本文讨论的都是 Ext 系列的文件系统
基本组成
Linux 的每个文件都有两个基本结构:
- 索引节点 inode
- 目录项 dentry
inode 记录了一个文件的元数据,包括:文件类型、权限、所有者和组、大小、时间戳、链接数、数据块指针,可以使用 stat 查看一个文件的元数据:
root@SkyLee:~# stat snap/
File: snap/
Size: 4096 Blocks: 8 IO Block: 4096 directory
Device: fc03h/64515d Inode: 785828 Links: 3
Access: (0700/drwx------) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2023-09-07 17:19:11.646706615 +0800
Modify: 2023-09-07 17:03:25.256000000 +0800
Change: 2023-09-07 17:03:25.256000000 +0800
Birth: 2023-09-07 17:03:25.256000000 +0800
目录项 dentry,可以简单的看成 <文件名,inode> 这样一个二元组,具体结构如下:
struct dentry {//目录项结构
struct inode *d_inode; /*相关的索引节点*/
struct dentry *d_parent; /*父目录的目录项对象*/
struct qstr d_name; /*目录项的名字*/
struct list_head d_subdirs; /*子目录*/
struct dentry_operations *d_op; /*目录项操作表*/
struct super_block *d_sb; /*文件超级块*/
...
};
一块硬盘格式化后,包含以下内容:
- 超级块:用于存储整个文件系统的基本信息
- 索引节点区:存储 inode
- 数据块区:存放文件的具体内容
超级块会 在文件系统挂载时读取到内存,而索引节点区会按需读取到内存进行缓存
虚拟文件系统
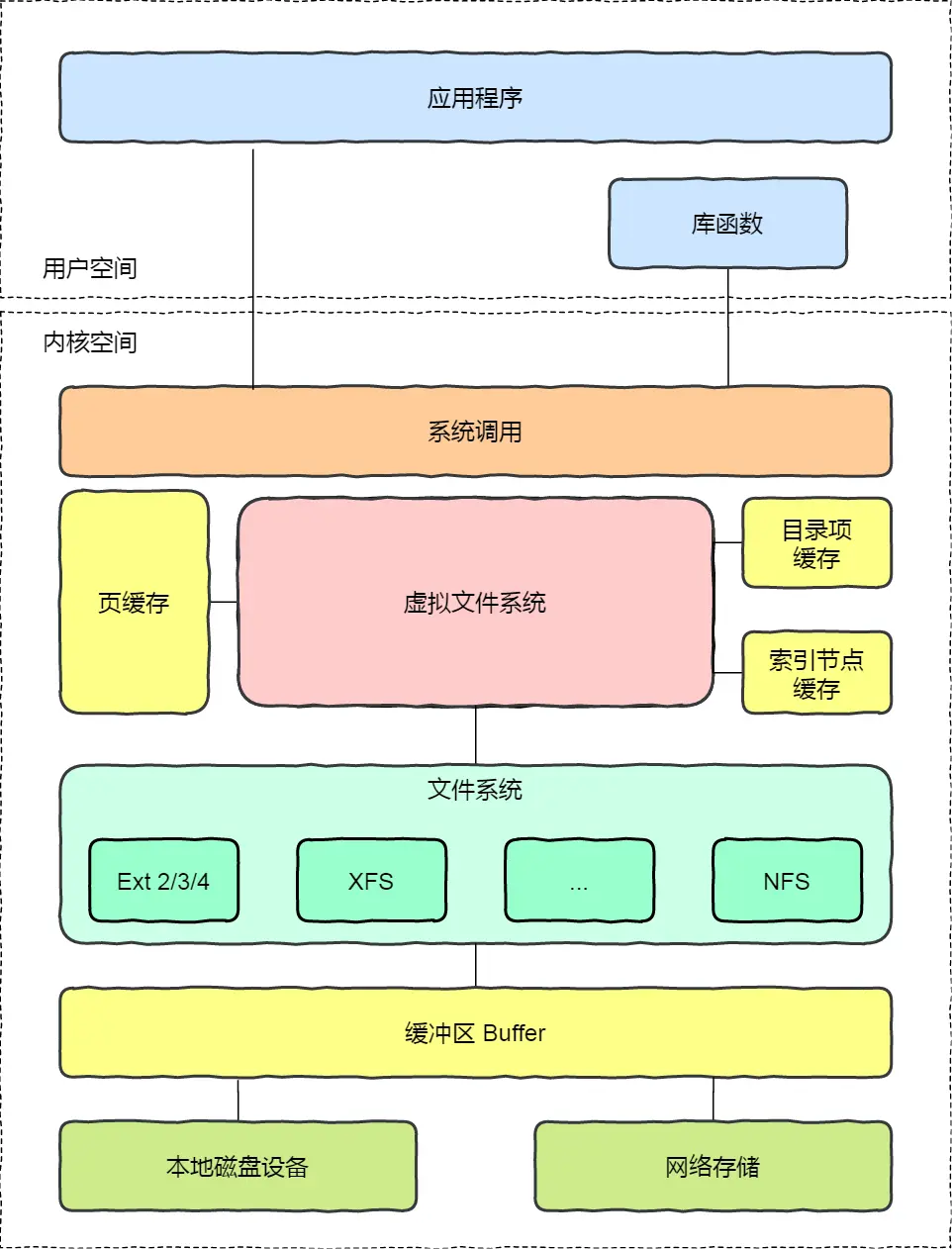
文件系统可以大致分为三类:
- 磁盘文件系统
- 内存文件系统:例如 /proc 目录下的文件,实际上是存储在内存的
- 网络文件系统
文件的使用
在 Linux 中,每个进程的 task_struct 包括了一个 file_struct
file_struct 记录了该进程:
- 打开的文件数组
- 下一个未使用的 fd
- ……
打开的文件数组元素类型为 struct file,这个结构记录了一个文件的:
- 文件描述符
- 下一次读写的位置
- 文件路径
- 文件描述符的引用计数
进程每打开一个文件,内核就会追加一个 file 到 file_struct 的文件数组中
而关闭文件需要判断文件描述符的引用计数是否为 0,如果为 0,可以释放相关资源
