底层数据结构
2024.06.08 更新
补充一张思维导图:
SDS(简单动态字符串)
传统的 C 字符串存在以下问题:
- 获取 strlen 效率低
- 无法存储文本以外的数据(二进制不安全)
- 不支持动态扩容,append 字符串效率低
Redis 为了解决 C 字符串的这些问题,对其进行了进一步封装:
// __attribute__ ((__packed__)) 的意思是让编译器不要进行内存对齐
// 进一步节省内存空间
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
可以看出,SDS 有以下基本字段:
- len:字符串的长度
- alloc:字符串已分配内存的大小
- flags:字符串类型
- buf:实际存储的数据
动态扩容
SDS 支持动态扩容,当 buf 的空间无法满足存储需求,会自动扩容,这点与 C++ 的 std::vector 是一致的
动态扩容的策略如下:
hisds hi_sdsMakeRoomFor(hisds s, size_t addlen)
{
... ...
// s目前的剩余空间已足够,无需扩展,直接返回
if (avail >= addlen)
return s;
//获取目前s的长度
len = hi_sdslen(s);
sh = (char *)s - hi_sdsHdrSize(oldtype);
//扩展之后 s 至少需要的长度
newlen = (len + addlen);
//根据新长度,为s分配新空间所需要的大小
if (newlen < HI_SDS_MAX_PREALLOC)
//新长度<HI_SDS_MAX_PREALLOC 则分配所需空间*2的空间
newlen *= 2;
else
//否则,分配长度为目前长度+1MB
newlen += HI_SDS_MAX_PREALLOC;
...
}
- 如果扩容后的大小小于 HI_SDS_MAX_PREALLOC,那么分配当前空间的 2 倍
- 如果扩容后的大小大于 HI_SDS_MAX_PREALLOC,那么分配当前空间 + 1M
类型
为了进一步减少内存占用,Redis 设计的 SDS 有五种类型:sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64
这五种类型的区别仅仅是 len、alloc 的类型不同
sdshdr 后面的数字决定了 len、alloc 的占用的字节数,这样可以保证单个 SDS 的头不会浪费太多内存
List(链表)
Redis 实现的链表是双向链表,没有什么特别的
List 的缺点:
- 无法利用 CPU Cache
- 存在内存浪费:每个 Node 都要保存 prev 和 next 指针
ZipList(压缩列表)
为了解决 List 的内存占用问题,Redis 实现了 ZipList
ZipList 会分配一块连续的内存空间用于存储数据,可以充分利用 CPU Cache
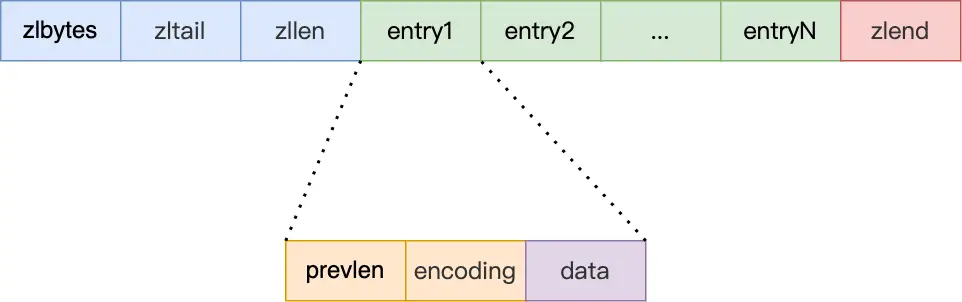
