为什么要有 DMA?
传统的方式,要发送一个数据包,实现方式如下:
- 用户调用 read,读取待发送的数据
- 用户调用 write,写入待发送的数据
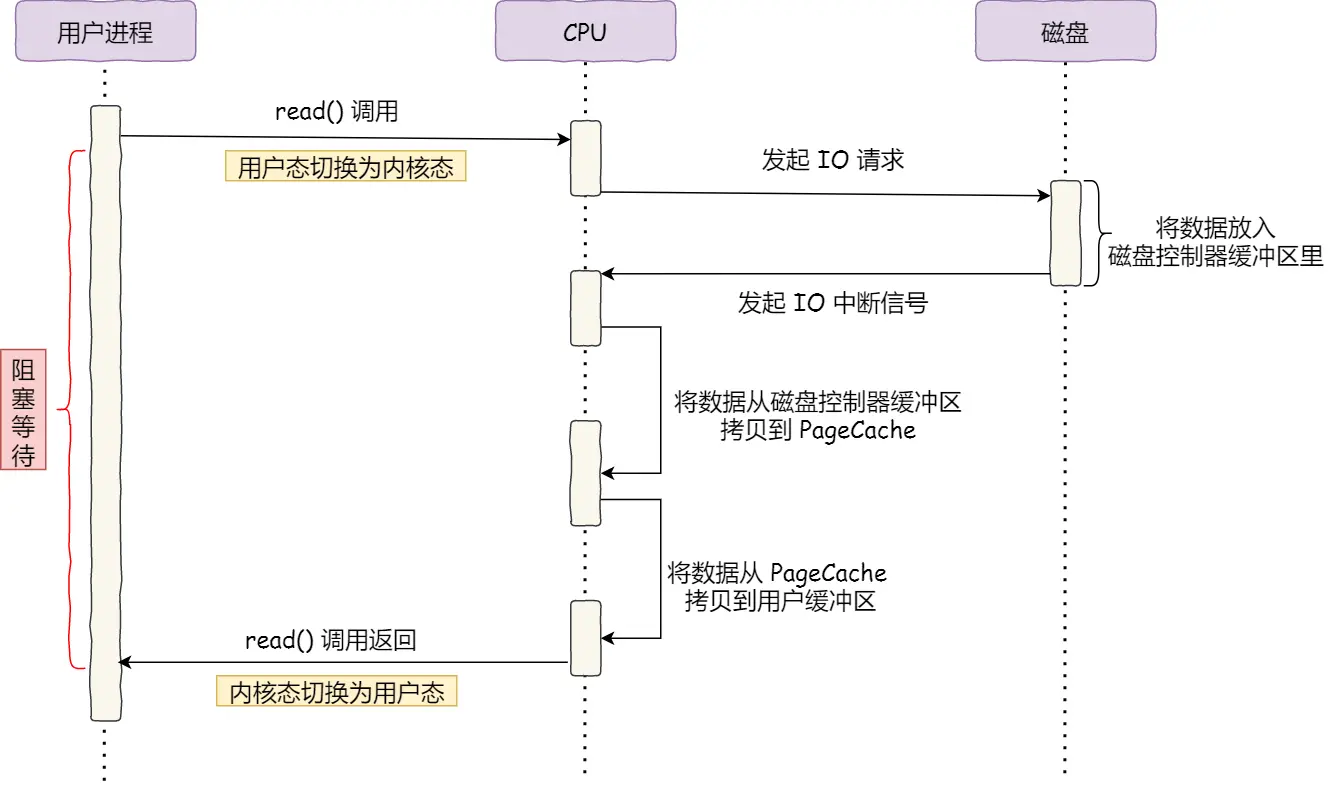
CPU 需要参与整个数据搬运的过程,这无疑会浪费宝贵的 CPU 性能
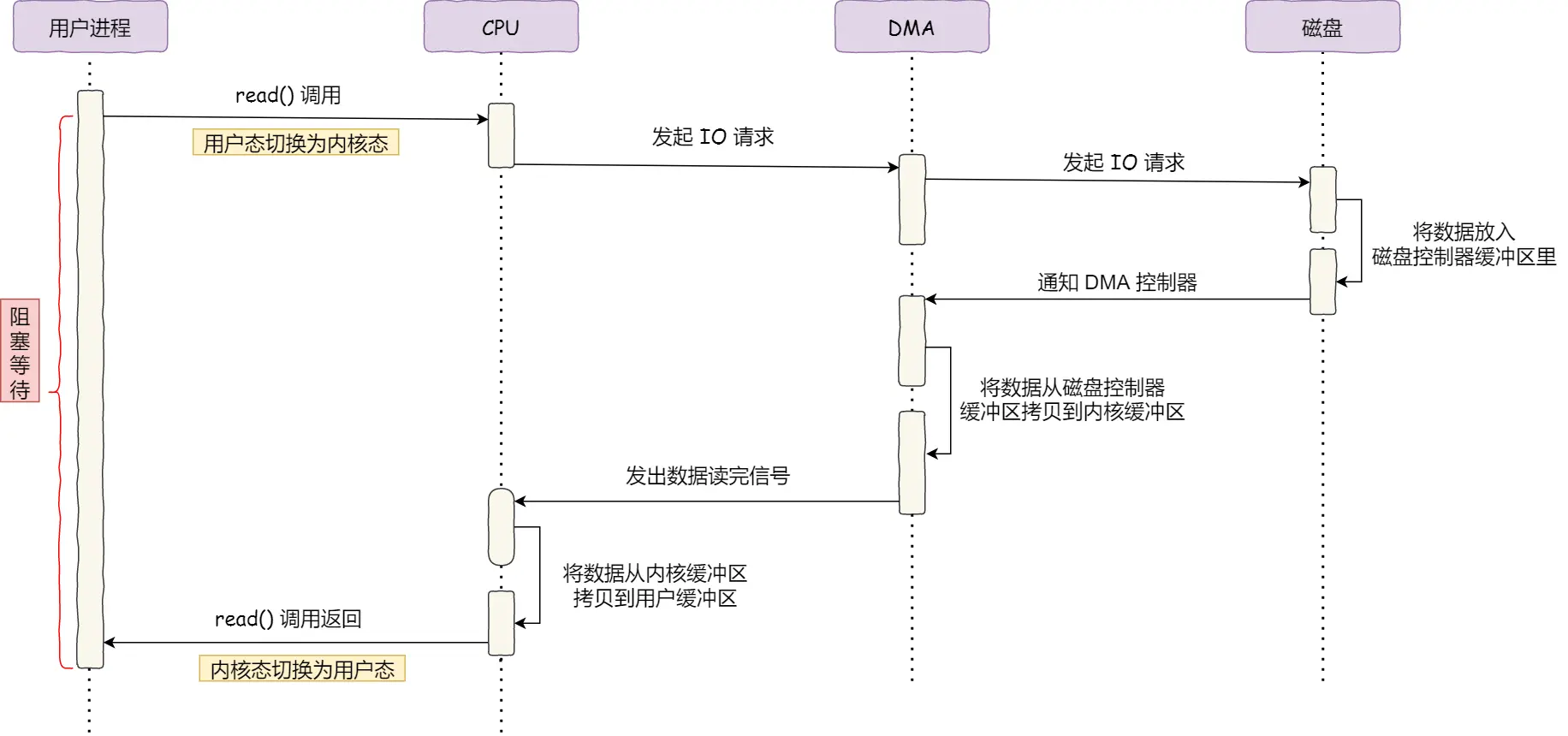
而如果有 DMA 技术,那 CPU 就可以解放出来,让 DMA 参与数据的搬运
什么是 DMA 技术?简单理解就是,在进行 I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给 DMA 控制器,而 CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务
传统的网络文件传输性能为什么差?
