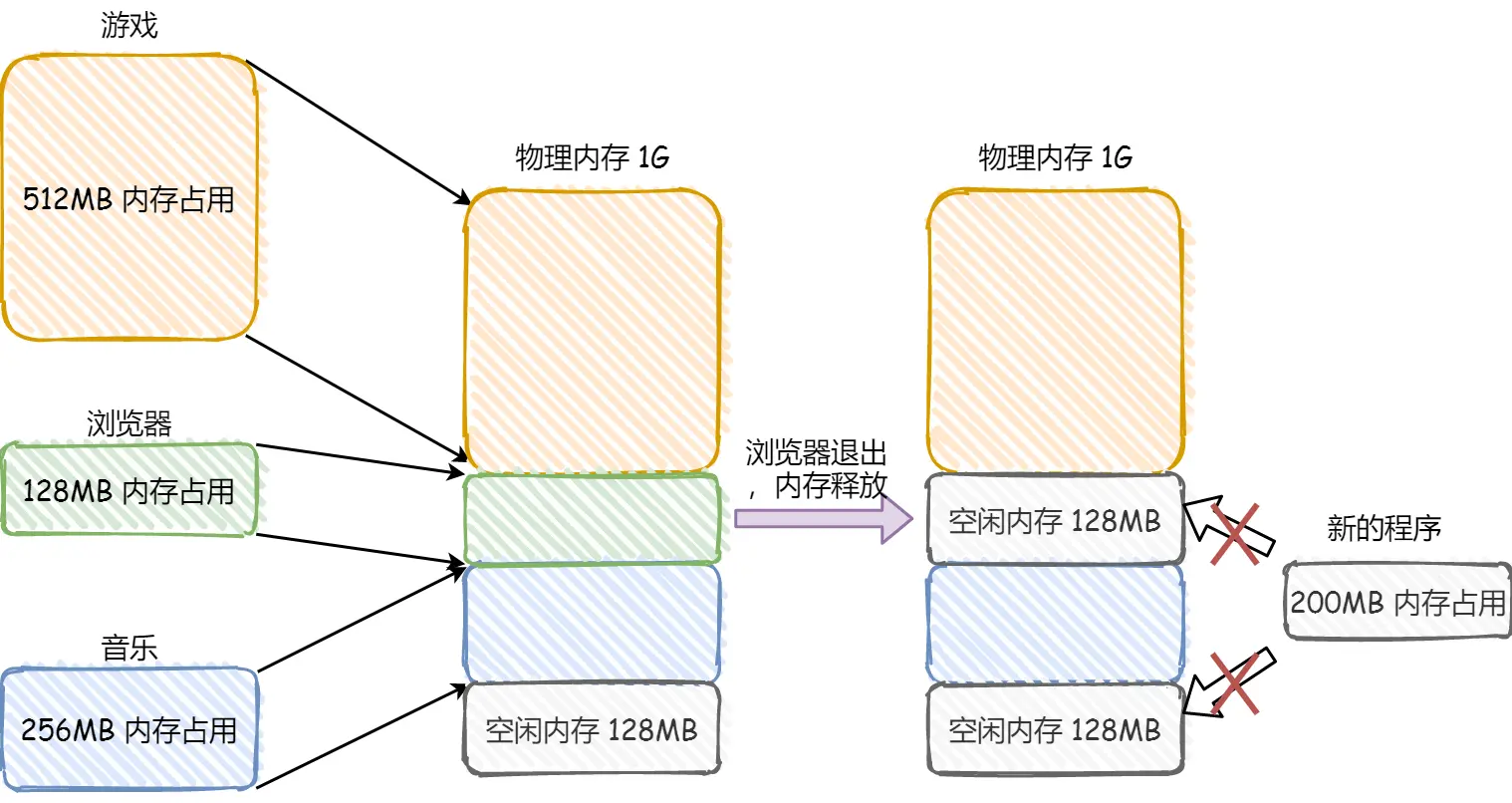
如果每个进程都直接操作物理内存,存在安全问题:一个进程可以操作另一个进程的内存空间
对于单片机而言,采用的就是直接使用物理内存,因此,单片机只能运行一个进程
为了使进程彼此的内存空间隔离,OS 采用虚拟内存机制,每个进程都有自己独立的虚拟内存,相互不干扰,实现:
- 多任务处理
- 相互隔离,安全性保障
- 一个进程可以使用比物理内存更大的空间(swap)
内存分段
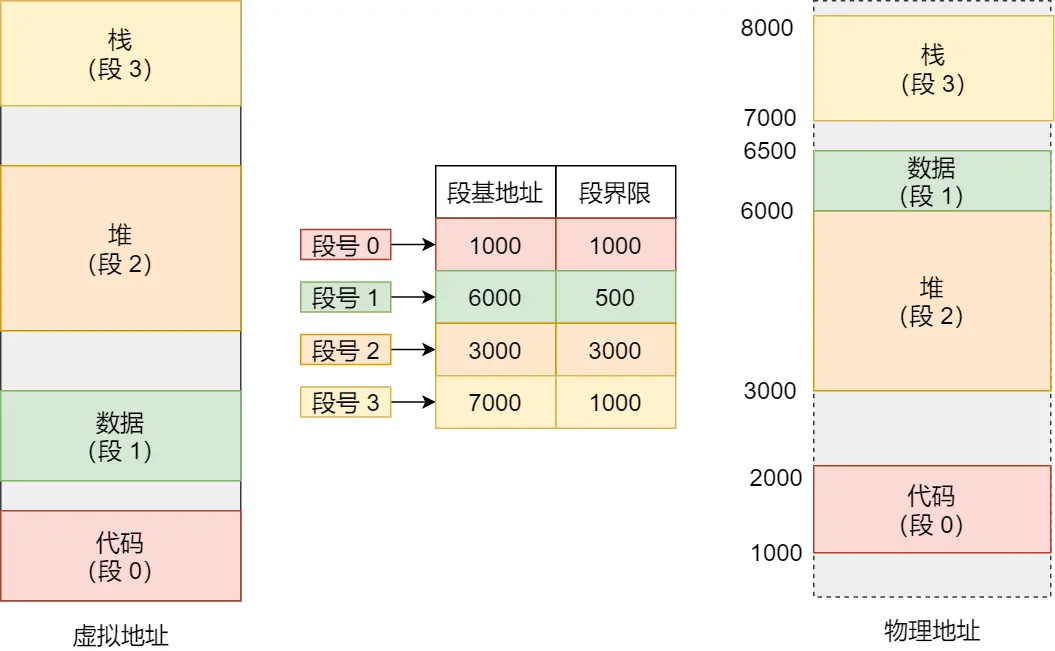
程序内部可以根据逻辑,分成若干个段:
- 代码段
- 数据段(.data)
- .bss
- 栈
- 堆
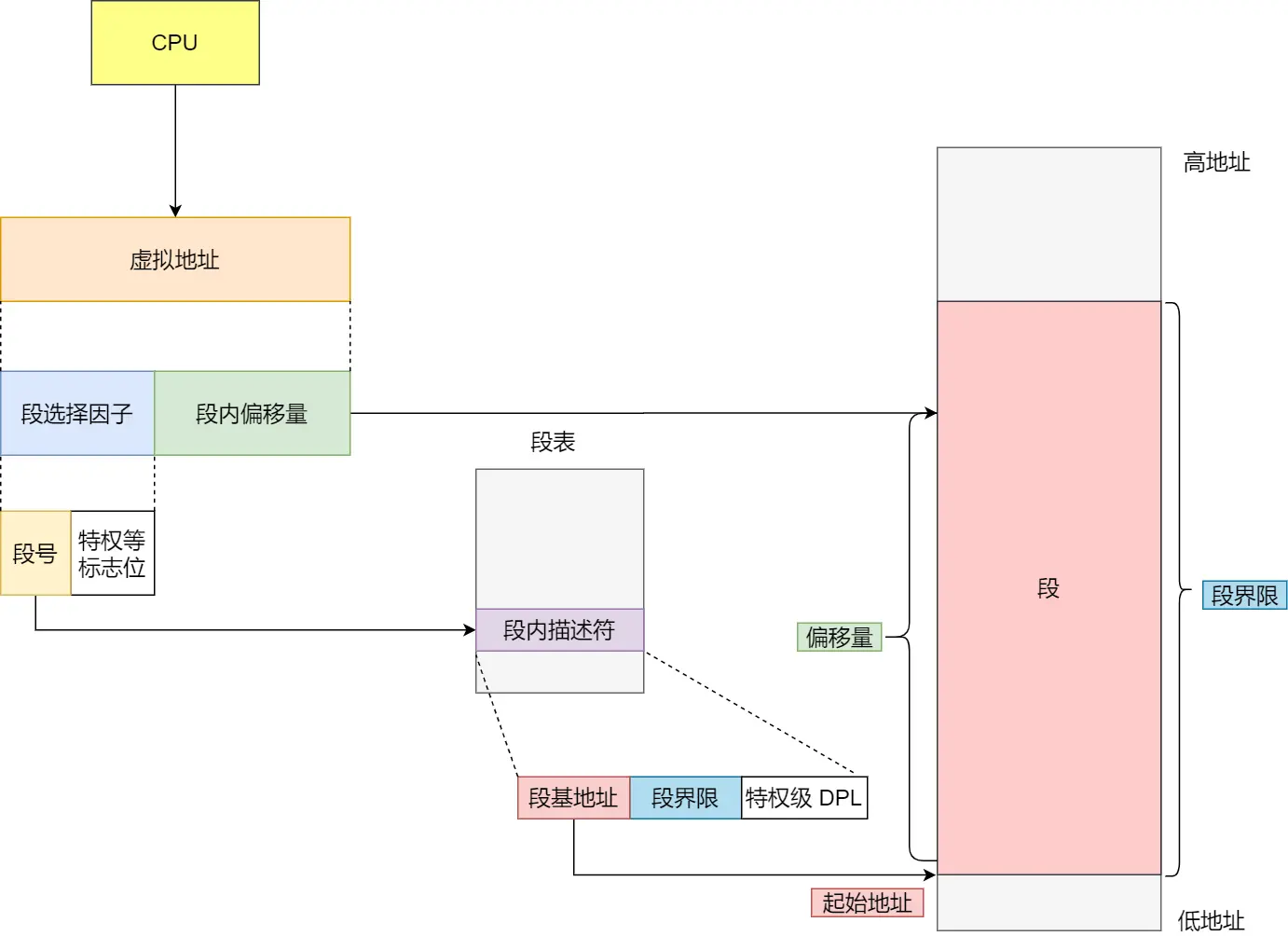
分段式管理内存的原理,就是基于程序分段的
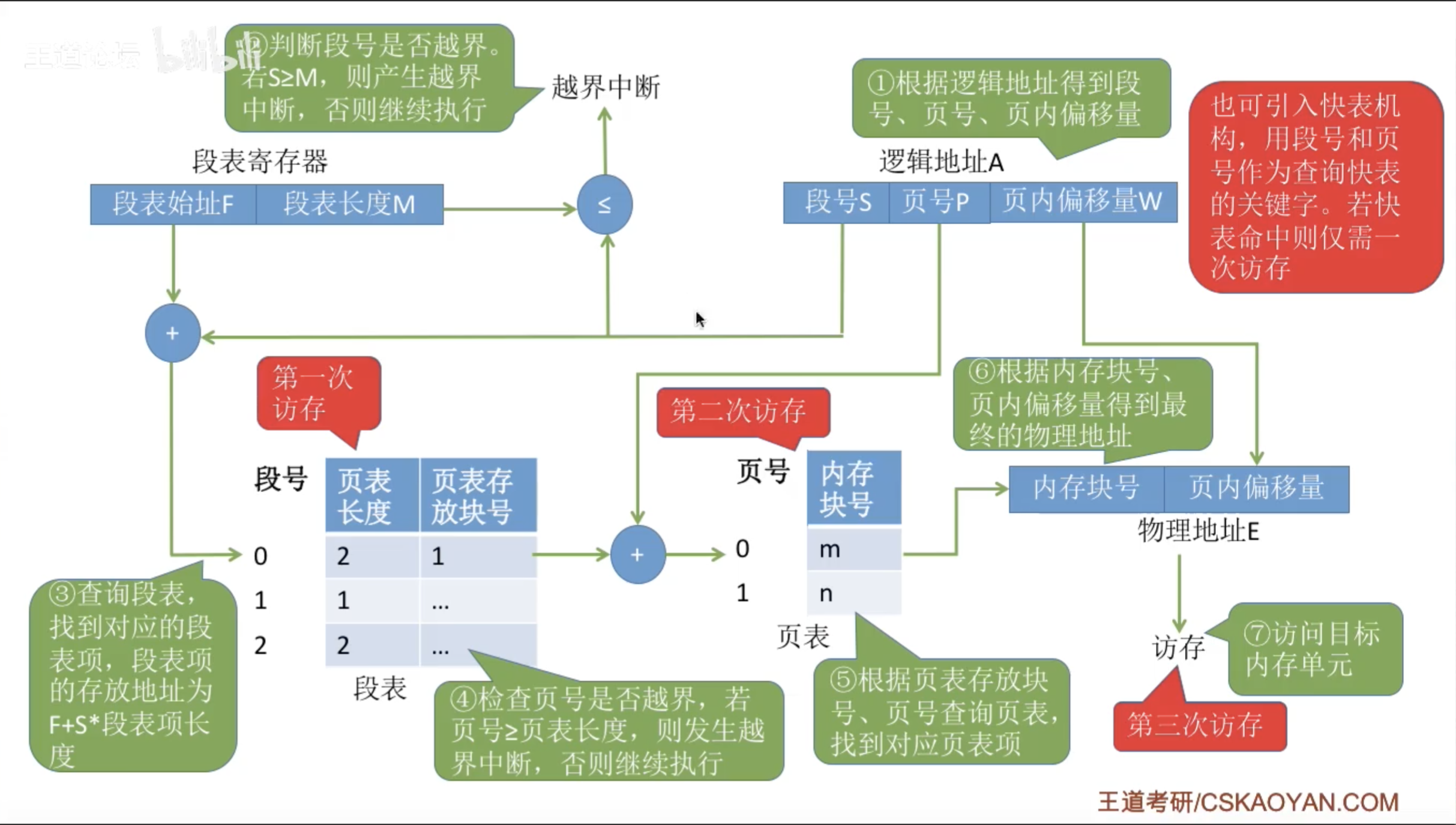
每个进程维护自己的一个 段表,段表记录了每一段对应的物理地址
进程可以通过计算逻辑地址代表的 段号、段内偏移,再查段表,来得到真实的物理地址
内存分段实现了进程彼此的内存隔离,确保了安全性,但是存在以下问题:
- 外部碎片
- 实现 swap 机制,需要大量的磁盘 IO
使用分段管理内存,交换的单位是段,而如果一个段太大,要换到磁盘,必然需要大量 IO
说说内存分页机制?