每个 Node 保存三个数据:
- prev_len:到前一个节点头部的距离,提供从后到前的遍历能力
- encoding:编码方式、数据长度
- data:存放的数据
ZipList 在首尾插入、删除数据的时间复杂度为 O(1),效率高,但是要获取中间节点的值,就只能和链表一样遍历了
连锁更新
压缩列表节点的 prevlen 属性会根据前一个节点的长度进行不同的空间大小分配:
- 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
- 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
目的是为了节省内存占用
但基于这种机制,ZipList 存在连锁更新的问题:来看一下这个场景:

如果要在头部插入一个数据,且占用的内存超过 254 字节:
- e1 节点的 prev_len 无法保存头部数据的长度,只能扩容到 5 字节
- 由于 e1 节点的 prev_len 扩容,e1 节点整体占用的字节数也超过了 254 字节
- e2 节点的 prev_len 无法保存头部数据的长度,只能扩容到 5 字节
- …
这样,后续节点都需要扩容,直到可以保存下前一个节点的长度
如果扩容的节点数较多,那么性能就会很差
因此,ZipList 适用于数据量较少,这样即使发生连锁更新,也可以接受
QuickList
QuickList 与普通的 List 的区别在于:
- 普通的 List,节点保存的就是实际的 value
- QuickList,节点保存的是一个 ZipList
因此,在插入新的数据时,不一定要创建新的 Node,如果 ZipList 可以存下,那么就直接放在 ZipList 中
QuickList 相较于普通的 List,优点如下:
- 插入新的数据时,平均效率较高
- 读取数据时,局部可以使用到 CPU Cache
ListPack
为了解决 ZipList 的连锁更新问题,Redis 5.0 引入了新的数据结构 ListPack
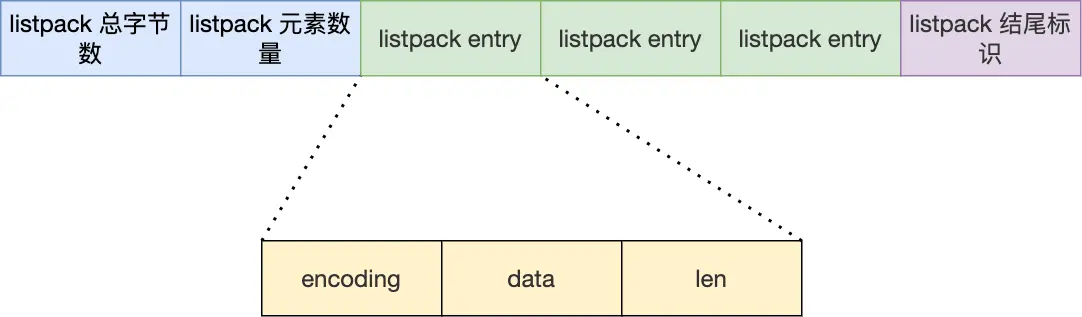
ListPack 继承了 ZipList 的优秀设计,例如也采取连续分配内存的方式、节点采用不同的编码方式以节省内存
但与 ZipList 不同的是:节点 不需要记录 prev_len 了,这样插入数据时,也不会出现连锁更新的问题
不记录 prev_len,如何倒序遍历?
ListPack 可以根据一个 Node 的首地址,利用位运算,逐个向左解析,得到上一个节点的起始位置:
/* Decode the backlen and returns it. If the encoding looks invalid (more than * 5 bytes are used), UINT64_MAX is returned to report the problem. */ uint64_t lpDecodeBacklen(unsigned char *p) { uint64_t val = 0; uint64_t shift = 0; do { val |= (uint64_t)(p[0] & 127) << shift; if (!(p[0] & 128)) break; shift += 7; p--; if (shift > 28) return UINT64_MAX; } while(1); return val; }
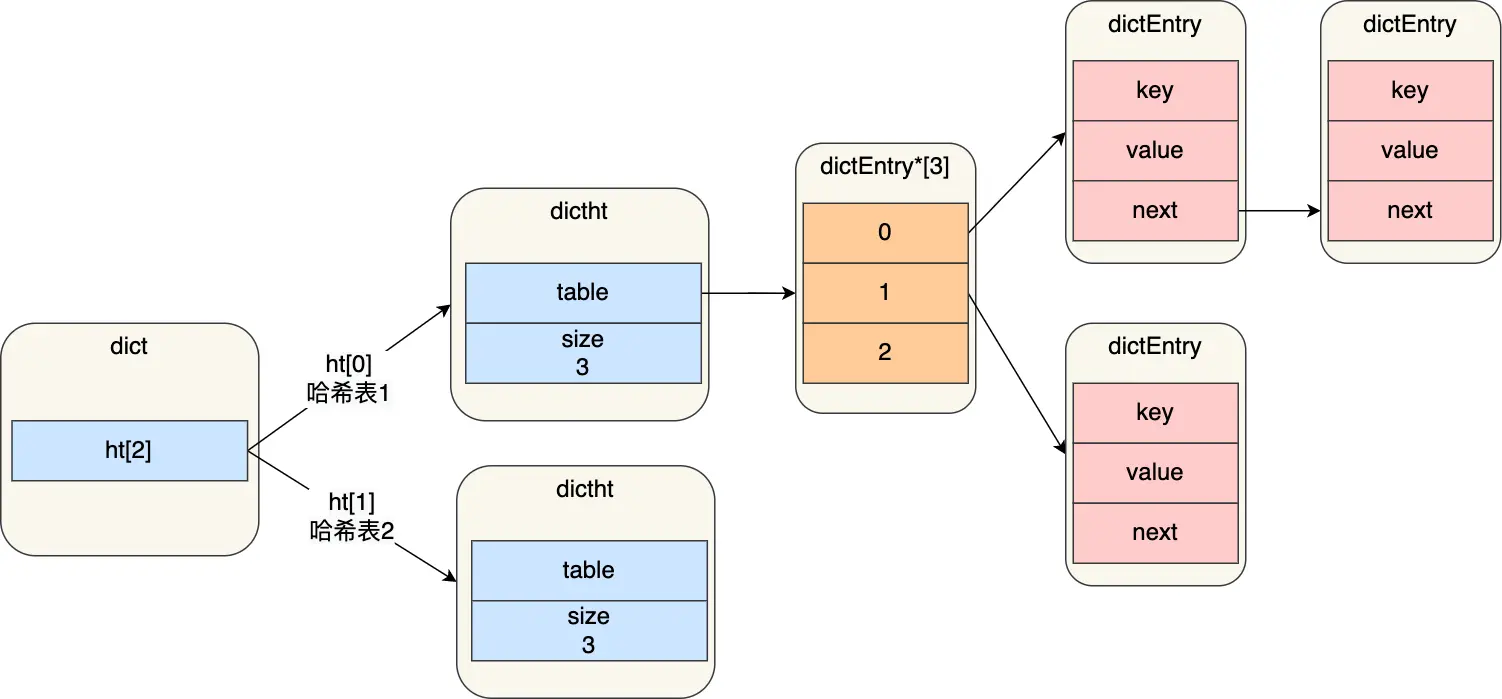
Dict
Redis 实现了哈希表数据结构
Dict 整体有两个 Hash Table,第一个用于存储实际数据,第二个用于 rehash
Redis 实现的哈希表使用链地址扫描法来解决哈希冲突
rehash
整个哈希表通过 负载因子 来衡量冲突的程度,负载因子越大,冲突越严重
如果一直这样下去,那么哈希表的查找效率就会退化为 O(n)
因此,Redis 默认在负载因子:
- 大于 1:如果此时没有进行 bgwriteaof 以及 bgsave,执行 rehash
- 大于 5:强制 rehash
rehash 的过程如下:
- 给哈希表 2 分配空间
- 将哈希表 1 的数据「迁移」到哈希表 2(迁移包括了整理数据的过程,降低负载因子)
- 释放哈希表 1 的空间
- 将哈希表 2 设置为哈希表 1
渐进式 rehash
由于数据量较大,rehash 的时间可能很长,为了避免直接 rehash 带来的性能影响,Redis 引入了渐进式 rehash,过程如下:
- 给哈希表 2 分配空间
- 当客户端执行操作时,将哈希表 1 对应索引处所有的 key-value 迁移到哈希表 2
- rehash 时,新增的 kv 都存在哈希表 2
随着客户端执行的操作越多,哈希表 1 的数据会逐渐迁移到哈希表 2
Int Set
如果哈希表存储的全是整数,并且数据量不大,用哈希表就显得有点重了
Int Set,即整数集合,用于存储一系列整数
Int Set 的定义如下:
typedef struct intset {
uint32_t encoding; // 编码方式
uint32_t length; // 数组长度
int8_t contents[]; // 数组,注意,元素的实际类型并不一定是 int8_t ,取决于 encoding
} intset;
contents 的数据是 有序 的,在查找数据时,可以使用 二分
为了节省内存,Int Set 的元素默认采取 int8 类型
如果新插入的元素无法用 8 个字节存储,Int Set 会进行类型升级
例如,假设此时 contents 的元素为 {11, 45},那么 int8_t 的编码就能满足了
如果此时插入一个新的元素,假设为 114514:
- 114514 的类型为 int32_t,大于 int8_t
- 提升 contents 的编码类型 为 int32_t(扩容实现)
- 倒序 遍历 contents,将原有数据向后移动
- 将 114514 插入到 contents 尾部