传统的文件传输(read/write),整个过程涉及到 两次系统调用,即四次「变态」的过程,四次拷贝(磁盘到内核 buffer、内核 buffer 到用户内存空间、用户内存空间到 socket buffer、socket buffer 到网卡 buffer)
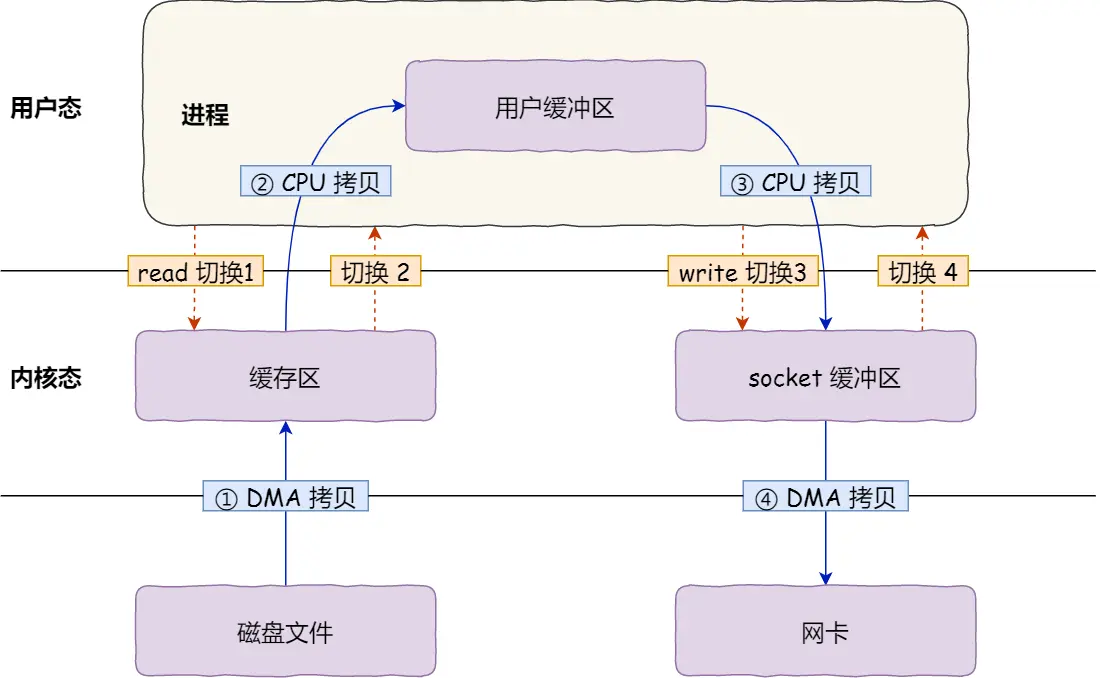
如果进程不会修改要发送的数据,那么完全 没有必要将数据拷贝到用户空间
优化网络传输:零拷贝
零拷贝机制,简单理解,就是 CPU 不参与数据拷贝的过程,并不是真的没有数据的拷贝
如何实现零拷贝?