文件系统的基本单位是 块
- 当一个进程尝试读取数据时,OS 会从磁盘对应的 块 上读取数据
- 当一个进程尝试写数据时,OS 先找到磁盘对应的 块,再修改数据
上面的过程没有考虑 page cache
文件的存储
前面提到了:inode 记录了一个文件的数据块指针
在 Ext4 文件系统中,inode 包含了 12 个直接指针,1 个间接指针,1 个双间接指针以及 1 个三间接指针。
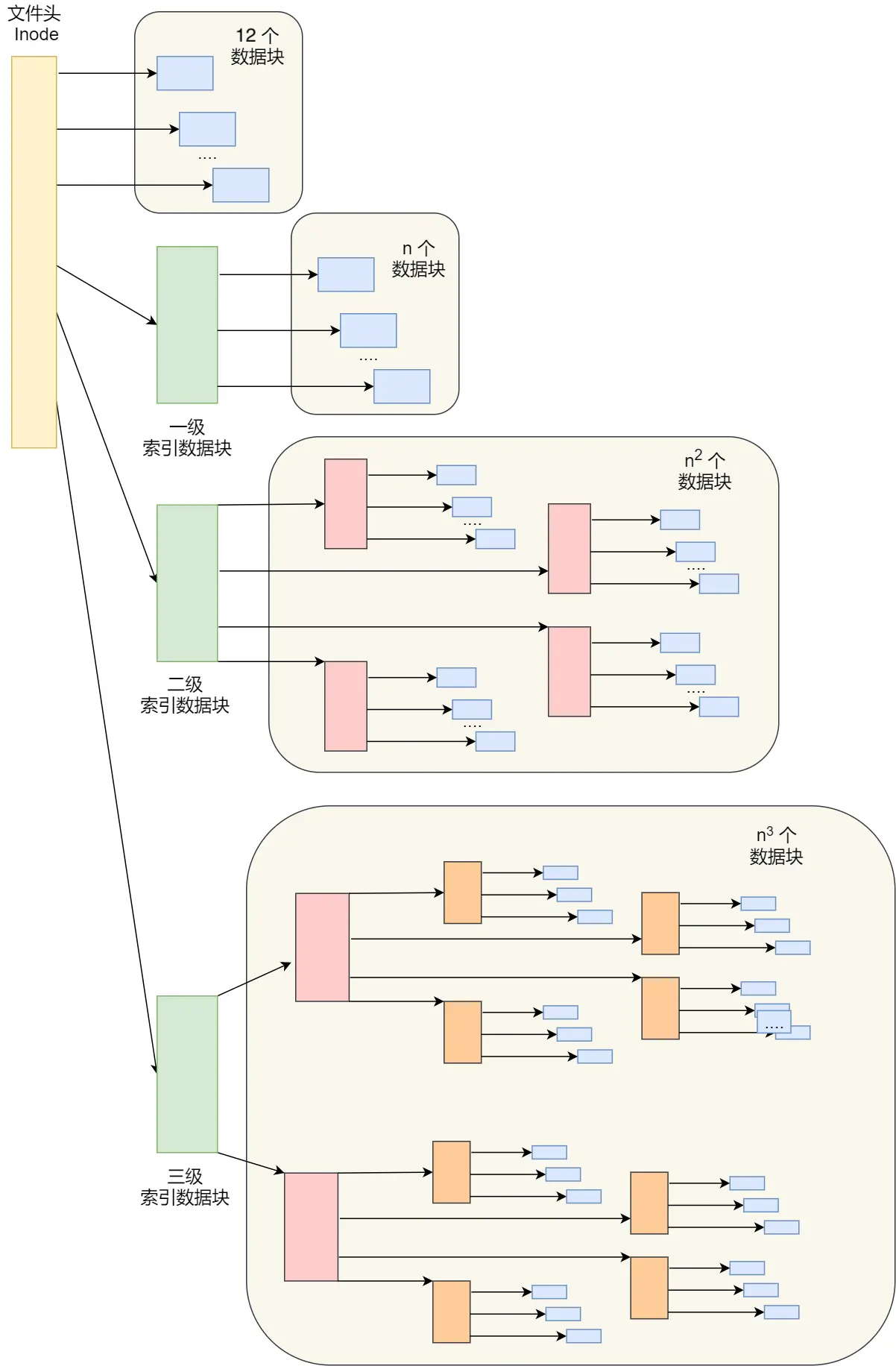
存储文件时:
- 先寻找一个空闲的 inode 号,分配给即将创建的文件
- 寻找空闲的磁盘块,存储文件数据
- 如果 12 个直接指针不足以容纳数据,那么再使用 1 个间接指针,直到存储完毕
这种方式可以灵活的存储大小文件,文件内容的增删查改也比较方便
对于大文件的访问,多级索引会使访问很慢
Ext4 的 extends 特性,优化了这个点
extents 是一种 连续 的物理块区间。在 Ext4 中,文件的数据部分由一个或多个 extents 描述,而不再是由单独的数据块描述。
这样可以减少随机 IO,读写性能较好
空闲空间管理
一个硬盘要么使用,要么没使用,可以简单的用 0、1 表示
OS 使用 位图 来记录数据块是否被使用
- 如果某一位为 0,表示这一块空闲
- 如果某一位为 1,表示这一块已使用
空闲空间包括了数据块的空闲空间和索引块的空闲空间
文件系统的结构
前面提到的位图也是存储在硬盘块中的