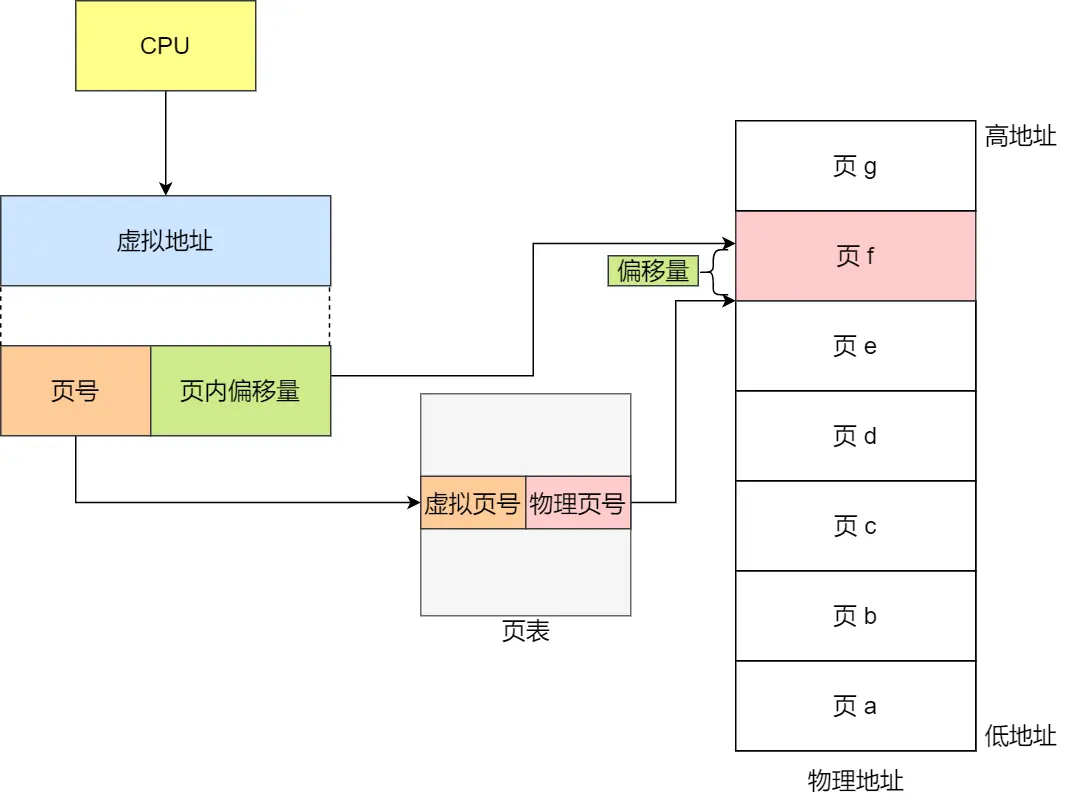
与分段不同,分页机制,OS 会将内存分成若干「页」,一般来说,一页的大小为 4K
每个进程维护自己的 页表,页表记录了每一页对应的起始物理地址
进程可以计算一个逻辑地址对应的 页号、页内偏移,以此得到真实的物理地址
采用内存分页管理,解决了分段管理的两个痛点,分页管理:
- 不会出现外部碎片
- 交换基本单位为「页」,粒度小,每页仅为 4K,成本低
简单内存分页的缺点
上面的分页方式就是简单内存分页,即只有一级页表
简单内存分页存在空间浪费的问题,例如,对于 4G 内存的系统来说,假设一页大小为 4K(2^12),那么单个页表就有 2^20 个页表项,所占的空间为 2^20 * 8b = 8M
对于一个进程而言,8M 看起来并不是很多,但是,一个系统运行的进程会很多,如果有 100 个,就需要 800M 的空间存放页表,太浪费空间了
如何解决简单内存分页导致的空间浪费问题?
在单级页表的基础上,再添加一层,形成多级页表
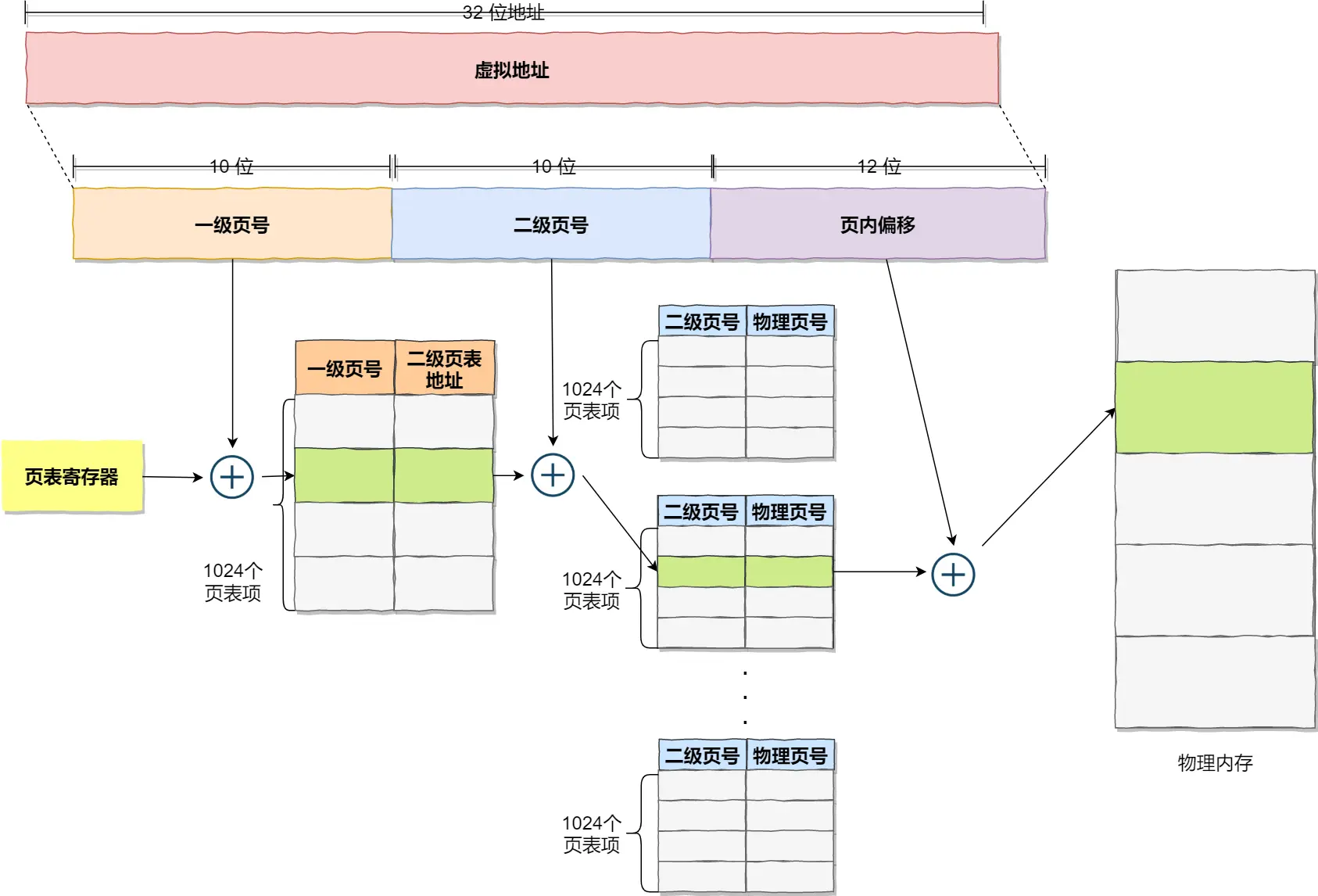
此时,完全 映射 4G 内存,所需空间为 8K(一级页表)+ 8M(二级页表)
那不是比一级页表占的空间更多了吗?
看起来是这样,但是,一个进程往往不会用到这么多内存,如果一个一级页表项没有用到,自然也不需要分配对应二级页表的空间
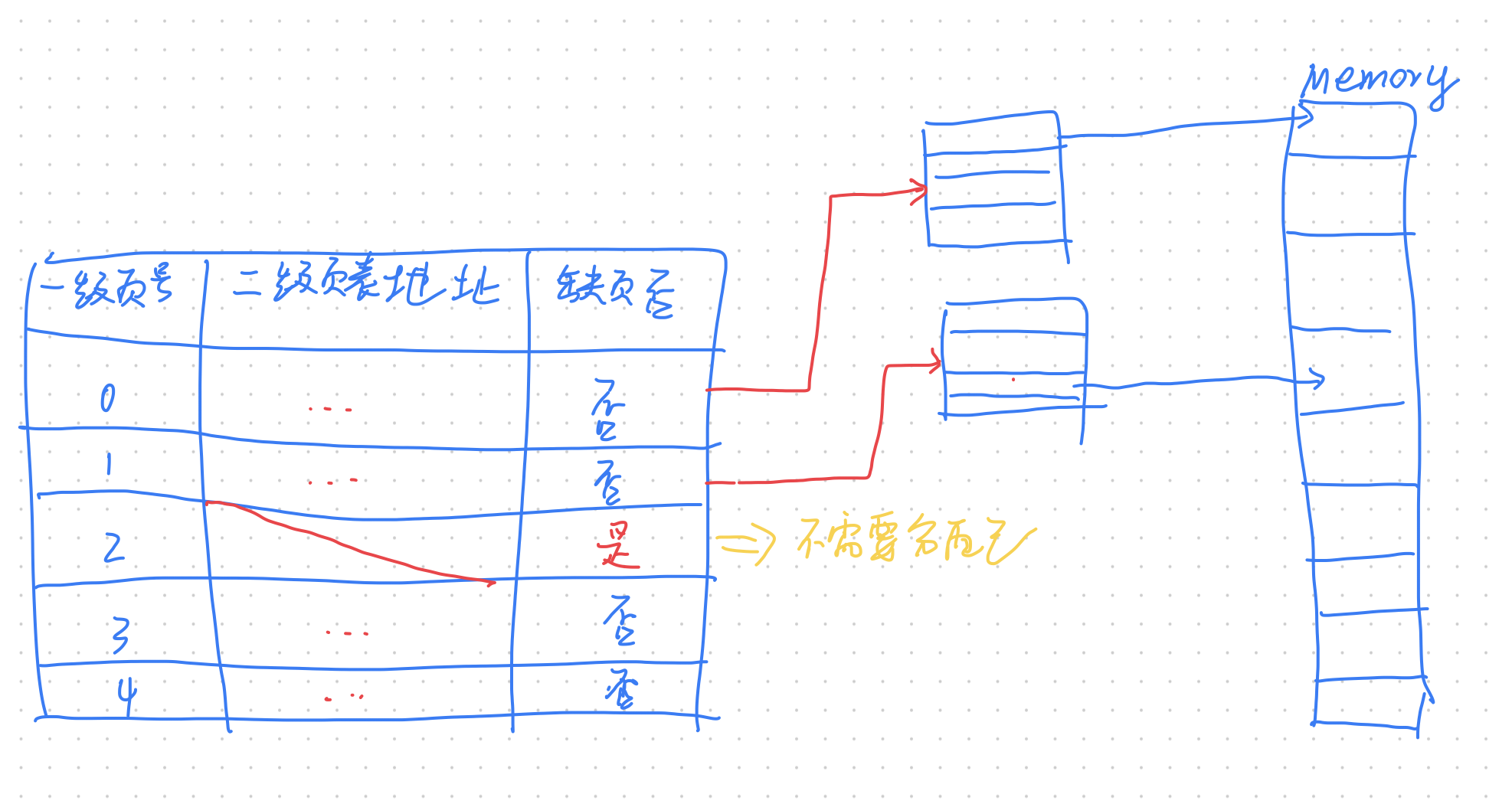
但是每引入一级页表,逻辑地址到物理地址的转换过程就多一步,性能会下降
如何解决多级页表带来的性能问题?
TLB,也叫快表
CPU 可以把访问频率较高的页表项缓存到快表中,这样,就 只需要一次访存
由于空间局部性原理,快表的命中率还是很高的
分段和分页是绝对的吗?
不是,还有段页式内存管理
谈谈 Linux 内存布局?