mmap + write
为了避免数据拷贝到用户空间,可以使用 mmap 而不是 read 来读取数据
mmap 系统调用在读取文件后,会创建一个内核空间到用户空间的映射
当进程在访问这部分的文件时,实际上访问的是内核空间,避免了数据拷贝到用户空间
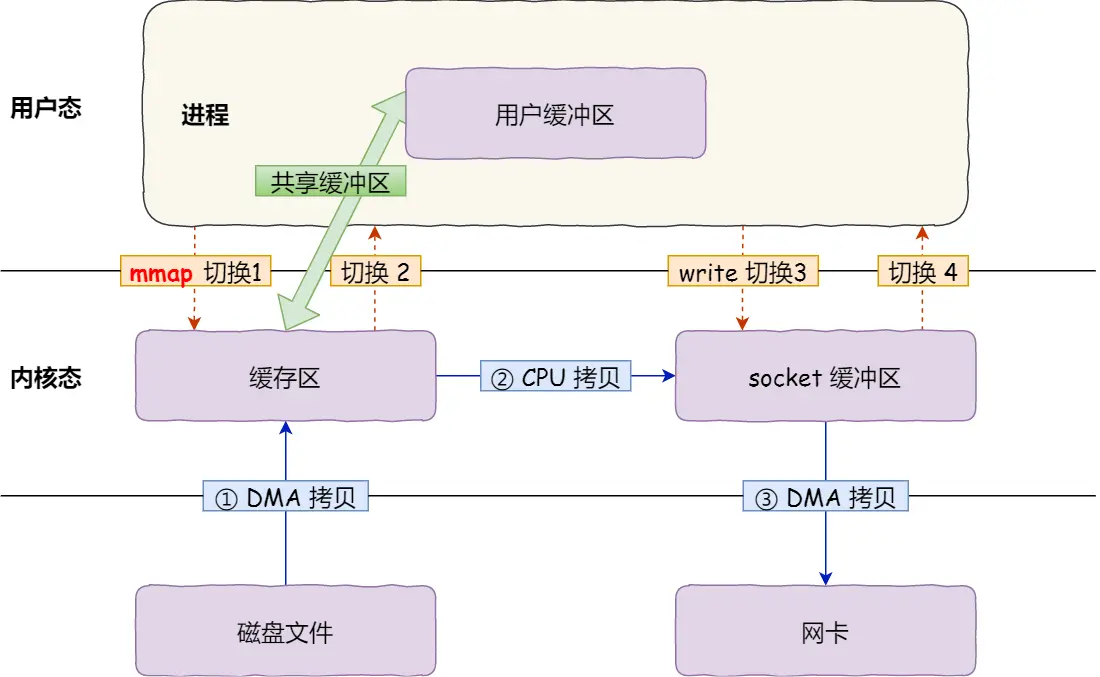
但是这还不是真正的零拷贝,因为还是需要 CPU 参与从 page cache 到 socket buffer 的拷贝过程
此外,这种方式仍需要两次系统调用
sendfile
为了避免两次系统调用带来的开销,Linux 提供了一个系统调用 sendfile,可以实现一次系统调用,就将一个文件描述符的指定数据发送到另一个文件描述符
sendfile 定义如下:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
这种方式,不仅只需要一次系统调用,也避免了数据在内核空间和用户空间之间的相互拷贝
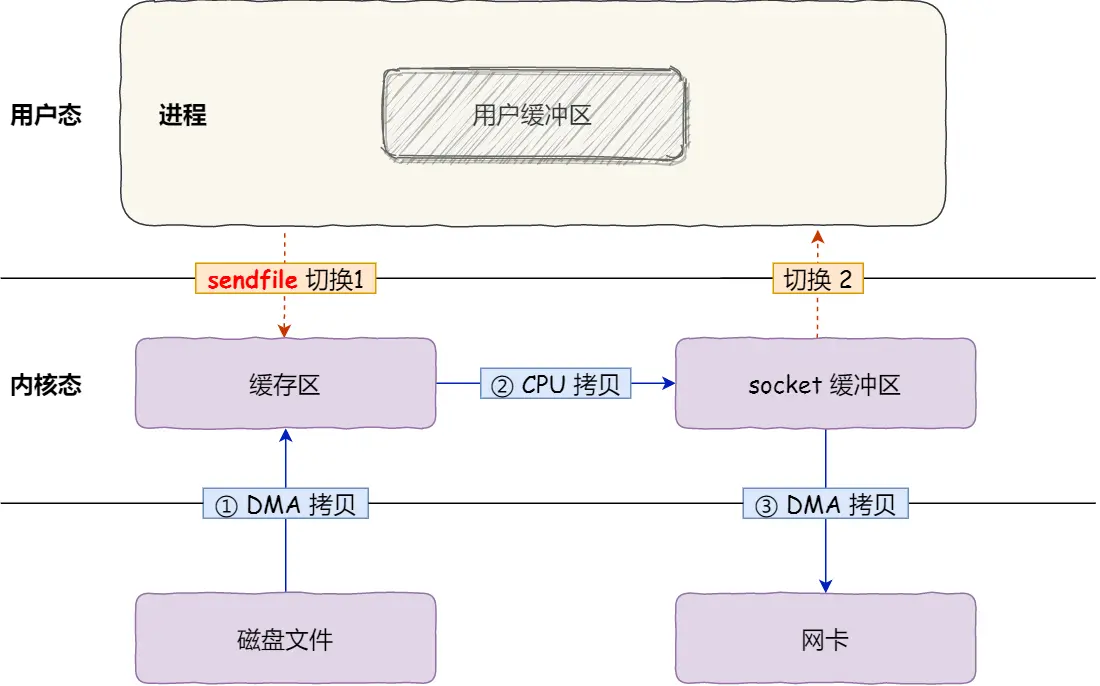
但是似乎还不是真正的零拷贝?
如果网卡支持 SG-DMA,那么就可以利用网卡的 DMA 技术,直接从内核的 page cache 读取数据到网卡,避免到 socket buffer 的拷贝
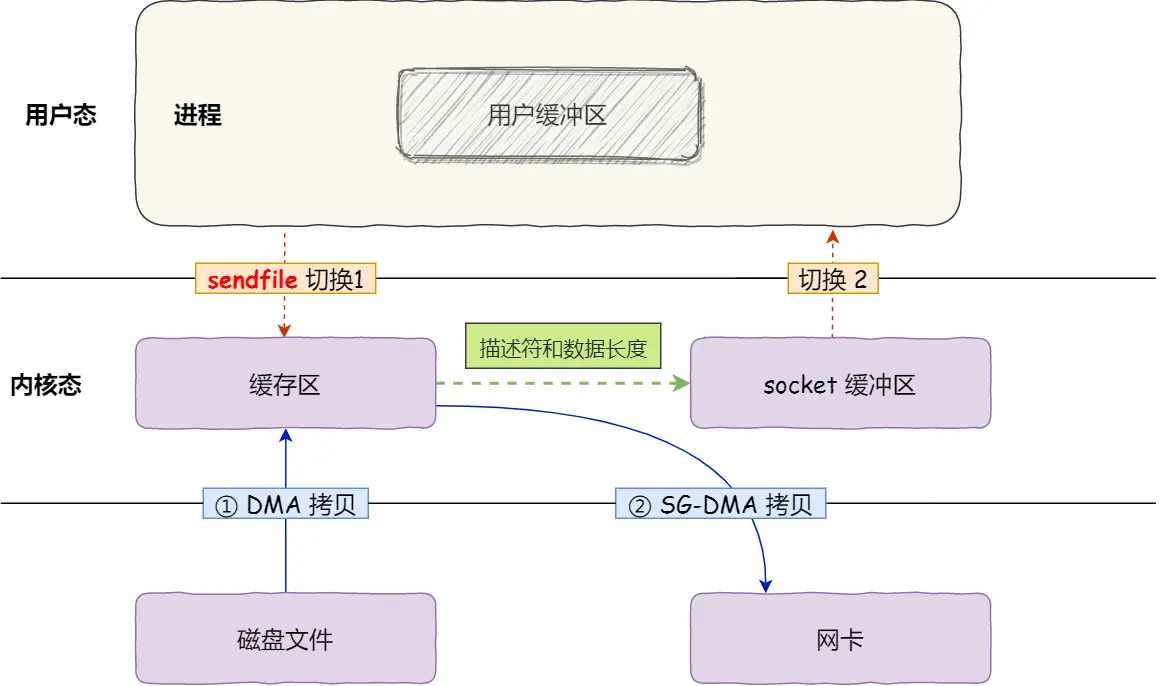
大文件传输
大文件就不适合使用 page cache 了
因为 page cache 就那么大,往往大文件后面部分读进来以后,前面部分的数据就被 LRU 淘汰掉了,下一次读取相同的大文件也享受不到 page cache 带来的加速,反而导致 page cache 频繁淘汰影响性能
因此,大文件的传输反而适合 直接 IO
DMA 的方式,将大文件从硬盘 拷贝 到 用户空间,用户空间在 直接 写到网卡发送即可
Reactor 与 Proactor
Reactor 与 Proactor 是两种常见的网络 IO 处理模式
传统的网络 IO 处理模式:
- 单进程
- 多进程
- 多线程