一个硬盘块的大小通常为 4K,能表示 2^12 * 8 = 2^15 位
每一位对应一个硬盘块,那么一个位图能表示的空间最大为 2^15 * 4K,即 128M
这对于当今的文件大小来说,肯定不够
于是 OS 将若干个块组合在一起,成为「块组」
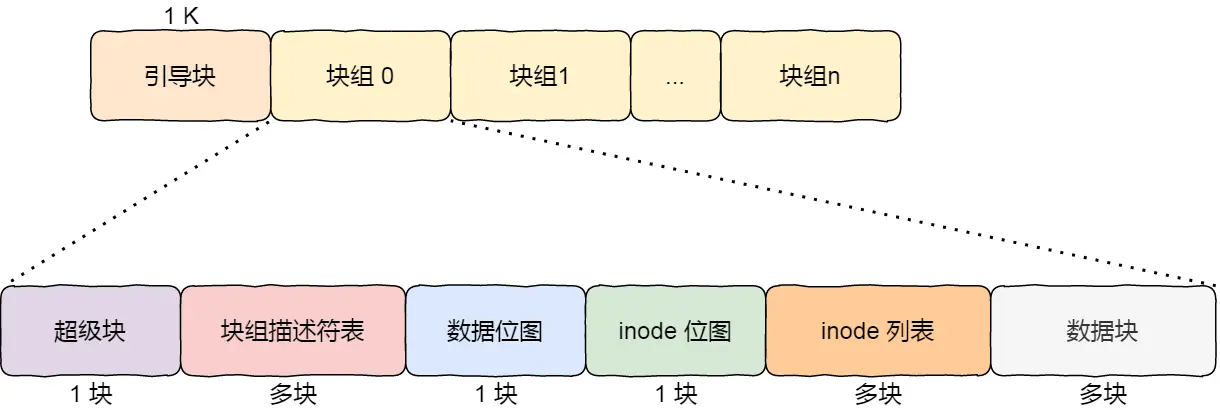
- 超级块:记录了 整个文件系统 的基本信息
- 块组描述符表:记录了 整个文件系统 块组的基本信息
- 数据位图:记录 这一个块组 数据块的空闲情况
- inode 位图:记录 这一个块组 inode 的空闲情况
- inode 列表:包含了 这一个块组 所有的 inode
- 数据块:用于存储数据
单个块为 4K 的情况下,一个块组的大小为 128M
为什么每一个块组都要记录 整个文件系统 的基本信息和 整个文件系统 块组的基本信息呢?不会造成空间浪费吗?
主要有两方面原因:
- 可用性
- 效率
这种 冗余 主要是 保证 文件系统的 高可用
如果全局只有一个超级块和块组描述符表,如果主机突然宕机,或者超级块/块组描述符表对应的数据块损坏,那么整个文件系统就不可用了
如果有冗余的副本,那么即使一个出现问题,还可以恢复
此外,每个块都有文件系统的基本信息,使文件系统的基本信息与该数据块管理的数据较接近,减少随机 IO
目录的存储
目录也是文件的一种,它的 inode 记录了该目录下所有目录项的存储地址
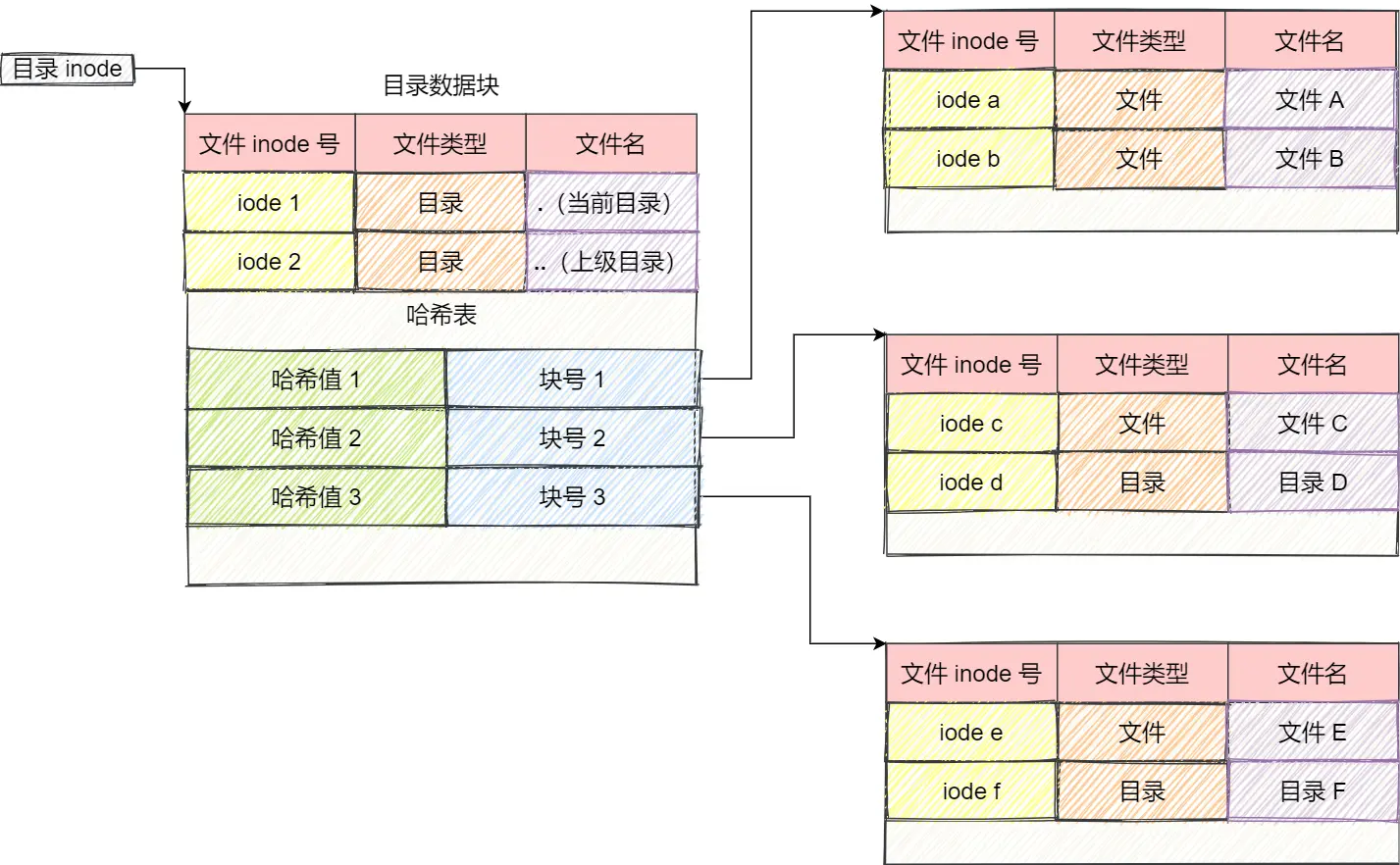