contents 仅支持升级不支持降级
由于 intset 采取连续空间存储数据,并且要求有序,因此,仅适用于 数据量较小 的情况(插入 O(n),查询 O(log(n)))
Skip List
Skip List,跳表,是 ZSET 的底层数据结构,支持在 O(log(n)) 内查找目标元素,并支持范围查询
Skip List 的结构如下:
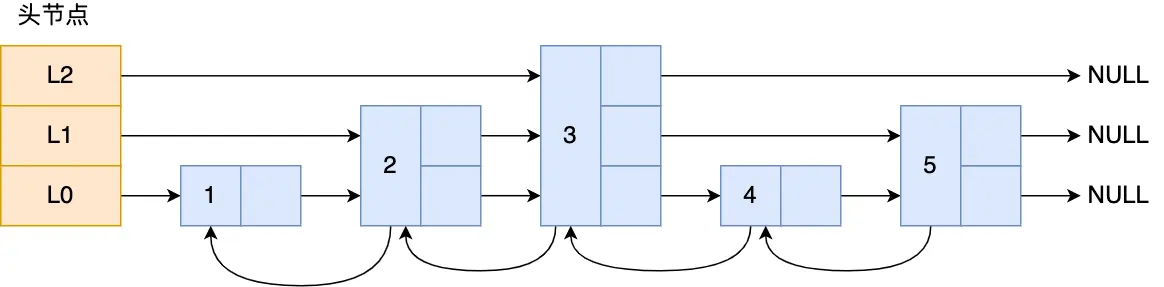
可以看到,Skip List 实际上就是一个 多层、 有序 链表
- 头节点保存了每一层的第一个 next 节点
- 子节点保存了:
- prev 指针
- 不同 level 的 next 指针
- value
来看看子节点的结构:
typedef struct zskiplistNode {
//Zset 对象的元素值
sds ele;
//元素权重值
double score;
//prev 指针
struct zskiplistNode *backward;
//节点的 level 数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
查询过程
- 一开始从最高的节点开始查询
- 将当前节点的 score 与目标 score 比较:
- 如果当前节点的 score 大于目标 score,那么继续向右遍历
- 如果当前节点的 score 小于目标 score,那么跳到 level - 1 层的 pre 节点,
- 如果当前节点的 score 等于目标 score,那么向右遍历直到 score 大于目标 score
举个例子:

假设要寻找的节点为 member: abcd, score:4:
- 从 L2 开始,遍历到节点
abc, 3 - 由于节点
abc, 3的权重小于 4,因此向右遍历 - 向右遍历,发现为 NULL,于是跳到 level - 1 的下一个节点,即
abcde, 4 - 由于节点
abcde, 4的权重等于 4,判断 member 是否一致 - 不一致,于是向左遍历到
abcd, 4,发现与目标节点一致,结束
可以看到整体思想也是基于二分
层数设置
跳表的查询效率与层数密切相关
- 如果层数太小,退化成链表,还是得一个一个遍历
- 如果层数太多,会占用不必要的空间,向下查询次数也会变多,效率也不高
建议 level[n - 1]的节点数 : level[n]的节点数 = 2 : 1,可以获得不错的查询效率
Redis 是如何维护比例为 2:1 的?
Redis 在创建节点时,并没有刻意的去保证比例为 2:1
在确定一个节点对应的 level 时,采取随机的策略,生成一个随机数:
- 如果随机数大于 0.25,那么 level++
- 否则 level 就确定下来
可以发现,越大的 level,对应越低的概率:
- 100% 的节点的 level 为 0
- 50% 的节点的 level 为 1
- 25% 的节点的 level 为 2
- 12.5% 的节点的 level 为 3