Linux 主要采取 页式管理 ,但是不可避免的涉及了段机制
由于历史原因,Intel 的 CPU 一律先进行段式映射,再进行页式映射,因此,Linux 无法避免段机制
但是,Linux 系统的每一个段都是以 0 为起始地址开始的整个内存空间,这样就相当于 屏蔽 了段的概念
Linux 的内存空间分布如下:
你认为分段和分页两者有什么区别?为什么 Linux 采用分页机制,而不是分段?
分段与分页两者最主要的区别在于:内存基本管理单元
分段管理,基本单元为 段;而分页管理,基本单位为 页
分段管理最严重的问题是:swap 不友好
基本管理单元为「段」,每个段的大小不一,可能较大,可能较小,如果要 swap 一个比较大的段到磁盘,速度慢,给用户体验就是延迟高
并且,分段管理容易出现外部碎片,这些碎片无法得到利用,造成浪费
而分页管理就没有这两个问题:
- 基本单位为「页」,swap 友好
- 虽然有内部碎片,但一个「页」很小,浪费比较少
因此,Linux 主要采取 页式管理,而不是分段
虚拟内存的作用?
- 保护进程之间的内存空间不受干扰,独立性保障
- 使进程可以使用比物理内存更大的空间(swap)
malloc
malloc 是怎么分配内存的?
malloc 是一个库函数,调用 malloc,有两种方式分配内存:
- 内部调用 brk 系统调用,在堆区分配内存
- 内部调用 mmap 系统调用,在文件映射区分配内存
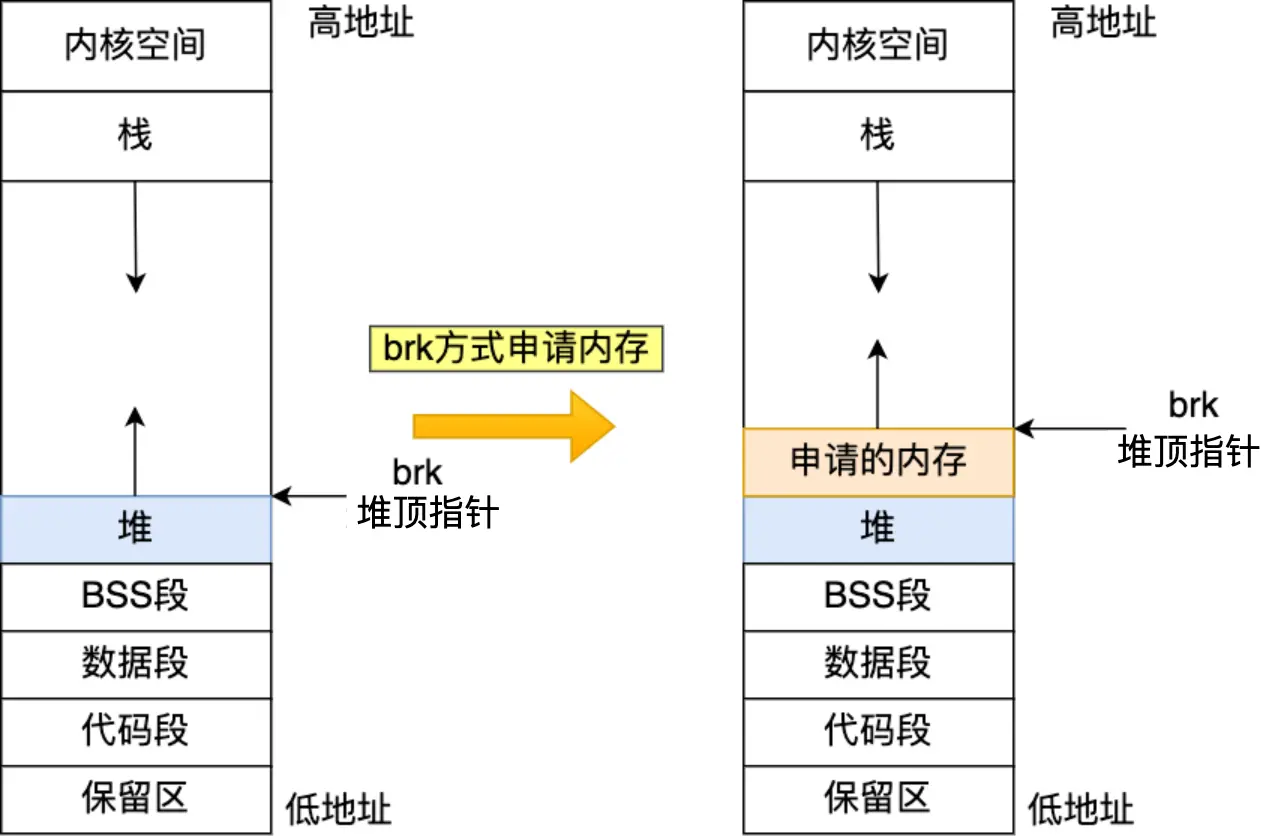
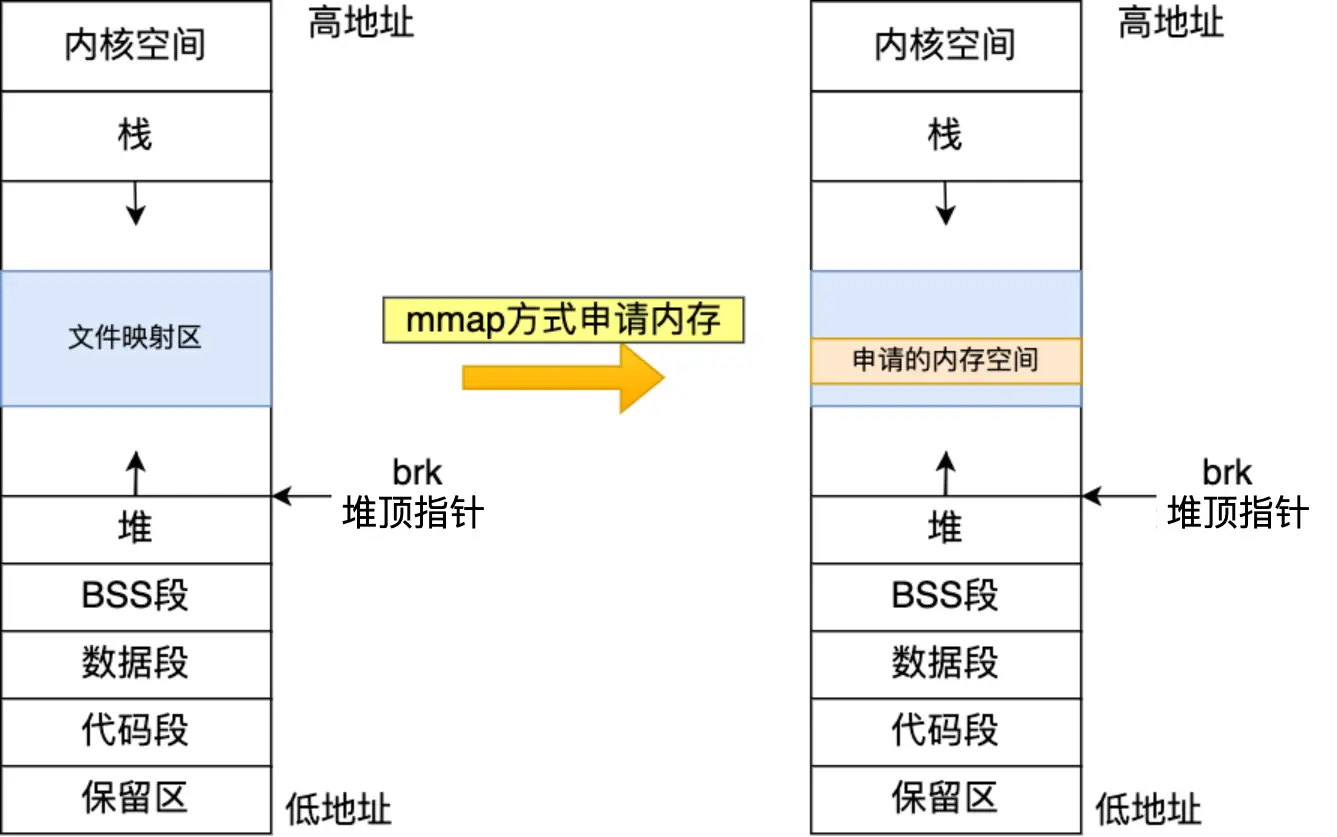
malloc 分配的是物理内存吗?
不是
malloc 分配的是虚拟内存,调用 malloc,不会真正的分配物理内存
当进程 第一次 使用 malloc 分配的内存时,会触发缺页中断,因为对应的页表项还没有物理内存块的分配
malloc(1) 会分配多少内存?
这个取决于 malloc 的具体实现,但绝对不是 1 个字节
malloc 在分配内存时,会 预分配 部分内存,以减少潜在的系统调用次数
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
void *addr = malloc(1);
printf("pid: %d, addr: %p\n", getpid(), addr);
getchar();
}
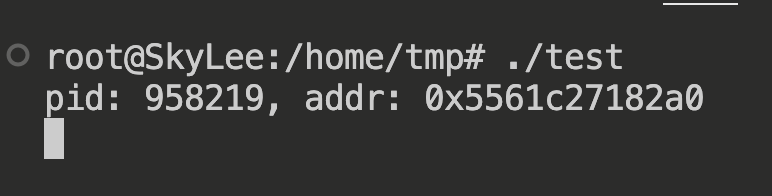

可以看到,由于拟分配内存大小为 1,调用的是 brk(有 heap 标识),并且实际分配的虚拟内存大小为 132K
free 释放内存,会立即将内存还给 OS 吗?
这个要分情况
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
void *addr = malloc(1);
printf("pid: %d, addr: %p\n", getpid(), addr);
printf("about to free...\n");
getchar();
free(addr);
printf("freed.");
getchar();
}
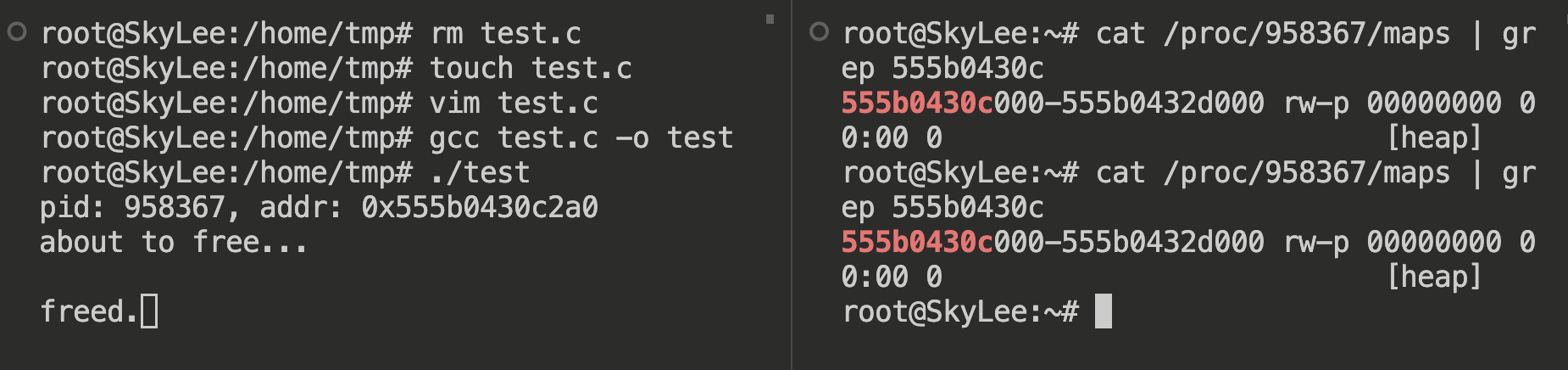
可以看到,即使调用了 free,也没有真正释放
再来看一个示例:
int main(void)
{
void *addr = malloc(1024 * 1024);
// ... 省略
}
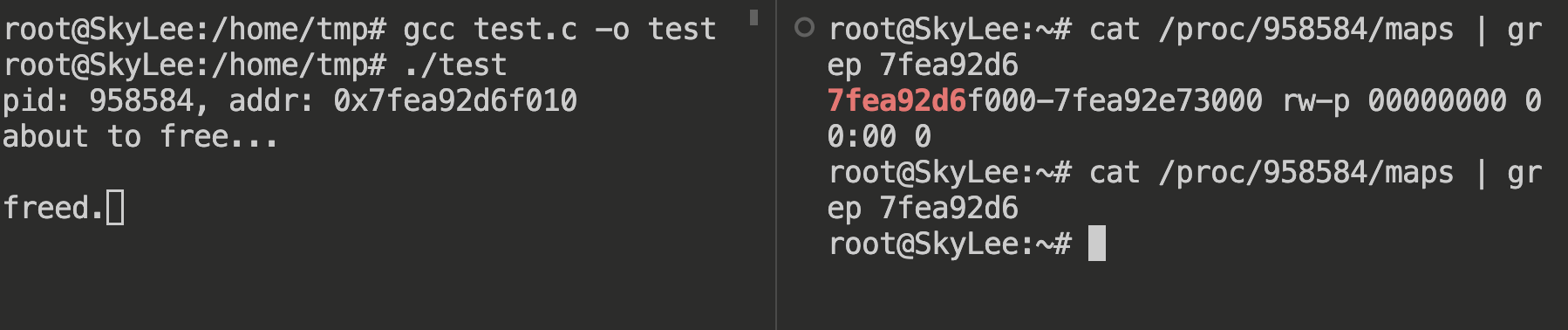
可以发现,这次没有 [heap] 标识,说明调用的是 mmap,free 以后,内存也立即释放了
因此,结论如下:
- malloc 通过 brk() 方式申请的内存,free 释放内存的时候,并不会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用;
- malloc 通过 mmap() 方式申请的内存,free 释放内存的时候,会把内存归还给操作系统,内存得到真正的释放。
为什么 brk 释放内存,不会直接归还内存给操作系统,而 mmap 会?
brk 申请/释放内存的方式是移动堆顶指针,不支持非连续内存释放,要想归还内存给 OS,不太好操作
只有在堆的 “break” 指针下方没有任何分配的内存块时,brk 才能实际减少数据段的大小并将内存还给操作系统。
而 mmap 是在文件映射区直接映射一块空间,不需要的话,直接解除映射就行
为什么不全部调用 mmap 申请内存?