往往都无法支持较高的流量
- 对于单进程,只有一个进程处理用户的并发请求
- 对于多进程,虽然可以并发处理请求,但是进程之间的切换需要较大开销
- 对于多线程,相较于多进程而言,虽然调度开销小了,但性能仍然一般
而 Reactor 与 Proactor 模式,可以处理较高的并发量,下面来看看怎么实现
对于 Reactor 模式,无论采用哪种模式,本质都是基于 IO 多路复用
而 Proactor 模式是基于 异步 IO 实现的
单 Reactor 单线程
这种模式只有一个线程来处理客户端的并发请求
- 将服务器 socket 添加到 select/epoll 感兴趣事件
- Reactor 循环调用 select/epoll_wait,监听
- select/epoll_wait 返回,分发 事件:
- 连接请求事件:交给 Acceptor 建立连接,注册 client_socket 到 select/epoll
- 其它事件:交给 Handler,使用对应业务逻辑处理即可
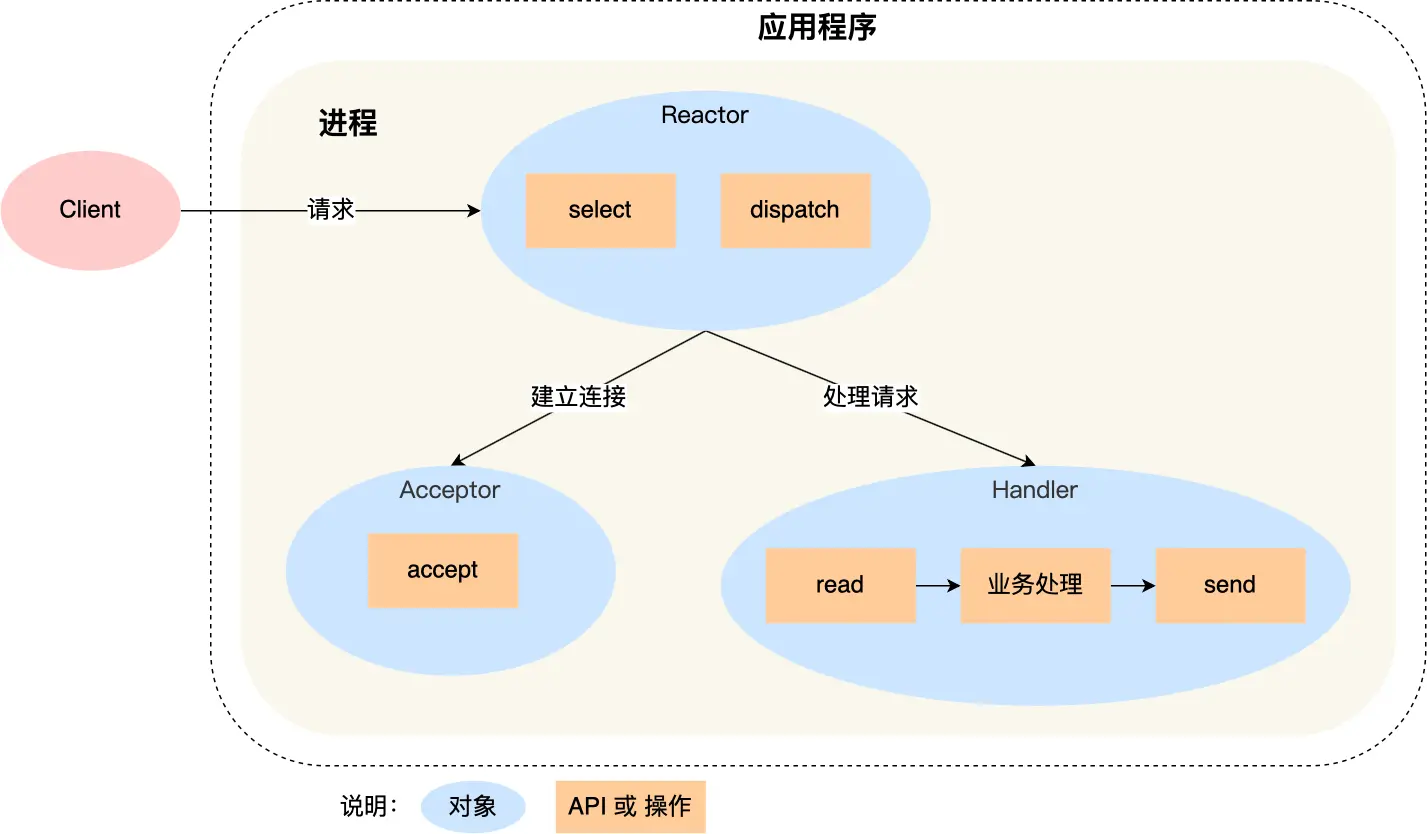
对于 Reactor 模式,有三个基本对象:
- Reactor:监听、分发事件
- Acceptor:接受连接,注册 client_socket 到 Reactor
- Handler:处理事件(业务逻辑)
而单 Reactor 单线程,这三个对象的处理,都是在同一个线程进行的
这种模式能支持的并发量也比较有限,如果某个 Handler 的处理时间过长,会造成后面请求的延迟
6.0 版本以前的 Redis 采用的就是这个模式,因为 Redis 的业务逻辑是纯内存操作,单线程的 Handler 的处理速度已经很快,使用多线程 Handler 反而会增加额外的调度开销
在 6.0 版本的 Redis,在 IO 处理部分 引入了多线程
具体来说:
Reactor 在分发事件时:
- 如果该事件是建立连接事件,分发给 Acceptor
- 否则,将 client_socket 分发给 IO threads