- …
这样就近似保证了 level[n - 1]的节点数 : level[n]的节点数 = 2 : 1
在 Redis7.0 中,level 的上限确定为 32
为什么不用 Red-Blank Tree
看看作者的解释:
There are a few reasons:
They are not very memory intensive. It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
具体来说:
- 相较于 AVL 树、红黑树,SkipList 在存储相同数据的情况下,占用的内存更少
- 相较于 AVL 树、红黑树,SkipList 在范围查询时,数据的访问更加连续,可以更好的利用缓存,性能不比 AVL 树、红黑树、B 树差
- 相较于 AVL 树、红黑树,SkipList 的维护性更好,实现简单,插入删除数据时,不需要太多操作
数据结构(APIs)
在将数据结构前,先来了解一个概念
Redis 无论什么数据结构,都被封装成了一个 Redis Object
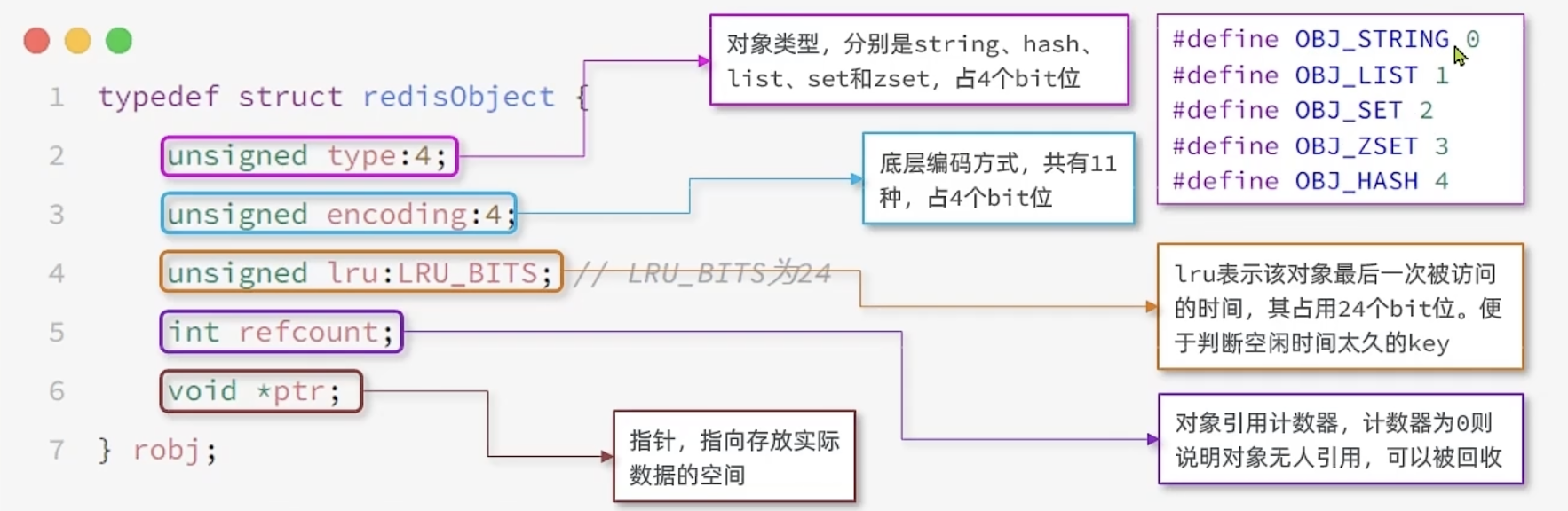
每个 Object 都有自己的 编码方式,决定了底层使用什么样的数据结构
String
String 可以说是 Redis 使用最多的数据结构了
String 的编码方式如下:
- 当 String 存储的是整数数据,采用 INT 编码方式,直接存储一个整数,支持 Incr 操作
- 当 String 存储的是字符串:
- 如果整个 Object 占的空间小于 64 字节(即 str 部分为 64 - 4 - 4 - 8 = 44 字节)时,采取 EMBSTR 编码方式
- 否则,采用 RAW 编码方式
EMBSTR 编码方式与 RAW 编码方式都是基于 SDS 的,区别在于:EMBSTR 的数据部分与头部部分为一个连续的空间,只需要一次内存分配;而 RAW 需要两次分配
应用场景
String 的应用场景很多,这里就说一下 Session 存储
如果直接将 Session 存放在单个服务端,那么用户请求到另一个的服务端,就无法验证 Session 的正确性
可以以 uid 为 key,session 为 val,存在 Redis 中,这样服务端直接请求 Redis 即可
List
实现原理
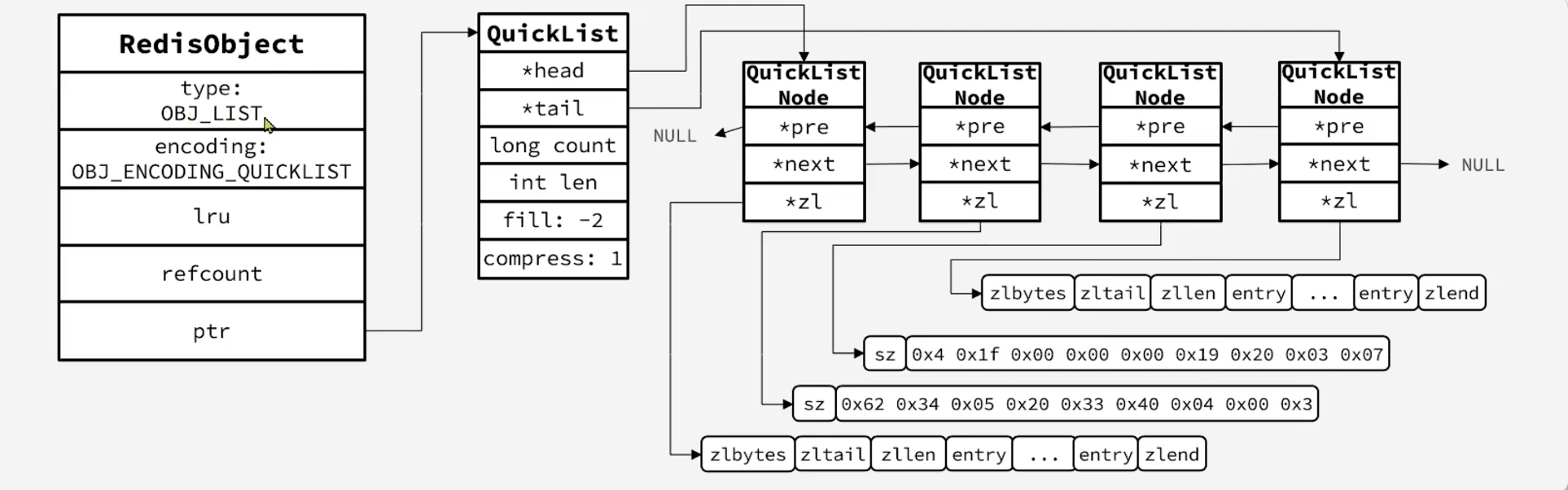
List 的编码方式:
- 3.2 版本前:
- 如果存储的数据节点小于 512 个并且占用空间小于 64K,采取 ZipList 编码
- 否则,采取 List 编码
- 3.2 版本后:采取 QuickList 编码
应用场景
List 可以高效的在首尾增加和删除数据,适合用作 消息队列
但是 List:
- 不支持消费者组
- 不支持消息重放
- 没有维护消费的 offset
Stream
为了解决 List 的缺陷,Redis 5.0 引入了 Stream
实现原理