在上面的示例我们知道,调用 mmap,free 会立即释放内存
如果我们的程序还要再次调用 malloc,就势必 会再一次调用 mmap,多次的系统调用 会影响性能
为什么不全部调用 brk 申请内存?
我们知道,brk 存在预分配,即分配的内存比要求的要多一些(冗余),下次再调用 malloc,就直接从预分配的取就行,减少系统调用
但是,free brk 分配的内存,并不会真正的将内存还给 OS,存在潜在的 内存泄漏,而且这个内存泄漏无法被 valgrind 检测
因此,malloc 在:
- 分配的内存小于 128K,调用 brk
- 分配的内存大于 128K,调用 mmap
free 仅传入一个起始地址,怎么知道该释放多大内存?

可以发现:malloc 返回给用户态的内存起始地址比进程的堆空间起始地址多了 16 字节
而这 16 字节就是用于存储这个 memory block 的大小的
因此,free 仅传入一个起始地址,就可以通过读取起始地址前 16 个字节的数据,获取要释放的 memory block 的大小
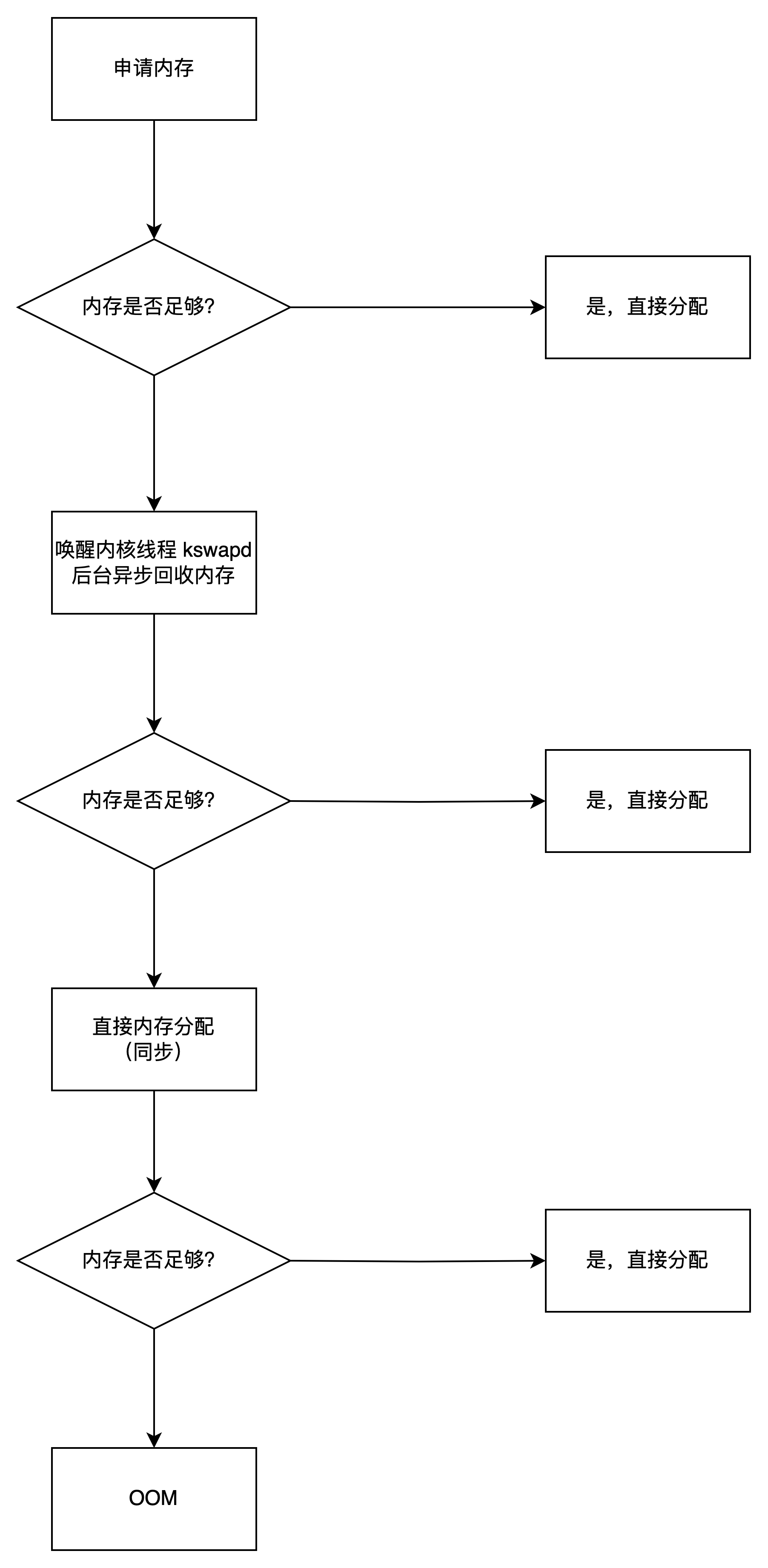
内存满了,会发生什么?
内存分配的过程
哪些内存可以回收?
- 文件页
- 干净页:没有修改过的
- 脏页:修改过,与磁盘内容不一致
- 匿名页:进程的堆栈区域,由于可能频繁使用,不能直接回收,由 swap 机制回收
回收内存带来的性能影响
有两种方式回收内存:
- 后台回收:唤醒 kswapd 内核线程,异步回收
- 直接回收:阻塞当前运行的进程,同步回收
对于文件页:
- 干净页的回收,直接释放内存即可,对性能影响不大
- 脏页的回收,需要将脏页写回磁盘,影响性能
对于匿名页,使用 swap 机制回收,将不常用的页换出到磁盘,也有大量磁盘 IO
可以发现,回收内存的过程,基本上都要涉及到将内存的数据写到磁盘
并且,这个过程会带来大量磁盘 IO,造成 OS 的响应时间变长,给人的感觉就是很卡
如何降低回收内存带来的性能影响?
- 调整回收偏好
- 调整后台回收的时间点
经过上面的分析,可以发现:
- 对于文件页的回收,由于干净页的存在,回收影响的性能相对较小
- 直接回收是同步的,会带来延迟,可以考虑提前进行后台回收
调整回收偏好
在 Linux 中,提供了 /proc/sys/vm/swappiness 选项,用于调整 swap 的偏好,值越小,越消极使用 swap
我们可以降低这个值,提高文件页的回收优先级:
# 已经是 0,无需修改
root@SkyLee:~# cat /proc/sys/vm/swappiness
0
尽早触发 kswapd 后台回收,避免直接回收带来的高延迟
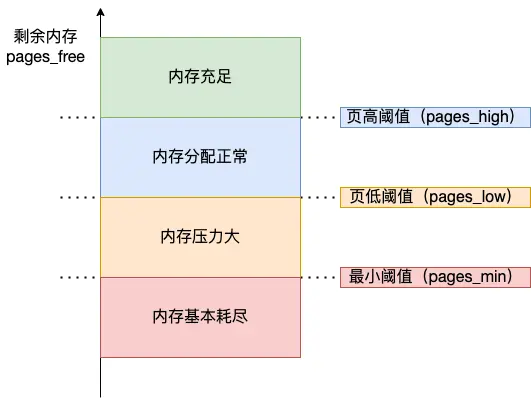
在 Linux 中,提供了 /proc/sys/vm/min_free_kbytes 选项,用于调整 最小阈值
最小阈值与页低阈值、页高阈值的关系:
pages_min = min_free_kbytes
pages_low = pages_min*5/4
pages_high = pages_min*3/2
当 pages_min < pages_free < pages_low,即内存压力大时,就会触发 kswapd 后台回收
因此,可以适当的调高 pages_low(也就是调节 min_free_kbytes),以提前触发后台回收
但是,调高 pages_min,意味着可能剩余较多内存时,就会触发直接回收,这在一定程度上浪费了内存,可能导致 OOM 的发生
因此对于内存使用量敏感的进程,可以延后后台回收的时间点,可以使用更多的内存
在调整 pages_min 时,要关注进程到底是关注延迟,还是内存使用量
NUMA 架构下的内存回收策略
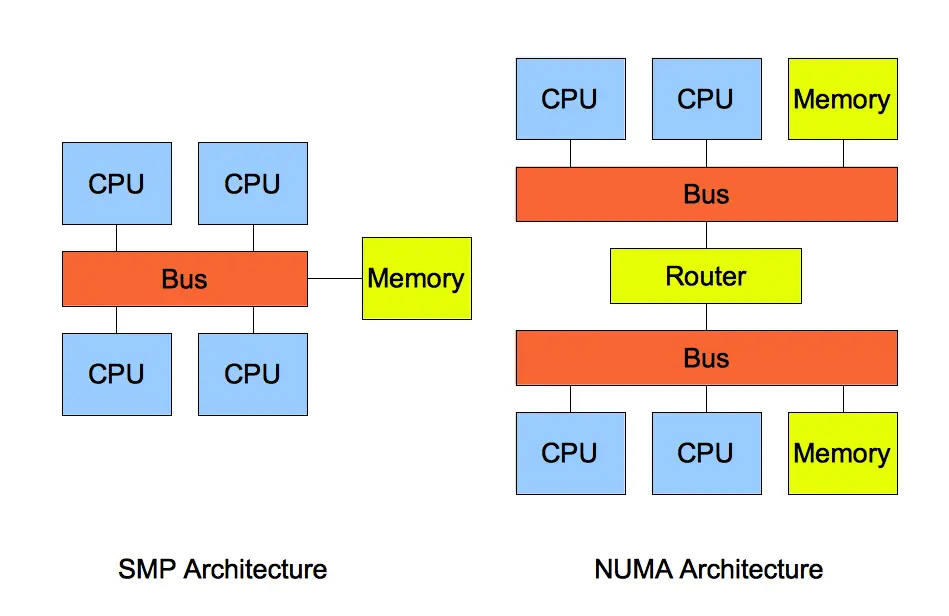
在 NUMA 架构下,每若干个 CPU 核心组成一个 node,每个 node 都有自己独立的内存,一个 node 也可以访问另一个 node 的内存,但是延迟肯定更高
在 NUMA 架构下,如果一个 node 发现内存不够,可以回收自己 node 的内存,也可以去寻找其它 node 有没有可用空间
Linux 提供了 /proc/sys/vm/zone_reclaim_mode 选项来控制:
- 0 (默认值):在回收本地内存之前,在其他 Node 寻找空闲内存;
- 1:只回收本地内存;
- 2:只回收本地内存,在本地回收内存时,可以将文件页中的脏页写回硬盘,以回收内存。
- 4:只回收本地内存,在本地回收内存时,可以用 swap 方式回收内存。
推荐使用 0,即使延迟高一些,但是比起回收的延迟,根本不算什么
如果在 Server 发现内存还比较充足,但是却频繁触发直接回收,可能就是 NUMA 架构下的内存回收策略没有设置正确
root@SkyLee:~# cat /proc/sys/vm/zone_reclaim_mode
0
如何避免一个进程被 OOM Killer 杀掉?
发生 OOM 后,OOM Killer 会为每个进程打分,分数最高的,将会被杀掉,直到剩余内存足够分配
打分机制:
- 进程已经使用的物理内存页面数。
- 每个进程的 OOM 校准值 oom_score_adj。它是可以通过
/proc/[pid]/oom_score_adj来配置的。我们可以在设置 -1000 到 1000 之间的任意一个数值,调整进程被 OOM Kill 的几率。
points = process_pages + oom_score_adj*totalpages/1000
想要避免被 OOM Killer 杀掉,可以调低 oom_score_adj,如果为 -1000,代表不会被杀掉
但是,对于我们自己的业务程序,不应该设置为 -1000,如果有内存泄漏,由无法被 OOM Killer 杀掉,OOM Killer 就只能被不断唤醒,并杀掉其它进程
在 4G 内存大小的 Server 上,申请 8G 内存会怎么样?