IO threads 会 并发 的读取 client 发来的请求,并将请求扔到主 Reactor 的 task queue
主 Reactor 处理 task queue 的请求时,仍然是 单线程 的,具体来说:
- 主 Reactor 拉取 task queue 的每一条请求,处理
- 处理完毕后,将「响应数据 + client_socket」分发给 IO threads
IO threads 会 并发 的将 response_data 写入到对应的 client_socket
单 Reactor 多线程
事实上,Handler 的处理逻辑 可以是多线程的
Handlers 通常使用线程池复用线程,避免线程的频繁创建与销毁带来的开销
单 Reactor 多线程,Reactor 在分发事件时:
- 如果该事件是建立连接事件,分发给 Acceptor
- 否则,处理 IO,并将请求扔到工作队列
工作队列内部有一个线程池,一个 task 队列,采用 生产-消费 模式
每个 work thread 的工作逻辑如下:
- 阻塞等待 task_queue,直到 task_queue 不为空
- 拉取 task_queue 的任务,执行对应业务逻辑
- 写响应结果给客户端,并 注册写事件 到主 Reactor
真正的返回响应时机是主 Reactor 处理写事件时
多 Reactor 单线程
多 Reactor 单线程相较于单 Reactor 单线程没有任何性能优势,因此不被使用
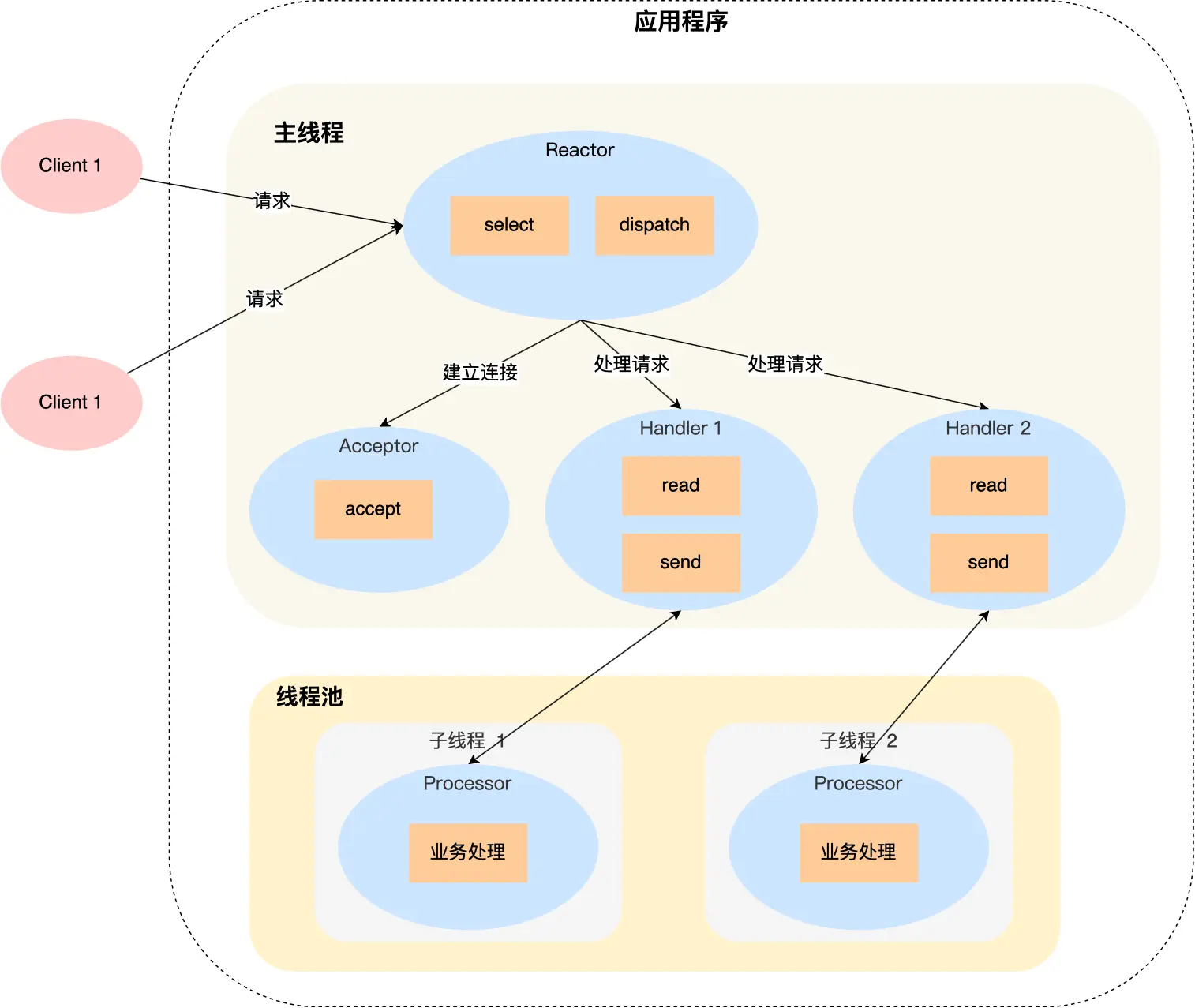
多 Reactor 多线程
与单 Reactor 多线程不同,多 Reactor 多线程模式下,有多个 Reactor:
- 一个主 Reactor
- 多个从 Reactor
主 Reactor 负责处理客户端的连接请求,并将 client_socket 均匀地(即负载均衡) 注册到多个从 Reactor 中
从 Reactor 就专心处理客户端的读写事件,逻辑与单 Reactor多线程基本一致
多 Reactor 多线程相比较单 Reactor 多线程,主要优势在于:在 accept 新的连接的「同时」,可以处理已建立连接的客户端的请求,提高 CPU 利用率