Stream 底层基于 Radix Tree 和 ListPack 实现
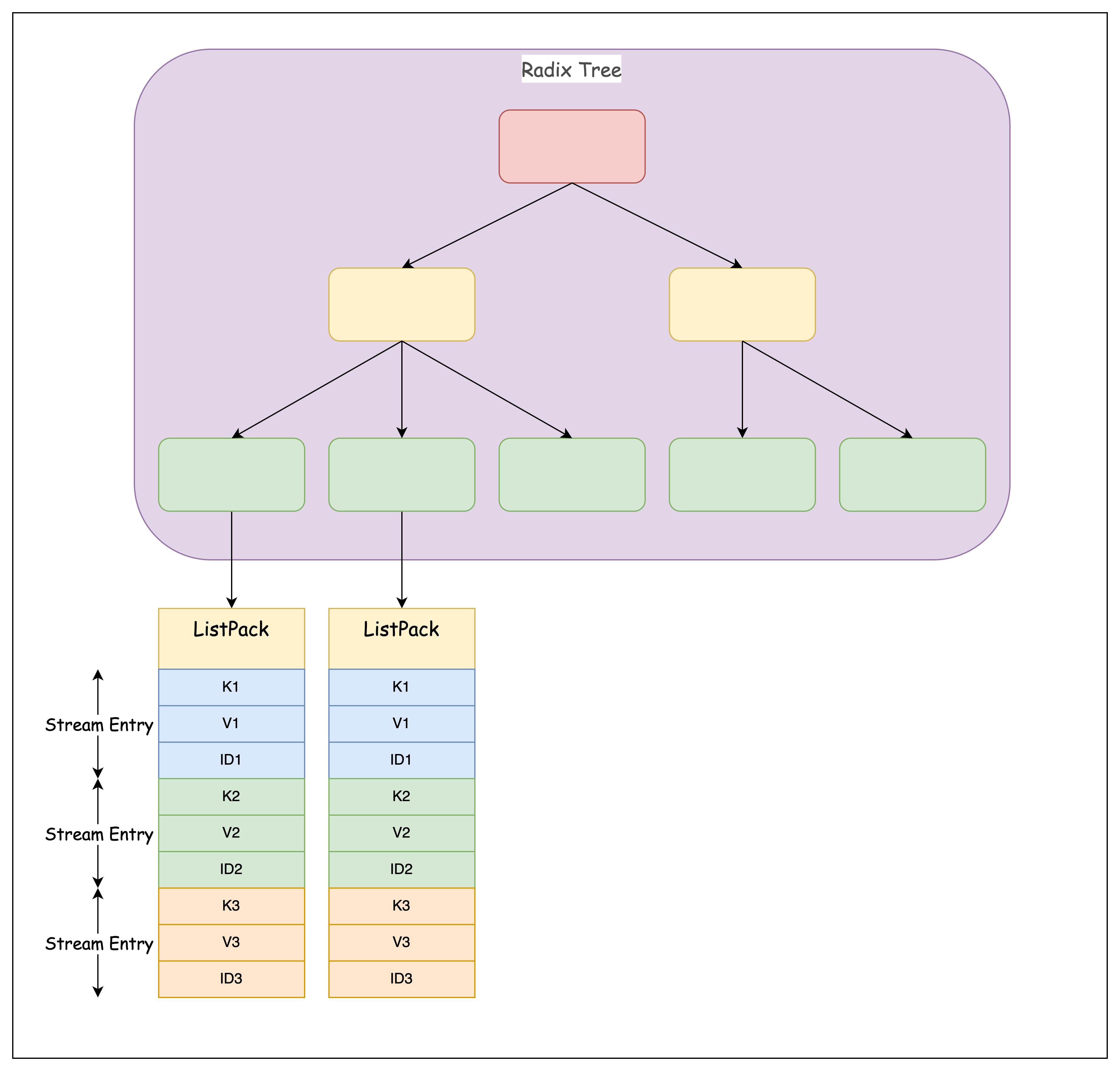
每一个 Stream Entry 包含了三个部分:
- 全局唯一 id:如果没有指定消息 id,Redis 会自己生成一个分布式 id
- key
- value
生产一条消息后,如果可以将新的消息放在 ListPack 中(即 ListPack 有空闲位置),就直接存放,否则,创建一个新的 ListPack,并将 ListPack 的 id 存在 Radix Tree 中
Radix Tree 的键是 Stream Entry 的 ID,值是对应的 Listpack,Radix Tree 可以根据提供的消息 id,快速定位到 ListPack,进而定位到 Stream Entry 的位置
API
- XADD:插入消息,保证有序,可以自动生成全局唯一 ID;
- XLEN :查询消息长度;
- XREAD:用于读取消息,可以按 ID 读取数据;
- XDEL : 根据消息 ID 删除消息;
- DEL :删除整个 Stream;
- XRANGE :读取区间消息
- XREADGROUP:按消费组形式读取消息;
- XPENDING 和 XACK:
- XPENDING 命令可以用来查询每个消费组内所有消费者「已读取、但尚未确认」的消息;
- XACK 命令用于向消息队列确认消息处理已完成
概念抽象
- Stream Entry:类似于 Message
- Stream Key:即 Stream 的 key,类似于 Partition
消费者组
与 Kafka 不同,Redis 的消费者组消费的是同一个 key,即同一个 Partition
也就是说,多个消费者消费同一个 Partition,这在 Kafka 是不允许的(存在重复消费的问题)
但 Redis 保证:一条 message,只能由 Consumer Group 中的一个 consumer 消费,没有重复消费的问题
Consumer groups in Redis streams may resemble in some way Kafka (TM) partitioning-based consumer groups, however note that Redis streams are, in practical terms, very different. The partitions are only logical and the messages are just put into a single Redis key, so the way the different clients are served is based on who is ready to process new messages, and not from which partition clients are reading. For instance, if the consumer C3 at some point fails permanently, Redis will continue to serve C1 and C2 all the new messages arriving, as if now there are only two logical partitions.