软连接与硬连接
硬连接
之前提到:Unix/Linux 系统内部不使用文件名,而使用 inode 号码来识别文件
实际上,还可以让多个文件对应同一个 inode:
Sky_Lee@SkyLeeMBP test % ln abc def
Sky_Lee@SkyLeeMBP test % ls -1i
8369476 abc
8369476 def
可以看到,abc 与 def 的 inode 值是一样的,它们被称为硬链接,此时,查看 abc 的硬链接数:
Sky_Lee@SkyLeeMBP test % stat -x abc
File: "abc"
Size: 1 FileType: Regular File
Mode: (0644/-rw-r--r--) Uid: ( 501/ Sky_Lee) Gid: ( 20/ staff)
Device: 1,9 Inode: 8369476 Links: 2
Access: Tue Jun 13 15:57:21 2023
Modify: Tue Jun 13 15:57:21 2023
Change: Tue Jun 13 16:50:34 2023
Birth: Tue Jun 13 15:56:50 2023
可以看到,Links 的值为 2
我们对 abc 做出的任何修改都会反应到 def 上,同样的,对 def 做出的任何修改都会反应到 abc 上,这不难理解,因为它们的 inode 值相同,文件的 blocks 肯定也相同,本质上就是同一个文件
当我们删除一个文件时,实际上是让 Links 的值减 1,如果 Links = 0,那么系统将会回收这个 inode,以及对应的 blocks
软链接
软链接类似 windows 上的快捷方式
可以使用 ln -s 来创建软链接:
Sky_Lee@SkyLeeMBP test % ln -s abc softabc
Sky_Lee@SkyLeeMBP test % ls -1i | grep abc
8369476 abc
8370725 softabc
可以看到,abc 与 softabc 的 inode 值不同,说明是不同的文件
文件 IO
缓冲与非缓冲 IO
缓冲 IO 指在用户区实现的缓存,例如 cstdio 中的 printf,fput 等库函数,就是在库内实现了自己的缓冲
例如,用户调用 fput,并不会立即调用 write,而是写到缓冲区,当缓冲区满/遇到换行符/用户手动刷新(fflush)时,才会调用 write
优点主要是可以减少系统调用的次数,减少「变态」的开销
缺点就是有 可能丢数据 ,如果进程挂了,由于部分数据还在用户缓冲区,数据就无法落地到磁盘
直接与非直接 IO
由于磁盘 IO 很慢,内核通常不会直接对磁盘进行读写操作,而是加一个 buffer
例如,用户在调用 write 系统调用时,内核不会直接将数据写到磁盘,而是写到 page cache 中,当满足特定条件,或者用户手动刷新(fsync)时,才会真正的写入磁盘