OS 虚拟内存的大小
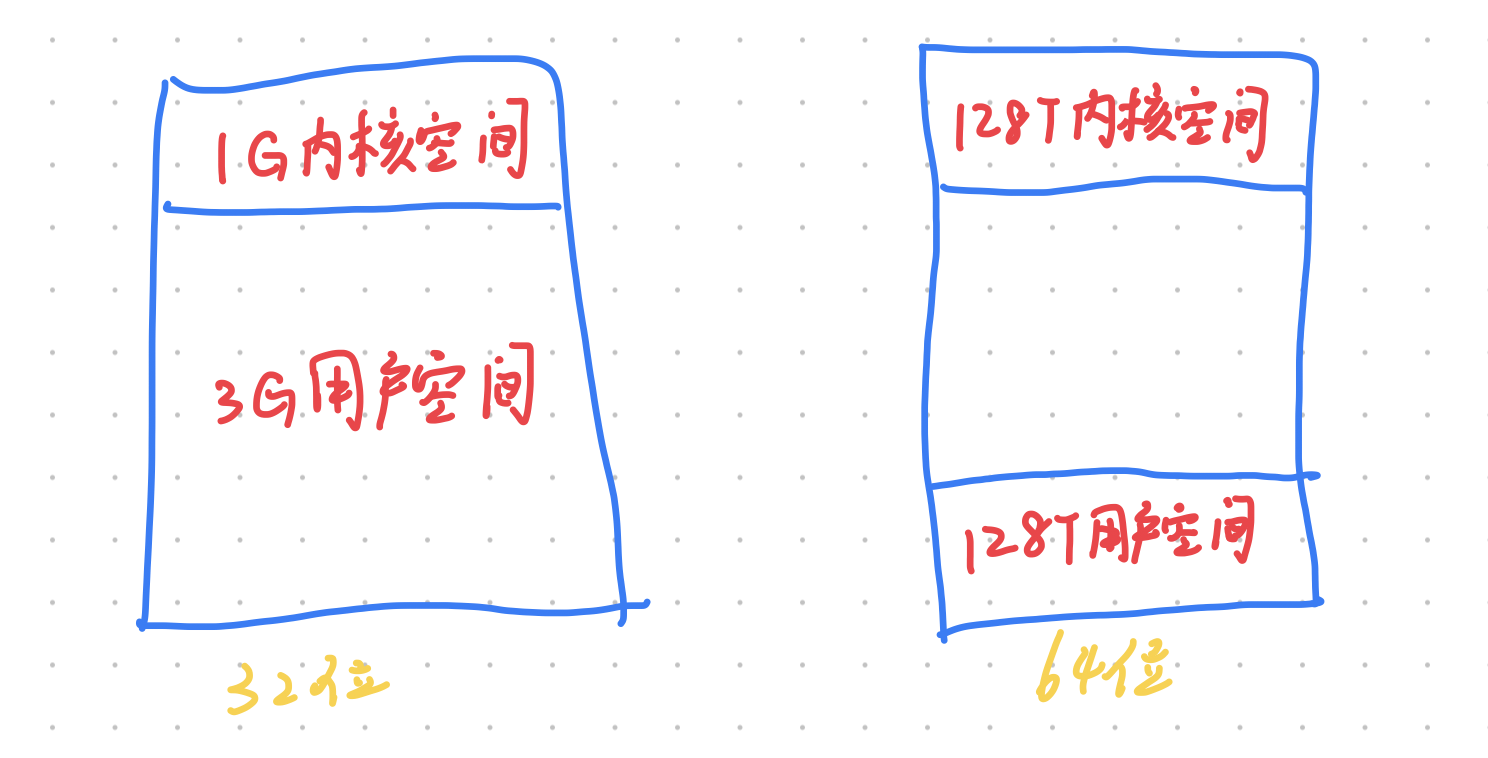
- 对于 32 位的 OS 来说,虚拟内存最大大小为 3G
- 对于 64 位的 OS 来说,虚拟内存最大大小为 128T
Swap 机制
Swap 机制可以:
- 将不常用的页 换出 到磁盘
- 将磁盘的页 换入 到内存供进程使用
触发条件?
- 内存闲置:进程在启动阶段申请的内存,大部分都不会被使用,可以将那些仅用过一次的页面换出到磁盘
- 内存不足:如果进程使用的内存超过了物理内存的限制,就会 swap 一部分相对不常用的页到磁盘
换入换出的是什么类型的内存?
换入换出的是 匿名页
在 4G 内存大小的 Server 上,申请 8G 内存会怎么样?
32 位的 OS 由于理论只能申请 3G 的内存,因此,申请 8G 会失败
64 位的 OS 理论可以申请 128T 的内存
在我的电脑(16G 的物理内存)下,进程申请 128T 内存是可以成功的:
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
const int SIZE = 1024 * 1024 * 1024;
const int N = 128 * 1024;
char* buff[N];
for (size_t i = 0; i < N; i++)
{
buff[i] = malloc(SIZE);
printf("申请了 %lu G 内存\n", i + 1);
}
getchar();
}
申请了以后,能使用多少?
如果没有开启 swap 机制,那使用量会受到物理内存大小的限制
如果开启了 swap 机制,由于可以将不常用的页换出到磁盘,因此,实际可使用的内存会大于物理内存的大小
但是,如果使用的内存太多,swap 就会很频繁,带来很大的磁盘 IO
有了 swap,是不是意味着进程使用的内存没有上限?
当然不是,在开启了 swap 机制的 64 位 OS 中,一个进程的最大内存使用量通常取决于 RAM 大小,swap 分区大小,以及操作系统的虚拟内存管理策略。
因此,“在 4G 内存大小的 Server 上,申请 8G 内存会怎么样” 这个问题就可以解答了:
- 对于 32 位的 OS,无法申请,进程内存最大使用量理论上限为 3G
- 对于 64 位的 OS,可以申请 8G 内存,但是如果要完整使用 8G 内存,需要开启 swap 机制
如何在 Linux 上启用 swap
在 Linux 系统中启用 swap(交换空间),可以分为几个步骤:创建 swap 文件或分区、启用 swap、并设置开机自动挂载。以下是具体的步骤:
创建 Swap 文件
-
创建一个 Swap 文件: 使用
fallocate或dd命令创建一个用于交换的文件。例如,创建一个 4GB 的 swap 文件:sudo fallocate -l 4G /swapfile如果你的系统中没有
fallocate命令,可以使用dd命令来创建:sudo dd if=/dev/zero of=/swapfile bs=1024 count=4096k其中
bs是块大小,count是块的数量,两者相乘等于 swap 文件大小。 -
设置 Swap 文件权限: 出于安全考虑,Swap 文件的权限应该被设置为仅 root 用户可读写。
sudo chmod 600 /swapfile -
格式化文件为 Swap 格式: 使用
mkswap命令将文件设置为 swap 使用:sudo mkswap /swapfile
启用 Swap 文件
执行以下命令来启用 swap 文件:
sudo swapon /swapfile
执行这个命令之后,系统就会开始使用/swapfile文件作为交换空间。
设置开机自动挂载 Swap 文件
为了在系统启动时自动启用 swap 文件,需要将它添加到/etc/fstab文件中。
-
编辑 fstab 文件:
sudo nano /etc/fstab使用你喜欢的文本编辑器打开
/etc/fstab文件。 -
添加 swap 条目:
在文件的最后添加下面的行:
/swapfile none swap sw 0 0保存并关闭文件。
-
使配置生效:
通常来说,再次启动时修改将生效,或者您可以用
mount -a命令来使改动立即生效:sudo mount -a
完成这些步骤后,swap 文件应该会在每次启动时自动启用。可以通过执行free -m或者swapon -s命令来检查 swap 是否已经被系统正确识别和使用。
有了 swap 文件,还需要设置 OS 使用 swap 的倾向,前面提到可以修改 /proc/sys/vm/swappiness 临时 修改使用 swap 文件的倾向
swappiness 的范围为 0 ~ 100,越大,越倾向使用 swap
为了避免设置重启失效,需要修改 /etc/sysctl.conf,添加:
vm.swappiness = 30 # 使用 swap 的倾向
再执行:
sysctl -p
使设置生效
预读失效与缓存污染
什么是预读机制?
OS 在读取文件到内存时,通常会「预读」一部分到内存中,如果下一次要访问预读部分,就不需要再次读取磁盘,减少磁盘 IO
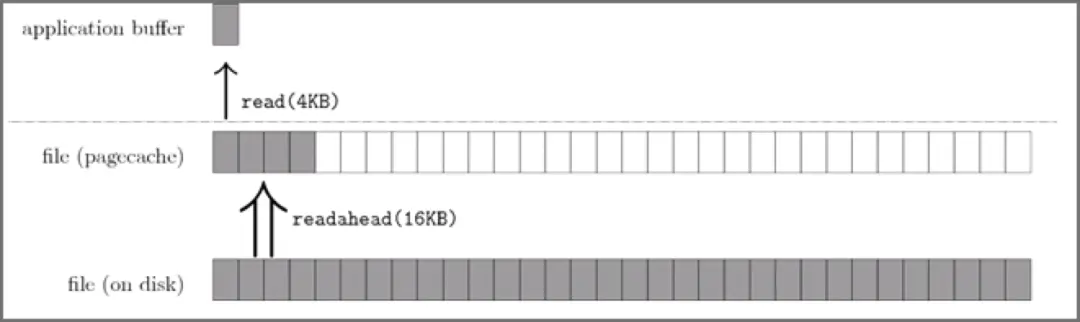
预读失效是什么?会导致什么后果?
如果预读的数据一直不访问,那么预读也就没有作用了
此外,如果使用传统的 LRU 算法,就会把「预读页」放到 LRU 链表头部,而当内存空间不够的时候,还需要把末尾的页淘汰掉。
而末尾淘汰的的页可能是热点数据,导致访问热点数据又要重新读磁盘,严重降低性能
如何避免预读失效带来的影响?
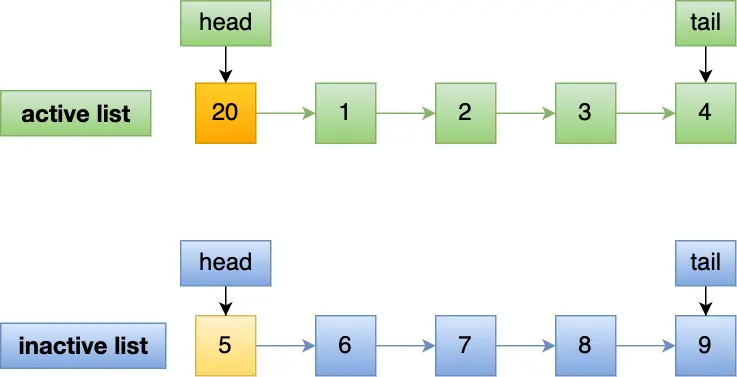
Linux 通过两个 LRU 链表来解决问题:
- active
- inactive
一开始预读的数据先放到 inactive,只有访问一次后,才提升到 active
这样即使预读的页一直不访问,也不会导致热点数据(在 active 中)淘汰
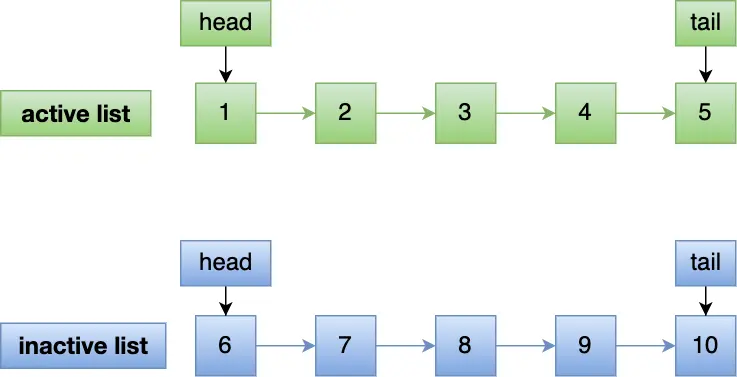
编号为 20 的页被预读:
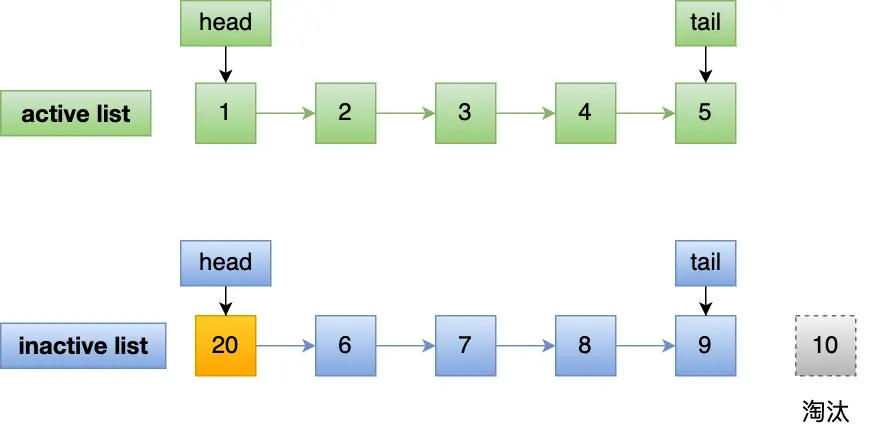
即使 20 页一直没有被读取,也不会影响 active,如果被读取,提升到 active,并且 active 的最后一页降级到 inactive 的头部:
什么是缓存污染?
如果采用 一开始预读的数据先放到 inactive,只有访问一次后,才提升到 active 的机制,会存在缓存污染的问题
举个例子,在批量读取一批数据(假设为 0 ~ 15)的过程:
- 读取 0,预读 1 ~ 15
- 读取 1,1 提升到 active
- 读取 2,2 提升到 active
- …
- 读取 15,15 提升到 active
如果之前 active 的 LRU 链表中的热点数据因为这次批量读取而淘汰,并且这一批数据 仅仅用到了一次(事实上,这是很常见的),那么热点数据的淘汰就显得性价比很低了
这就是缓存污染
缓存污染会导致什么后果?
缓存污染会导致热点数据可能被淘汰,导致大量磁盘 IO
如何避免缓存污染带来的影响?
问题出在:一开始预读的数据先放到 inactive,只有访问一次后,才提升到 active
如果读一次,还不足以提升到 active,不就解决了吗?