简单来说,Redis 流中的消费者组消费消息的方式与 Kafka 不同。在 Kafka 中,消息被存储在不同的分区中,消费者组中的每个消费者负责消费特定分区的消息。而在 Redis 流中,消息被存储在一个键中,消费者组中的消费者 通过竞争 获取消息的消费权。如果一个消费者失败,其他消费者将继续消费新消息,而不会受到分区分配的影响。
消息持久化
Stream 的持久化依赖于 RDB 和 AOF
在业务中使用 Stream,需要格外注意 AOF 的刷盘策略
如果要保证消息 尽量 不丢,就要让 AOF 刷盘策略严格一些
Redis 可以通过配置文件或运行时命令来控制 AOF(Append Only File)文件的 fsync 参数。
在 Redis 的配置文件(redis.conf)中,可以使用 appendfsync 配置项来设置 AOF 文件的 fsync 策略。该配置项有以下三个可选值:
always:每次写入 AOF 文件时都会执行 fsync 操作,将数据写入磁盘。这种策略可以确保数据的持久性,但可能会降低性能。everysec:每秒钟执行一次 fsync 操作,将数据写入磁盘。这种策略可以确保数据的持久性,同时避免频繁的磁盘操作对性能的影响。no:不执行 fsync 操作,将数据写入内存,而不是磁盘。这种策略可以提高性能,但可能会导致数据丢失。
消息有序性保障
来看一下 Redis 官方的解释:
We could say that schematically the following is true:
- If you use 1 stream -> 1 consumer, you are processing messages in order.
- If you use N streams with N consumers, so that only a given consumer hits a subset of the N streams, you can scale the above model of 1 stream -> 1 consumer.
- If you use 1 stream -> N consumers, you are load balancing to N consumers, however in that case, messages about the same logical item may be consumed out of order, because a given consumer may process message 3 faster than another consumer is processing message 4.