因此,直接 IO 与非直接 IO 本质区别就是:是否经过了 OS 的 page cache
- 直接 IO 读写数据不会经过内核,而是通过 DMA 的方式,直接操作磁盘
- 非直接 IO 读写数据会经过内核的 page cache,读数据检查 page cache 是否命中,写数据写到 page cache
非直接 IO 也存在丢失数据的风险:如果在 OS 刷新 buffer 之前,主机宕机 了,那么数据就丢失了
阻塞与非阻塞 IO
- 阻塞 IO:当用户发起一个 read 系统调用,线程会阻塞,直到内核将 数据准备好、并且 拷贝到用户空间 后,唤醒用户线程
- 非阻塞 IO:当用户发起一个 read 系统调用,内核会 立即返回 数据是否准备完毕并且已经拷贝到用户空间
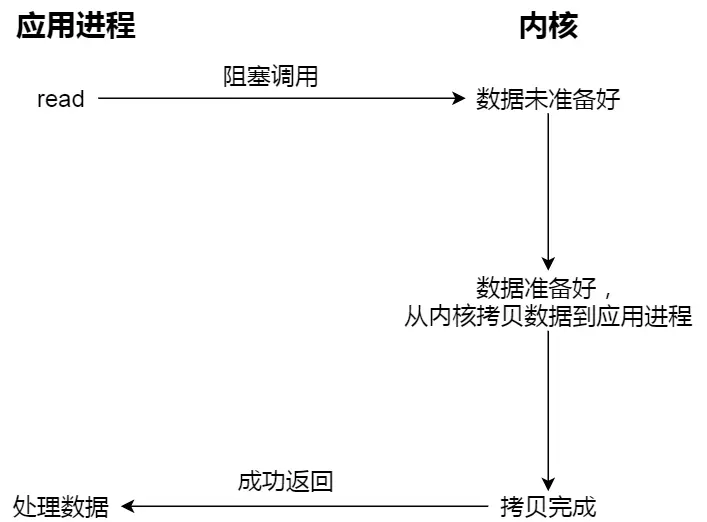
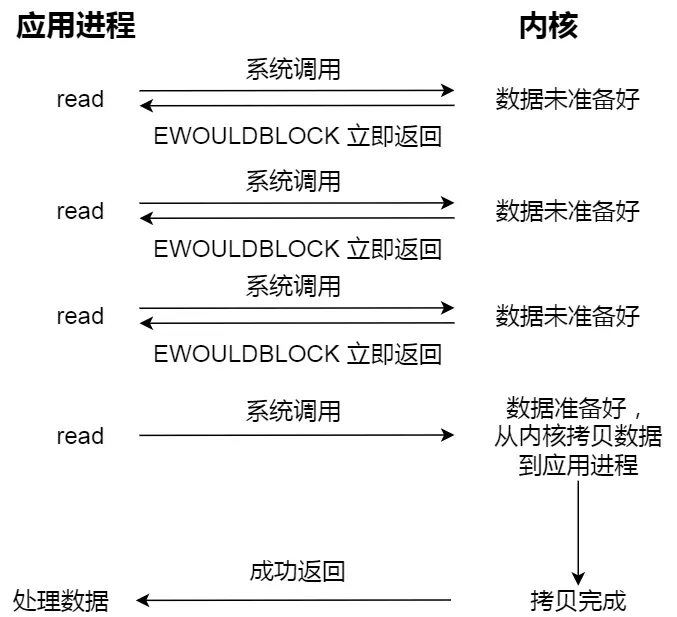
传统的阻塞 IO,效率不高,进程需要一直等待直到数据拷贝到用户空间
而非阻塞 IO 往往需要多次轮询,感觉也不行
为了避免非阻塞 IO 的多次轮询带来的性能开销,引入了 IO 多路复用的概念,比如 select、poll、epoll
IO 多路复用本质是一种 同步 IO,等待事件的过程是同步的,但一个线程可以「同时」处理多个文件描述符上的事件
无论阻塞 IO,还是非阻塞 IO,抑或是 IO 多路复用,本质都是 同步 IO,都需要等待内核将数据准备好