Linux 会在内存页被访问第二次的时候,才将页从 inactive list 升级到 active list 里
这样,在批量读取数据时候,如果这些大量数据只会被访问一次,那么它们就不会进入到活跃 LRU 链表,也就不会导致热点数据的淘汰
当然,InnoDB 自己也有应对预读失效和缓存污染的策略,可以看看这篇文章:InnoDB Buffer Pool
Linux 虚拟内存管理
进程虚拟内存空间管理
OS 对进程虚拟内存的管理,主要是通过 task_struct 中的 mm_struct
当我们 fork 一个子进程,OS 会 拷贝 父进程的 mm_struct 给子进程,也就是说,父子进程的 mm_struct 是独立的
这个过程是「写时拷贝」
当一个进程(父进程)试图复制(fork)一个新的进程(子进程)时,按理说,这两个进程应有各自独立的内存空间,互不影响。然而在实际情况下,操作系统并 不会立即为子进程复制 一份父进程的内存数据,而是采用了一种叫做写时拷贝的策略:
- 初始时,子进程会共享父进程内存中所有尚未修改的页面,而不是复制它们。在此期间,这些内存页面 被标记为只读,以防止修改。
- 当父进程或子进程想对这些共享页面进行写操作时,发生写保护中断,操作系统调用写保护中断处理函数,会先制作一个新的页面副本,新的写操作会定向到这个副本上,而不影响原来的页面。这就是所谓的写时拷贝。
这种策略的优点是如果复制的内容没有被修改,则可以节省大量的内存和 CPU 时间。缺点是如果数据经常被修改,每次修改都要复制,反而会增加开销。因此这种方法适用于读多写少的场合。
而调用 vfork 或者 clone 出的子进程,OS 会递增父进程 mm_struct 的引用计数,子进程与父进程共享虚拟内存空间
事实上, pthread_create 内部就是调用的 clone 创建的「线程」
进程与线程的本质区别?
是否共享内存空间,是进程与线程的本质区别,Linux 并不区分进程与线程,线程对于内核来说,不过是一个共享特定资源的进程而已
内核线程的 mm_struct
内核线程的 task_struct 包含的 mm_struct 为 NULL,因为 内核线程间共享内核虚拟内存空间 ,内核线程之间的调度不涉及内存上下文切换
内核如何划分用户空间与内核空间?
mm_struct 中有一个 task_size,记录了用户进程的合法虚拟内存地址空间大小
在 32 位 OS 下,task_size 的大小为 3G
而 64 位 OS,这个值为 128T(与 PAGE_SIZE 有关)
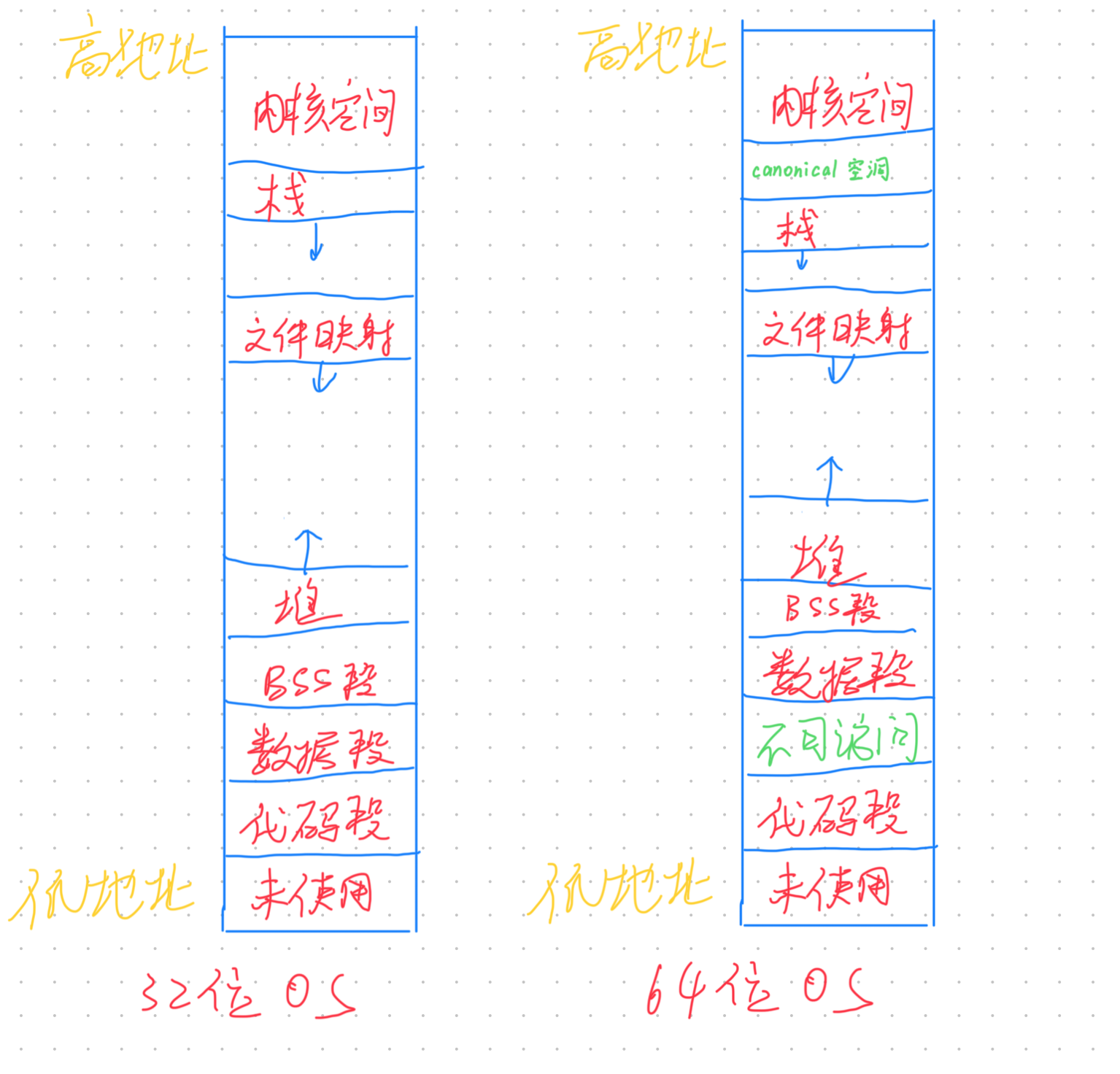
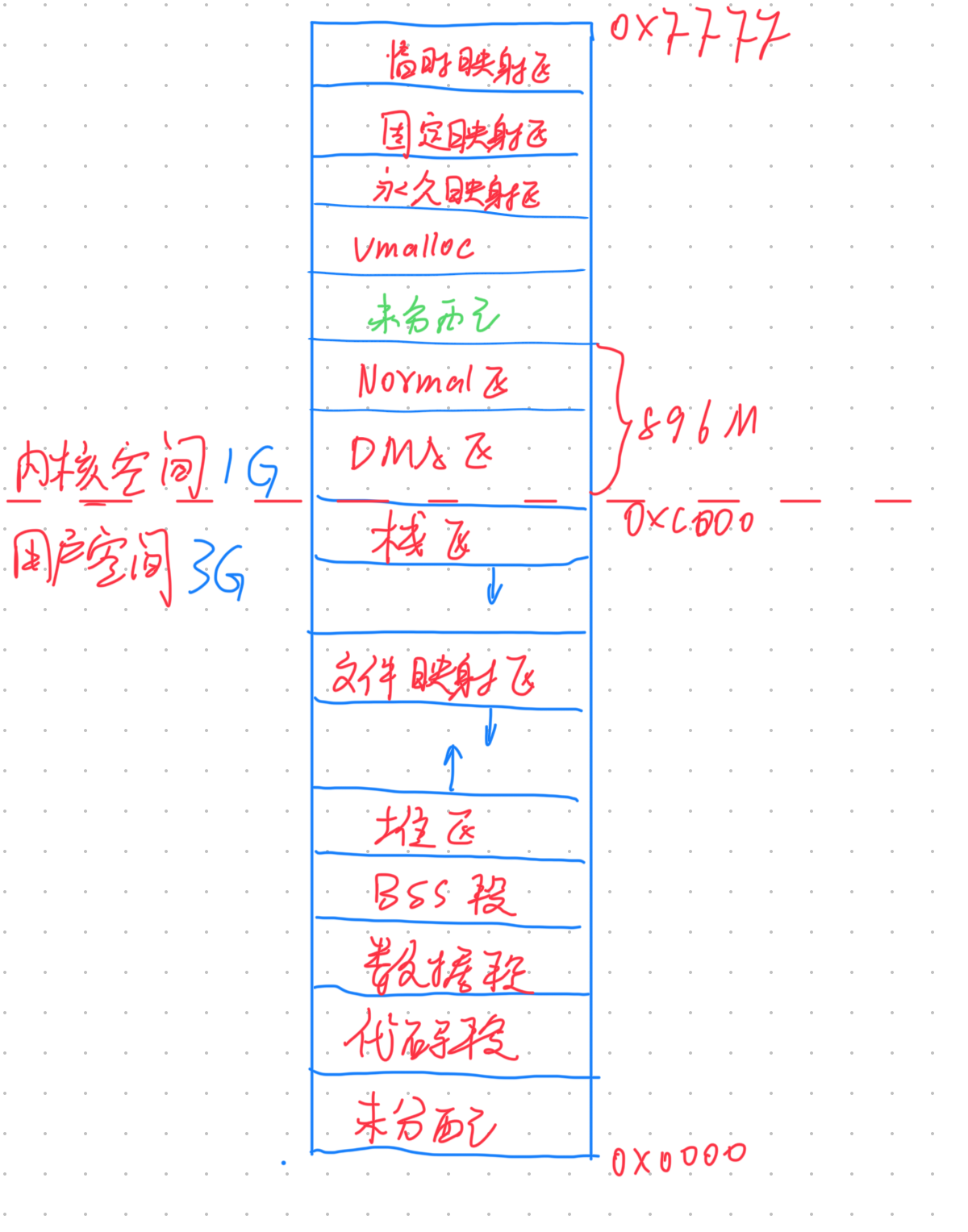
进程虚拟空间的布局
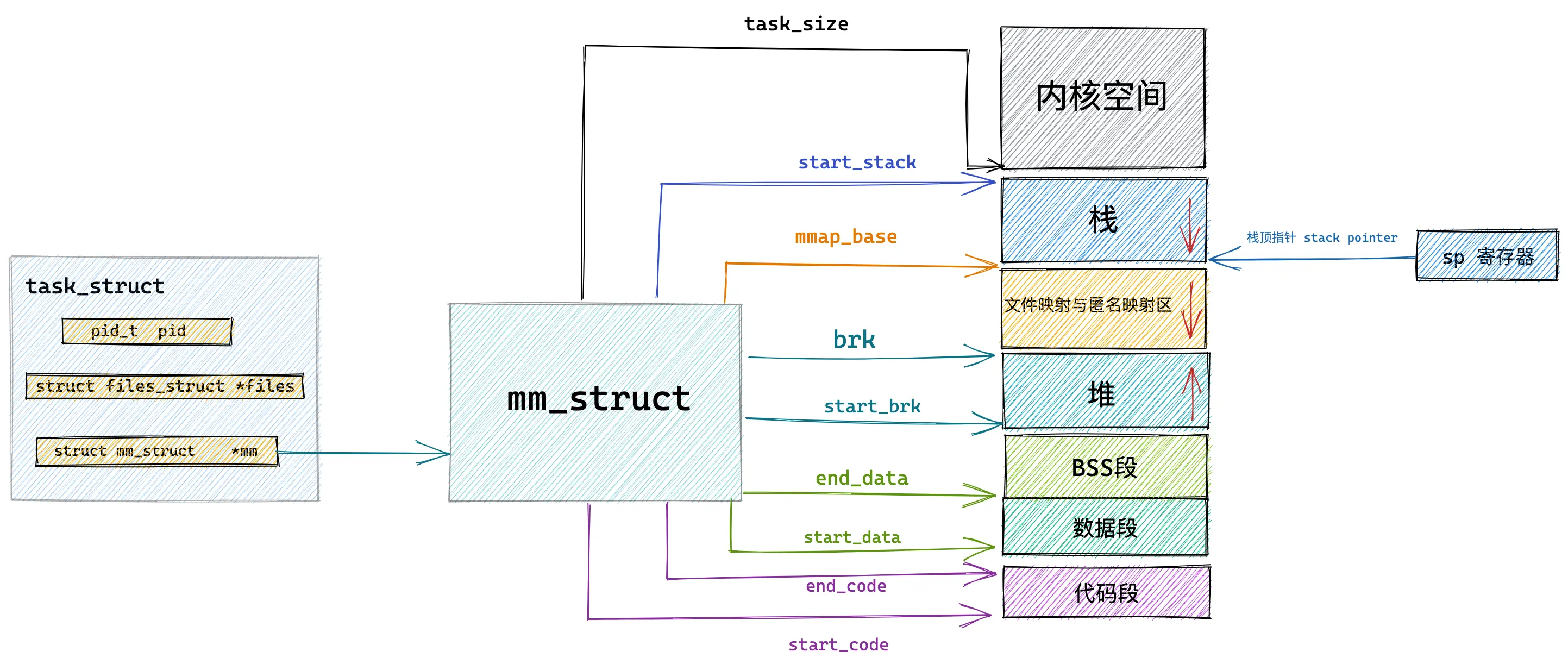
mm_struct 的定义如下:
struct mm_struct {
unsigned long task_size; /* 用户进程的合法虚拟内存地址空间大小,超过这个范围的地址用户进程无法访问 */
unsigned long start_code, end_code; /* 代码段 在虚拟内存中的起始和结束地址 */
unsigned long start_data, end_data; /* 数据段 在虚拟内存中的起始和结束地址 */
unsigned long start_brk, brk; /* 堆 在虚拟内存中的起始地址和当前结束地址(堆可以动态扩展和收缩) */
unsigned long start_stack; /* 栈 在虚拟内存中的起始地址 */
unsigned long arg_start, arg_end; /* 程序启动参数在虚拟内存中的范围 */
unsigned long env_start, env_end;/* 程序环境变量在虚拟内存中的范围 */
unsigned long mmap_base; /* mmap区域的基地址 */
unsigned long total_vm; /* 总映射内存页数 */
unsigned long locked_vm; /* 被锁定不能换出到磁盘的内存页总数 */
unsigned long pinned_vm; /* 既不能换出到磁盘,也不能移动的内存页总数 */
unsigned long data_vm; /* 数据段中映射的内存页数目 */
unsigned long exec_vm; /* 代码段中存放可执行文件的内存页数目 */
unsigned long stack_vm; /* 栈中所映射的内存页数目 */
...省略...