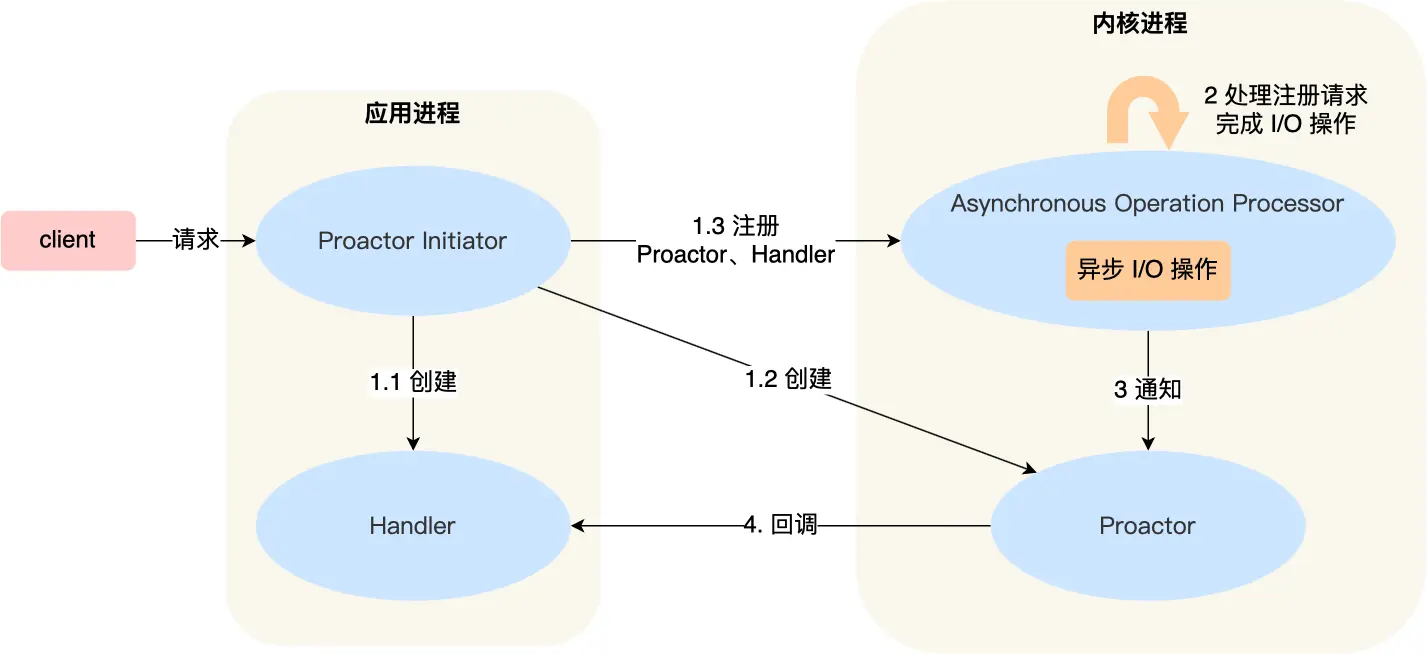
Proactor
Proactor 与 Reactor 最大的不同就是使用 异步 IO
Reactor 采用的 IO 多路复用,可以看作「来了事件,内核通知应用进程,应用进程负责处理」
而 Proactor 采用的异步 IO,可以看作「来了事件,内核把事件处理好了(即准备好数据),再通知应用进程」
无论 Reactor 还是 Proactor,都是 事件驱动 IO 模型,只不过 Reactor 是基于「未完成」IO 事件,Proactor 是基于「已完成」IO事件
虽然目前 Linux(4.18 以上) 原生支持了异步 IO(io_uring)
但在这之前,aio 系列函数是 POSIX 在用户层面实现的异步 IO,并且仅仅支持基于本地文件的 aio 异步操作,网络编程中的 socket 是不支持的
这也使得目前基于 Linux 的高性能网络程序都是使用 Reactor 方案。
一致性哈希
传统的负载均衡策略
通常的负载均衡,由一个「负载均衡层」来实现请求均衡的发送到不同的节点
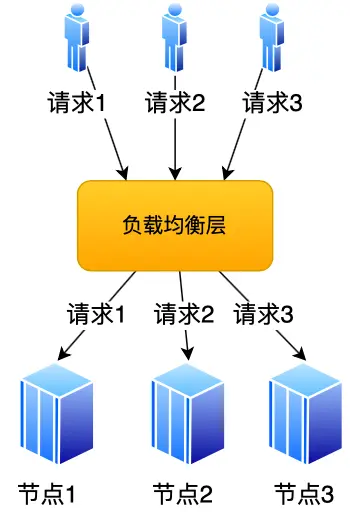
负载均衡策略可以是轮询等等
但是这种方式一般只用于应用服务器
像 Redis 集群,每个节点存储的数据可能不同,每个 key 的数据存储在哪些节点是确定的,如果采用轮询的策略,不能保证访问的节点一定存储着想要的数据
使用普通哈希算法实现负载均衡有什么问题?
对于上面的场景可以想到哈希取模策略:
- 在存储数据时,算出一个 key 的哈希值,并对节点数取模,得到待存储节点
- 在访问数据时,算出该 key 的哈希值,并对节点数取模,得到存储节点
这种方法确实解决了问题,但是并没有实现 均衡,可能出现 倾斜 的情况
还有一个更严重的问题:不利于节点的扩缩容
如果要对节点进行扩缩容,需要迁移大量数据(最坏的情况,需要迁移所有数据),成本太高了
一致性哈希
那么有没有一种方式避免迁移大量数据带来的开销呢?