真正的异步 IO,「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待
当调用异步 IO,会立即返回,内核会在数据从内核态拷贝到用户态后,通知进程,在此期间,进程可以去做别的事情
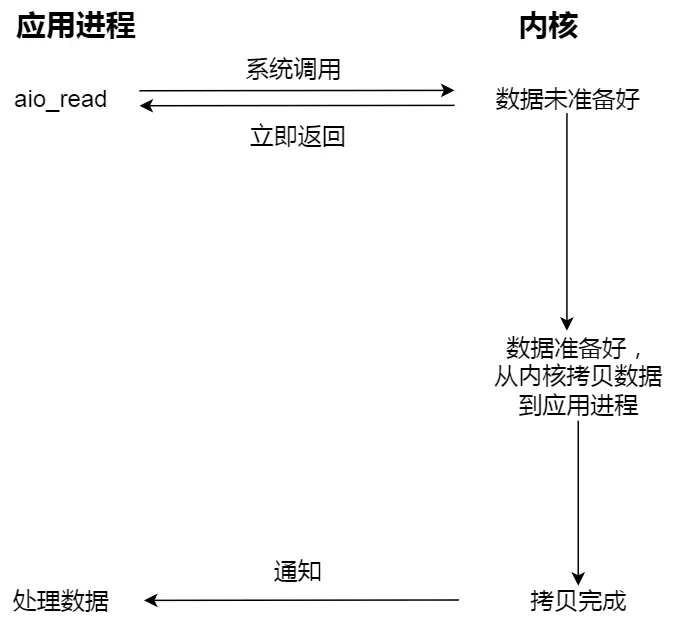
文件读取的过程
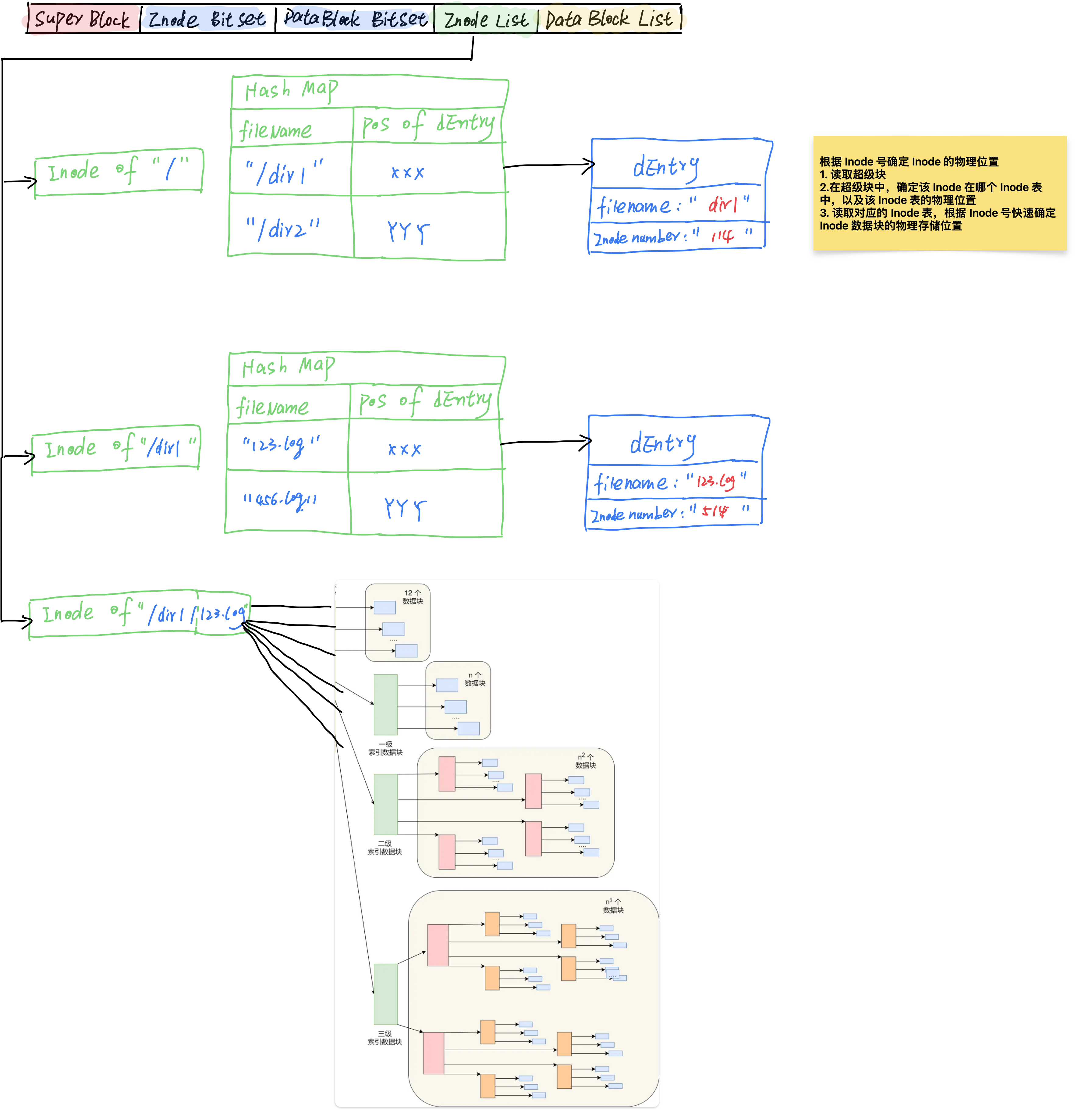
第一步:解析文件路径
例如:对于可执行文件 bluebell 的路径 /Users/Sky_Lee/Documents/Blue-Bell/bin/bluebell ,OS 会将其解析成一个个的目录:/、/Users、……
第二步:确定文件的 inode 号
根目录的 inode 已经确定,根据二级目录名的哈希值,可以在根目录的 inode 中找到二级目录的 inode
第三步:确定文件的 inode 存储位置
确定了二级目录的 inode 号,就可以根据 inode 号寻找到 inode 号所在的 块组
计算出 inode 在块组中的偏移,确定 inode 在块组存储的物理位置
有了二级目录的 inode 的物理位置,就可以读取二级目录的 inode,进而确定三级目录的 inode 号
第四步:重复第二、三步,直到找到最终文件存储的物理位置
递归的进行二、三步,最终可以确定文件存储的物理位置
第五步:读取文件到内存
根据是否为直接 IO,确定是否读取到 page cache
然后再返回数据给用户进程