struct vm_area_struct *mmap; /* VMA 链表 */
}
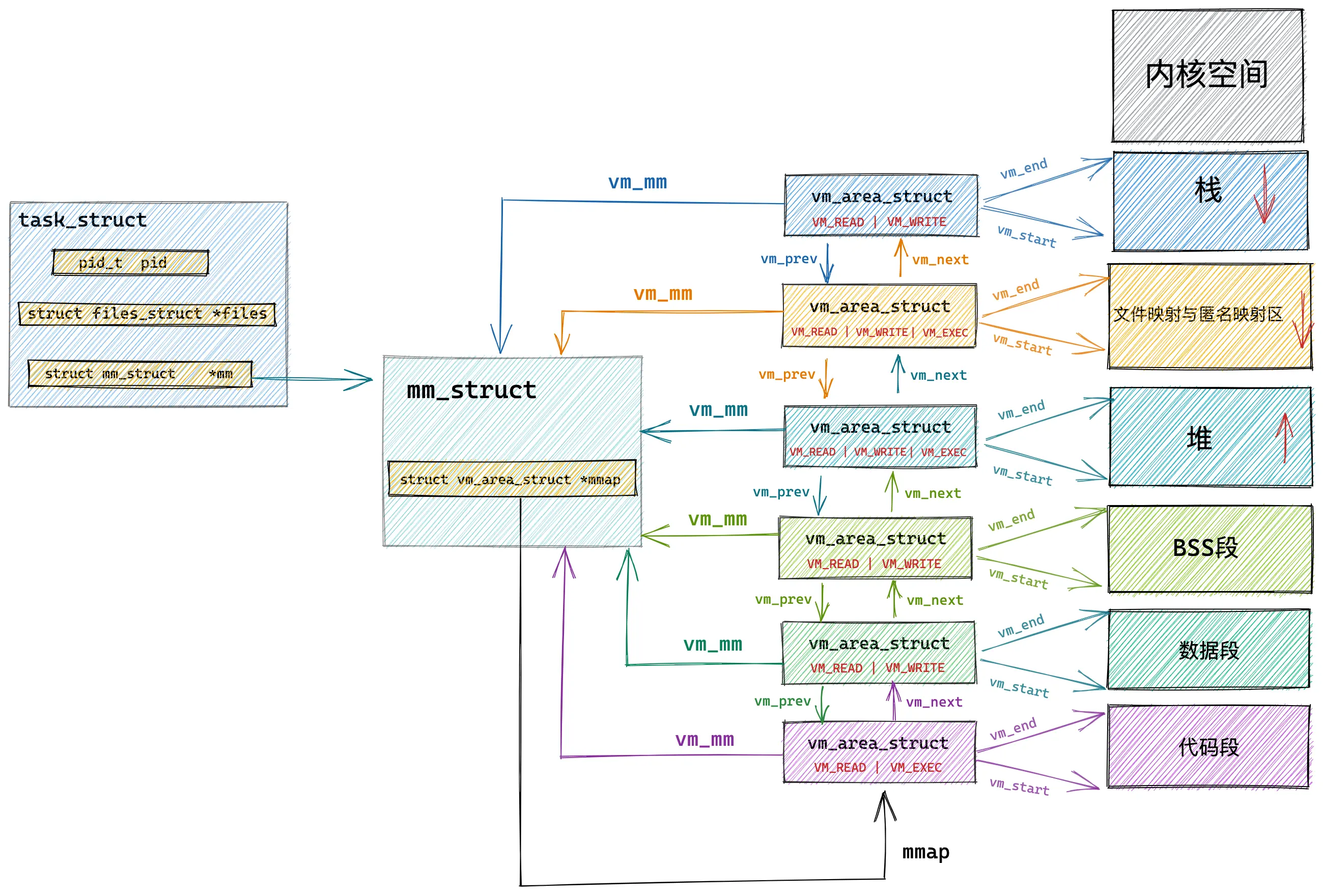
而具体到代码段、数据段、BSS 段… 的管理,Linux 引入了一个结构体 vm_area_struct,简称 VMA,来表示
struct vm_area_struct {
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
struct list_head anon_vma_chain;
struct mm_struct *vm_mm; /* The address space we belong to. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/*
* Access permissions of this VMA.
*/
pgprot_t vm_page_prot;
unsigned long vm_flags;
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
struct file * vm_file; /* File we map to (can be NULL). */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
void * vm_private_data; /* was vm_pte (shared mem) */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
}
许多 VMA 连在一起,组成一个双向链表,在 mm_struct 中,有一个 mmap 变量,记录了 VMA 链表的起始地址
每个 VMA 的 vm_mm 变量记录了所属 mm_struct 的地址
进程访问一个虚拟内存地址,发生了什么?
虽然 mm_struct 数据结构保存了跟进程地址空间相关的信息,但实际上将虚拟地址转换成物理地址的过程(地址翻译)是由内核配合硬件(具体来说就是内存管理单元,MMU)完成的。
- 首先,操作系统内核会检查这个地址是否在进程的地址空间——也就是在 mm_struct 中定义的范围内——如果不在,那么就会引发一个段错误(segmentation fault)。
- 如果这个地址在有效的地址范围内,那么 MMU 就会接管这个过程。MMU 使用页表(页表的位置和结构由 mm_struct 定义)来将虚拟地址翻译成物理地址。
- MMU 首先在 TLB(快表)中查找这个虚拟地址对应的物理地址。如果在 TLB 中找到了对应条目,那么转换就完成了。
- 如果在 TLB 中找不到对应的转换条目,那么 MMU 就会在实际的页表中查找。如果在页表中找到了,那么物理地址就被确定了,同时,这个信息会被添加到 TLB 中以便下次快速查找。如果在页表中也找不到,那么就会发生缺页错误(page fault),这时操作系统会接管,可能会从磁盘中加载所需要的页面到内存中。
程序编译后的二进制文件如何映射到虚拟内存空间中?
代码编译过后,会生成一个 ELF 格式的二进制文件
这个文件内部也分为若干个段
当我们运行这个程序时,内核实际上做了:
- 创建进程,并分配一块虚拟内存空间
- 解析 ELF 文件
- 将代码段、数据段…映射到正确的位置
- 运行程序
而映射这个过程是通过 load_elf_binary 这个函数实现的
static int load_elf_binary(struct linux_binprm *bprm)
{
...... 省略 ........
// 设置虚拟内存空间中的内存映射区域起始地址 mmap_base
setup_new_exec(bprm);
...... 省略 ........
// 创建并初始化栈对应的 vm_area_struct 结构。
// 设置 mm->start_stack 就是栈的起始地址也就是栈底,并将 mm->arg_start 是指向栈底的。
retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
...... 省略 ........
// 将二进制文件中的代码部分映射到虚拟内存空间中
error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
elf_prot, elf_flags, total_size);
...... 省略 ........
// 创建并初始化堆对应的的 vm_area_struct 结构
// 设置 current->mm->start_brk = current->mm->brk,设置堆的起始地址 start_brk,结束地址 brk。 起初两者相等表示堆是空的
retval = set_brk(elf_bss, elf_brk, bss_prot);
...... 省略 ........
// 将进程依赖的动态链接库 .so 文件映射到虚拟内存空间中的内存映射区域
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_map_addr,
load_bias, interp_elf_phdata);
...... 省略 ........
// 初始化内存描述符 mm_struct
current->mm->end_code = end_code;
current->mm->start_code = start_code;
current->mm->start_data = start_data;
current->mm->end_data = end_data;
current->mm->start_stack = bprm->p;
...... 省略 ........
}
内核虚拟内存空间管理
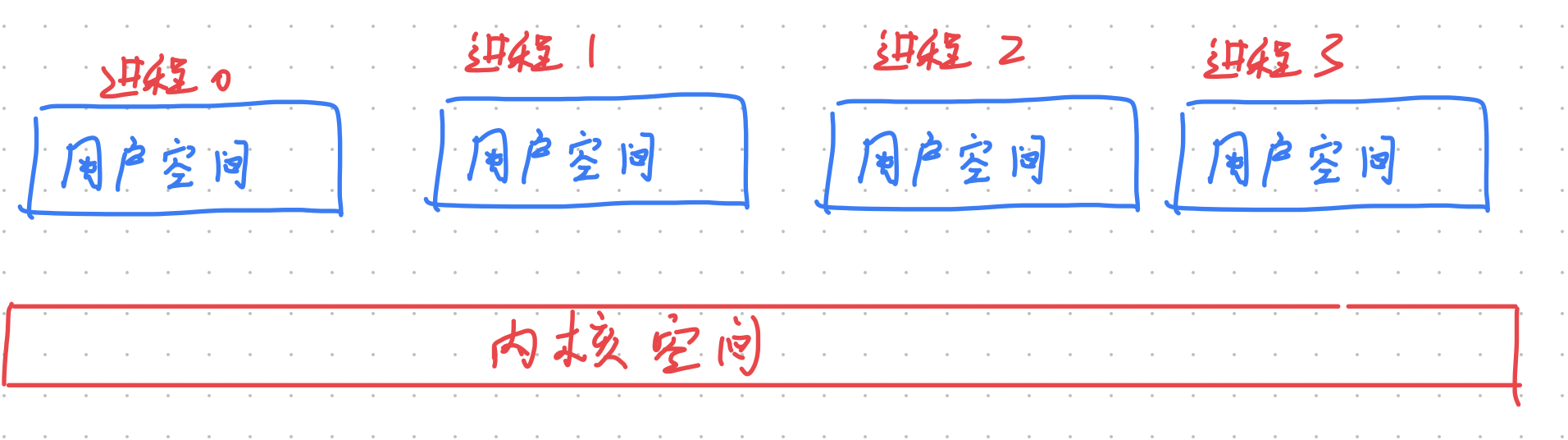
用户空间,每个进程的内存空间是相互隔离的,那么内核空间呢?