也就是说,要想保证消息消费顺序与 producer 生产顺序一致,那么 一个 Stream 就只能对应一个 Consumer
与 Kafka 的对比
Redis Stream 与 Kafka 等专业消息队列,最主要的差距就在于:
- 消息可靠性(保证不丢)
- 消息是否可堆积
对于 Redis Stream 来说,无法保证 消息的可靠性:
- AOF fsync 过程宕机
- 主从复制是异步的,存在丢失数据的风险
并且,由于 Redis 将数据存储在内存,决定了无法堆积太多消息
详细可以看看 Redis 官方文档
Hash
实现原理
编码规则:
- 如果存储的数据节点小于 512 个并且占用空间小于 64K,采取 ZipList 编码
- 否则,采取 Dict 编码
在 Redis7.0 版本,废弃了 ZipList,采用 ListPack
应用场景
可以使用 hash 表存储对象,例如,要存储 user 对象,可以以 user_id 为 key,序列化以后的 user 为 value
Set
实现原理
编码方式:
- 如果元素数量小于 512 个,并且全是整数,使用 IntSet 编码
- 否则,使用 Dict 编码
应用场景
点赞场景,例如:
- 记录一个文章有哪些用户点过赞,可以以 post_id 为 key,user_id 为 member
- 记录一个用户给哪些评论点过赞,可以以 user_id 为 key,comment_id 为 member
共同关注,例如:
- 计算用户共同关注的公众号,可以以 公众号 id 为 key,user_id 为 member,然后求交集
Sorted Set
实现原理
编码方式:
- 如果元素个数小于 128 个,并且占用空间小于 64 字节时,使用 ZipList 编码
- 否则,使用 Dict + SkipList 编码
这里使用哈希表的目的是为了保存:member 到 score 的映射关系,可以快速获取一个 member 的 score,即 ZSCORE API
应用场景
Sorted Set 主要的应用场景就是排序了,例如排行榜功能
BitMap
实现原理
BitMap 使用 SDS 来存储数据,具体来说,是利用 SDS 的 value 属性
BitMap 提供了以下 API:
# 设置值
SETBIT key offset value
# 获取值
GETBIT key offset
# 获取指定范围内值为 1 的个数
# start 和 end 以字节为单位
BITCOUNT key start end
# result 计算的结果,会存储在该key中
# key1 … keyn 参与运算的key,可以有多个,空格分割,not运算只能一个key
# 当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0。返回值是保存到 destkey 的字符串的长度(以字节byte为单位),和输入 key 中最长的字符串长度相等。
BITOP [operations] [result] [key1] [keyn…]
# 返回指定key中第一次出现指定value(0/1)的位置
BITPOS [key] [value]
应用场景
BitMap 非常适合用于统计二值的场景(即 true or false),例如:
- 用户签到表:以 user_id 为 key,day 为 offset,365 天的签到表,仅会占用约 60 字节的空间
- 用户在线表:以 user:online 为 key,user_id 为 offset,如果 user_id 从 1 开始,5000w 用户仅会使用 6M 空间
HyperLogLog
HyperLogLog 是一种高效的数据结构,用于 估计 集合的大小,即估算集合中元素的数量。HyperLogLog 的优点是 空间复杂度低,时间复杂度为 O(1),并且可以处理非常大的集合。
HyperLogLog 的误差通常为 0.81%
HyperLogLog 的原理是利用概率算法,通过比较概率分布来估算集合的大小。具体来说,HyperLogLog 会维护一个长度为 m 的窗口,用于存储输入序列中的元素。对于每个元素,HyperLogLog 会计算其与前 m 个元素的相似度,并根据相似度计算其概率。然后,HyperLogLog 会根据概率计算该元素在集合中的大小,并更新窗口。最后,HyperLogLog 会根据窗口中的元素数量估算集合的大小。
APIs
- PFADD:将一个或多个元素添加到 HyperLogLog 中。
PFADD myhll element1 element2 ... - PFCOUNT:获取 HyperLogLog 中的基数估计值。
PFCOUNT myhll - PFMERGE:合并多个 HyperLogLog 结构为一个,用于估计多个集合的联合基数。
PFMERGE dest-hll source-hll1 source-hll2 ...
应用场景
HyperLogLog 适合大量 计数,且 对数据精度要求不高 的场景,例如:网页的 UV 统计、用户活跃度
Geospatial
Redis 中的 Geospatial 数据类型是一种用于存储地理空间信息的数据结构,允许存储地理位置(经度和纬度)以及与这些位置相关的其他数据(例如,商家名称、城市名称等)。
APIs
-
GEOADD:将一个或多个地理位置成员添加到指定的有序集合中。
GEOADD locations 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania" -
GEODIST:计算两个地理位置之间的距离。
GEODIST locations "Palermo" "Catania" km -
GEOPOS:获取一个或多个地理位置成员的经度和纬度。
GEOPOS locations "Palermo" "Catania" -
GEORADIUS:根据指定的地理位置和半径,返回范围内的成员。
GEORADIUS locations 15 37 200 km -
GEORADIUSBYMEMBER:根据指定的地理位置成员和半径,返回范围内的成员。
GEORADIUSBYMEMBER locations "Palermo" 200 km
实现原理
Geo 实际上是对 Sorted Set 的进一步封装,以:
- place_name 为 key
经度与纬度键值对为 value
基于此,就不难理解 Geo 的 APIs 的实现了
应用场景
Geo 的应用场景有:
- 位置服务:Geo 可以用来提供位置服务,如查找附近的人、查找附近的店铺等。
- 推荐系统:Geo 可以用来进行推荐系统,如根据用户的位置信息推荐附近的店铺、景点等。