一致性哈希算法就是用来解决这个问题的
一致性哈希除了会对 key 哈希取模以外,首先要先 对节点取模,例如按照节点的 IP:Port 取模
取模之后,将节点放在「哈希环」的对应位置上:
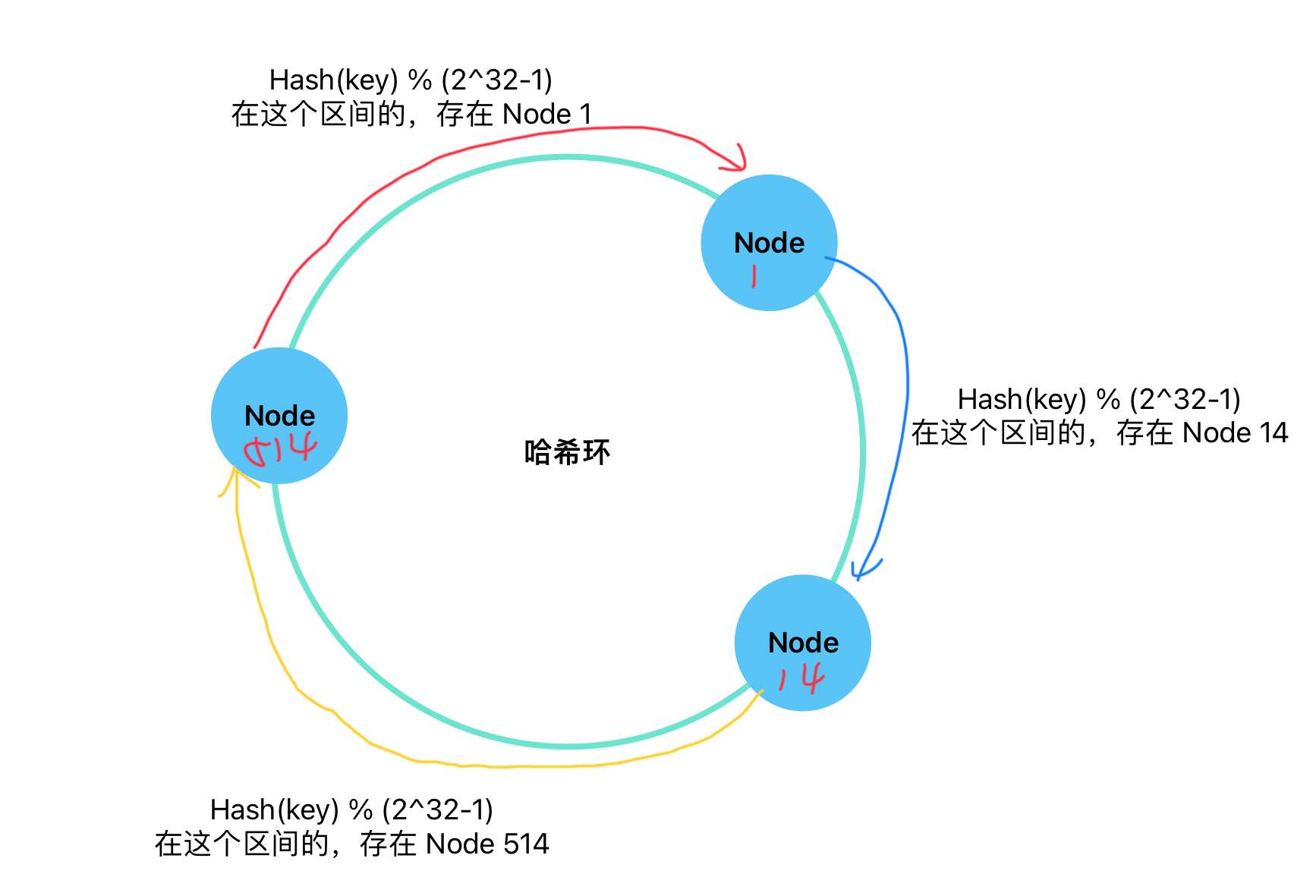
对 key 哈希取模以后,将 value 存储在该位置顺时针第一个 Node 上
如果发生节点的扩缩容,例如删除节点 14,只需要迁移 Node1 ~ Node14 之间的数据到 Node514,大大减小了扩缩容带来的成本
如果出现映射节点时,出现哈希冲突?
这个概率很小,因为是对 2^32 - 1 取模,很难出现冲突
如果出现冲突,可能会向应用进程抛出异常?
但是,如果节点映射到位置很接近,比如:
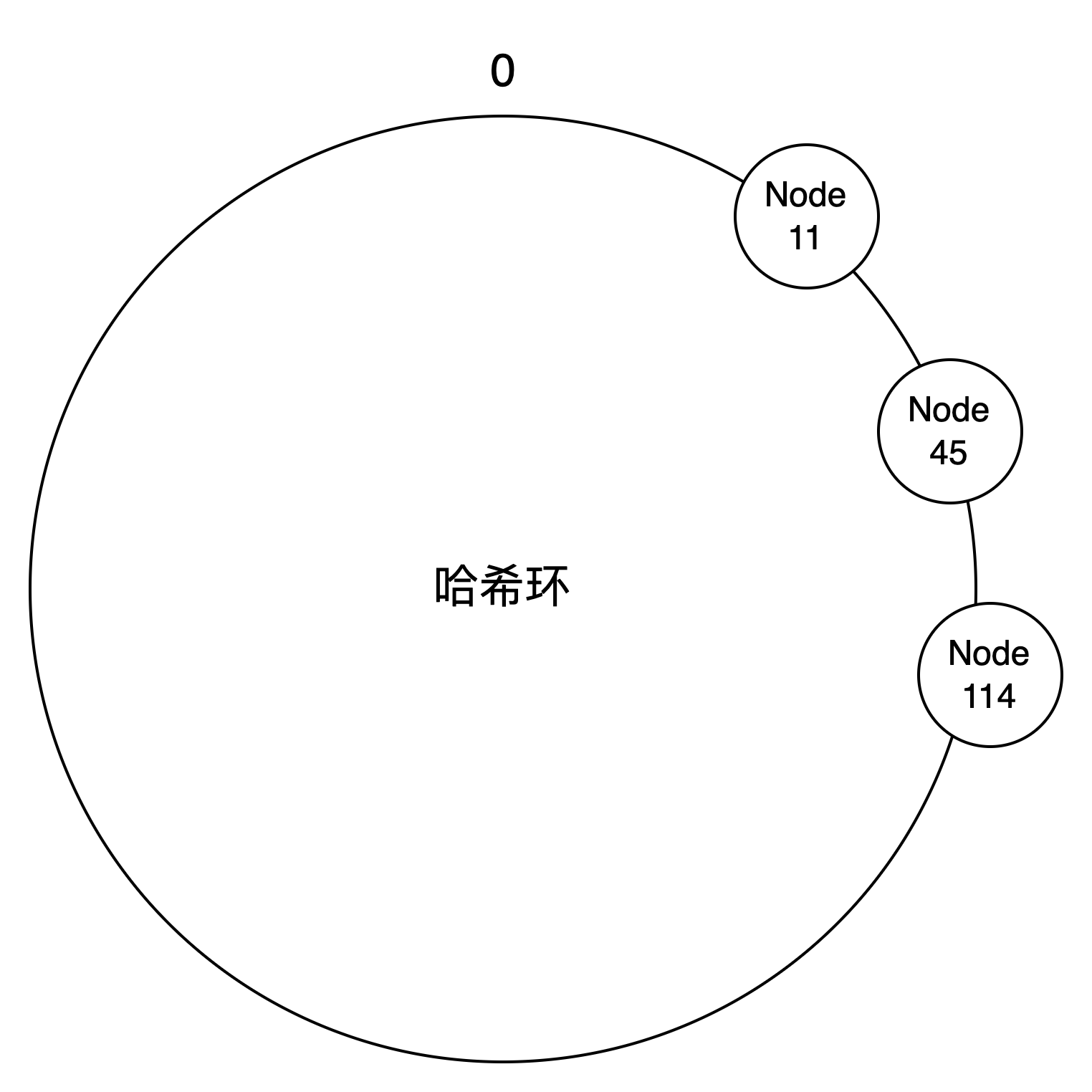
那么对 Node11 的压力就会很大,并且,如果要删除 Node11,那压力全跑到 Node45 上,Node45 扛不住,挂了,压力又转移到 Node114 上,造成 雪崩
引入虚拟节点
为了尽可能的实现负载均衡,不让大部分数据压在同一节点,可以为一致性哈希引入 虚拟节点 的概念
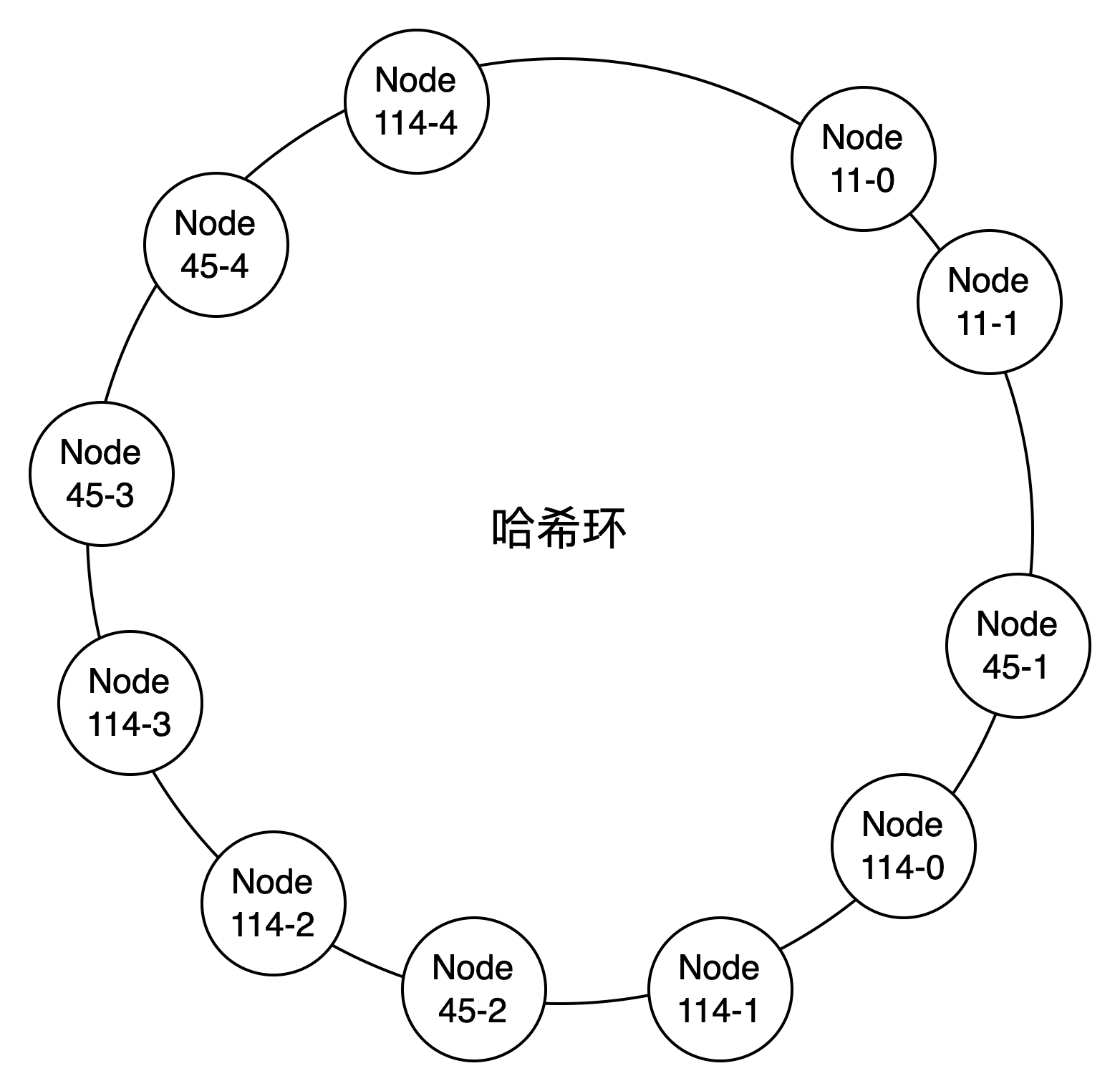
- Node11-0~Node11-1 映射到 Node11
- Node45-0~Node45-3 映射到 Node45
- Node114-0~Node114-3 映射到 Node114
这样负载会更加均衡
此外,删除一个节点,也不会迁移大量数据到同一个节点,会有多个节点共同分担