事实上,内核线程之间 共享 内核虚拟内存空间
32 位 OS 内核虚拟内存空间布局
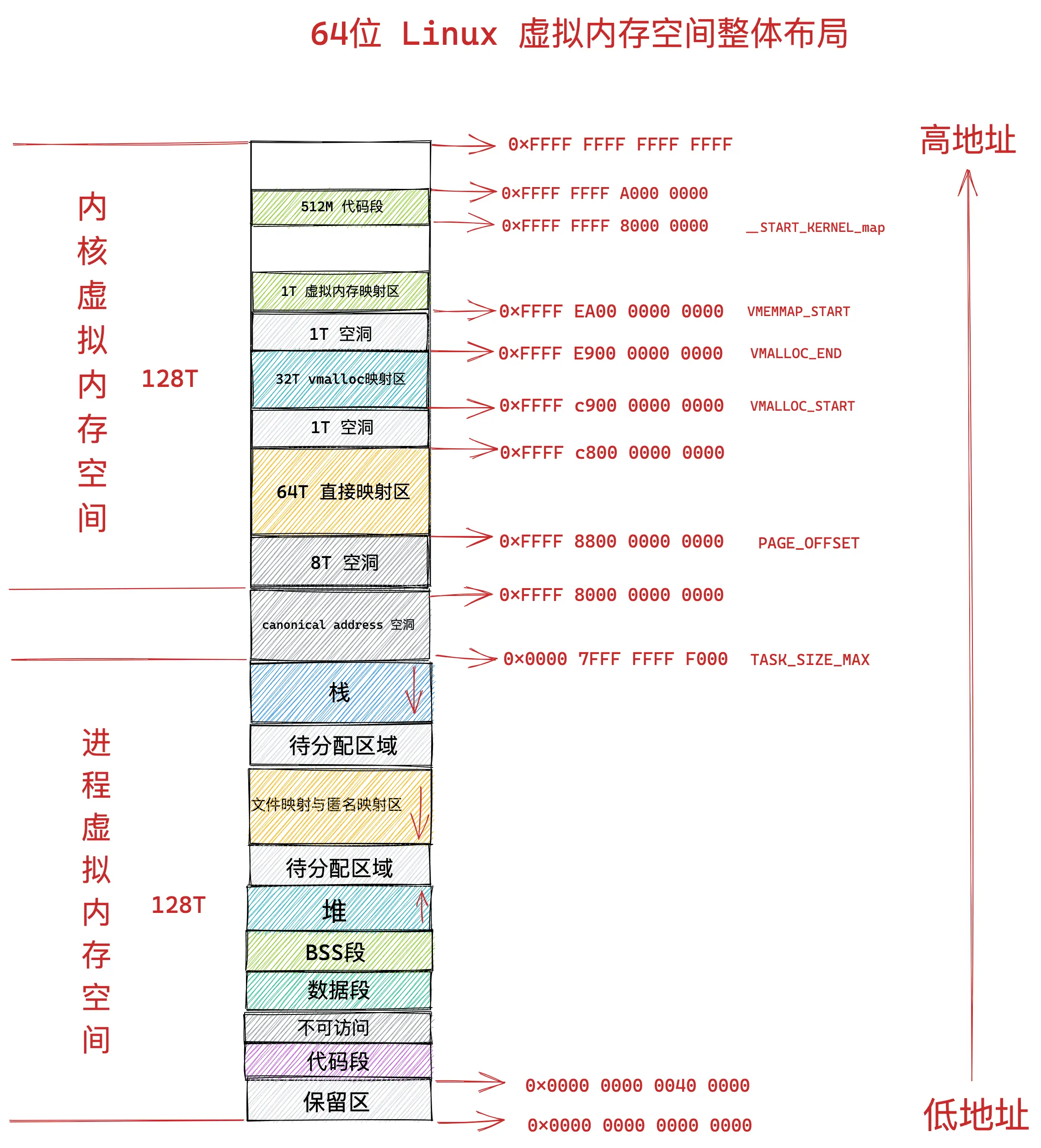
直接映射区
在内核空间的低地址处,有一块直接映射区,大小为 896M,这一部分,虚拟内存与物理内存是一对一的映射关系
直接映射区映射的起始地址为物理内存的低地址处(0x00)
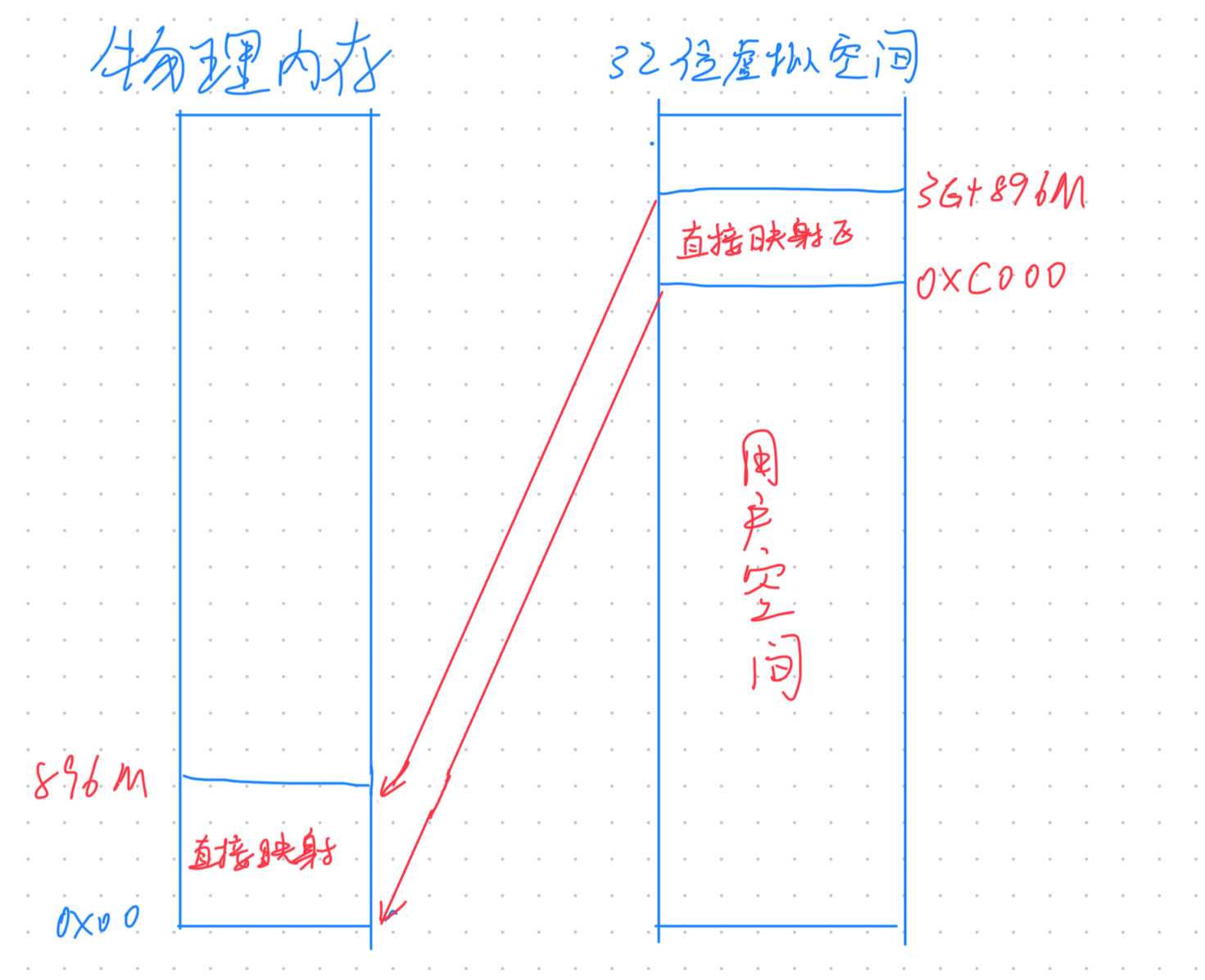
在 X86 体系下,由于 DMA 只能对内存的前 16M 寻址,因此,直接映射区还有一块区域用于 DMA
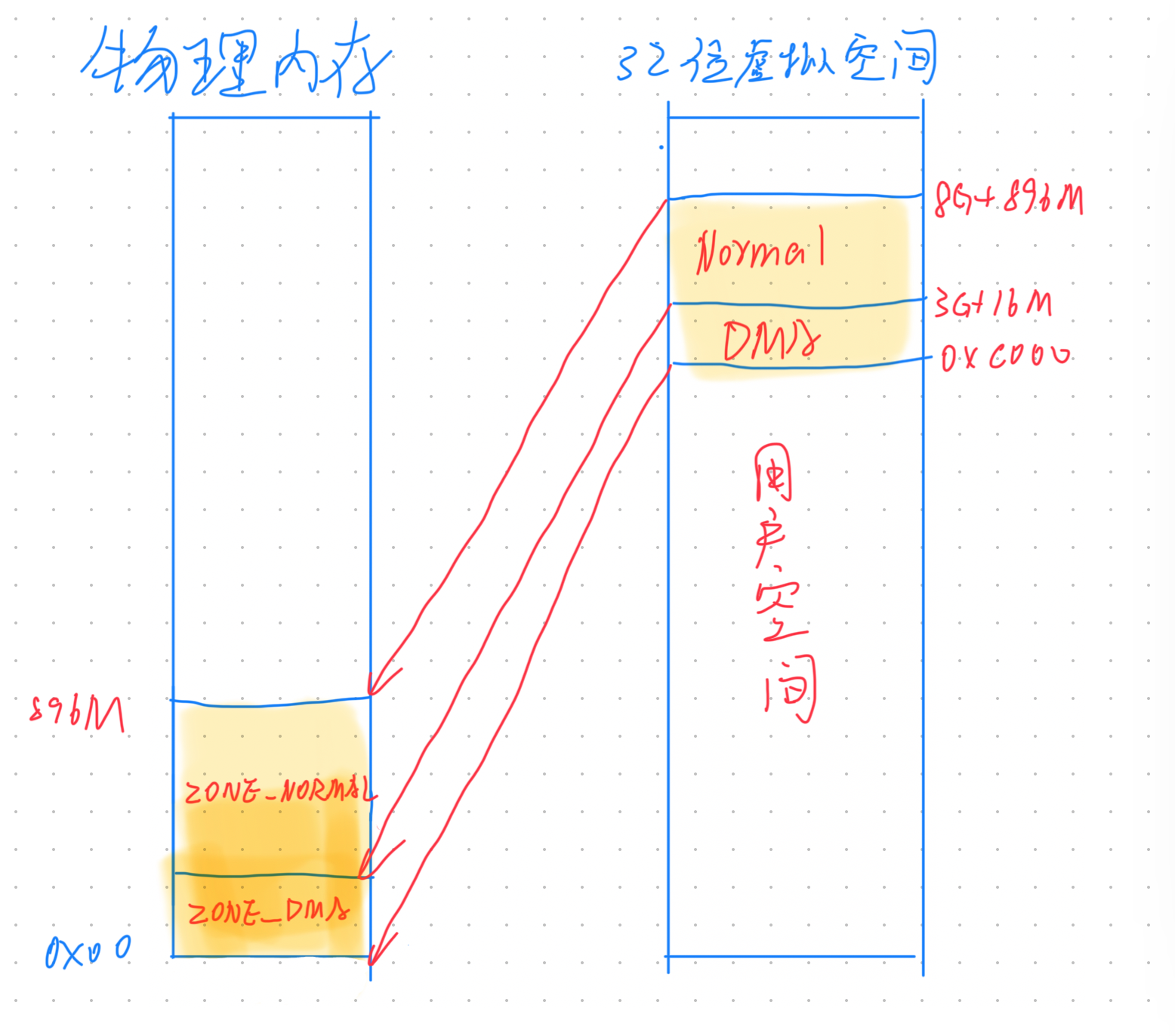
虽然直接映射区的虚拟内存与物理内存是一对一的映射,但还是会为这块区域创建页表
ZONE_HIGHMEM 高端内存
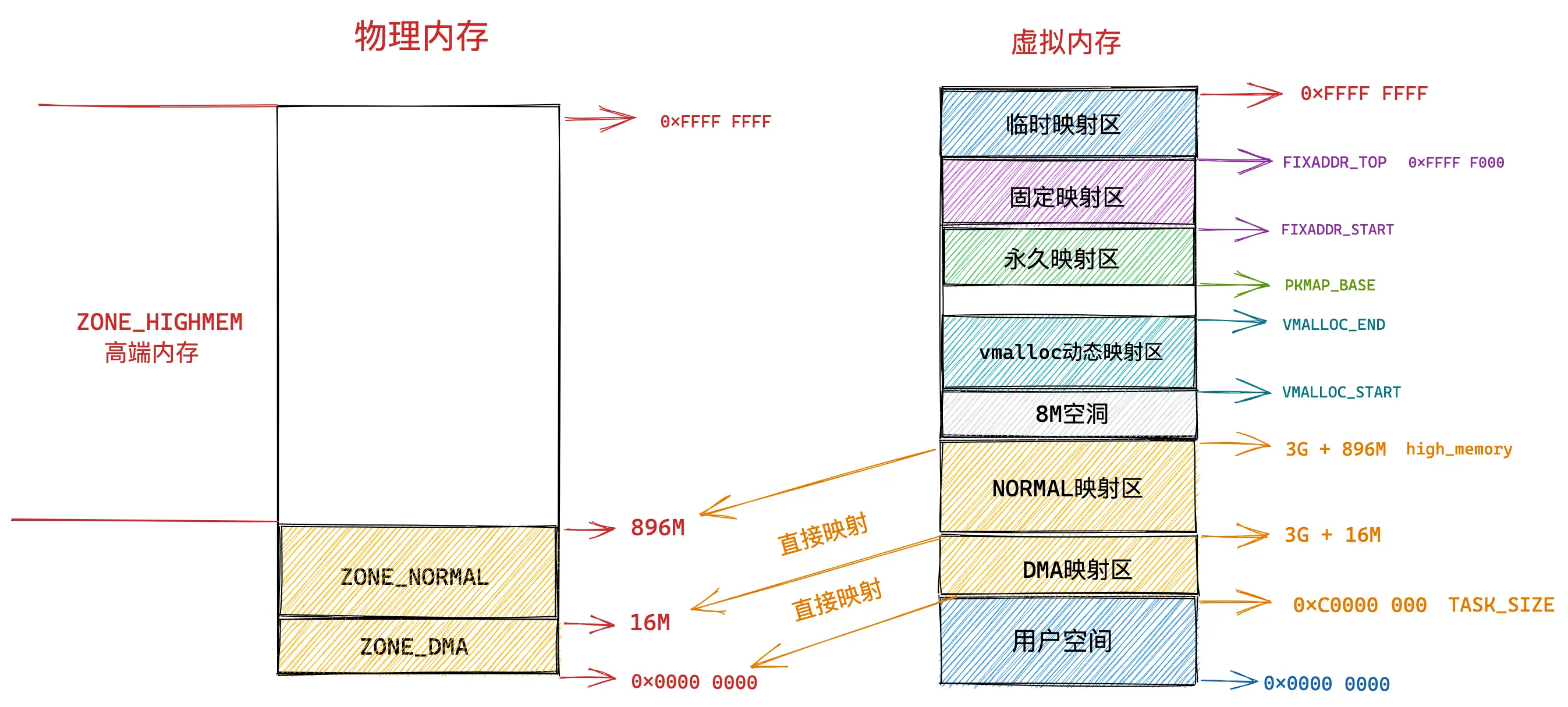
这里讲一下动态映射区
动态映射区使用 vmalloc 进行内存分配,vmalloc 分配的 虚拟内存是连续的,但 物理内存不是连续的,因此,性能会比直接映射区的性能差一些
整体布局
64 位 OS 内核虚拟内存空间布局
32 位 OS 的内核空间只有 1G,太小了,所以需要精细的控制
而 64 位 OS 的内核空间足足有 128T,很大,就不需要那么细粒度的控制