Redis 事务
Redis 事务是一个 原子操作,但不具备传统意义上的原子性
基本使用
redis 的事务与传统关系性数据库的事务不同,没有 ACID 特性
- 开启事务可以使用
MULTI命令 - 回滚事务可以使用
DISCARD命令 - 提交事务可以使用
EXEC命令
为了防止多客户端的并发修改,可以在开启事务前使用 WATCH 命令监视要修改的键
WATCH 命令用于监视一个或多个键,如果被监视的键在事务执行前被其他客户端修改,当前事务将被中止。
WATCH 实际上是一种 乐观锁 机制
局限性
- 不支持回滚
- 客户端与 Server 交互,是一条一条,而不是一批一批
Redis 事务支持回滚吗?
- 若在事务队列中存在命令格式错误(类似于 java 编译性错误),则执行 EXEC 命令时,所有命令都不会执行
- 若在事务队列中存在其它错误(如网络错误、Redis 服务器本身出现问题、OOM),则执行 EXEC 命令时,所有命令都会执行,只不过部分成功,部分失败
因此,Redis 事务 不支持回滚,第一种情况只是看起来像回滚,但这实际上是代码编写的问题,当然可以“回滚”,不在本次问题的讨论范围
为什么不支持回滚?
Redis 官方 是这样说的:
Redis does not support rollbacks of transactions since supporting rollbacks would have a significant impact on the simplicity and performance of Redis.
Redis commands can fail only if called with a wrong syntax
简单来说,就是 Redis 认为没有必要实现回滚,破坏了 Redis 的简单性,对性能也有显著影响
此外,Redis 认为:Redis 的命令只会在出现语法错误的情况下,执行失败,这种错误是可以在开发的时候发现的,也没有必要实现回滚
当然,错误的发生还有一种情况:事务执行过程中,Redis Server 宕机了,这种情况下,会出现事务执行了一半的情况吗?可以看看这个 讨论
Redis 本身就是用作缓存的,搞这么复杂干嘛
如果你把 Redis 用作缓存,那么更新数据时,完全可以把缓存删掉(如果删除失败,可以引入补偿机制),不需要回滚的支持
Redis 事务具有原子性嘛?
Either all of the commands or none are processed, so a Redis transaction is also atomic.
Redis 官方认为:原子性指的是:一组命令,要么全部执行,要么全部不执行
那么从这个角度来看,Redis 事务是 具有原子性的,在命令本身没有语法错误的情况下:
- 执行 EXEC,命令 全部执行
- 执行 DISCARD,命令 全部不执行
维基百科认为 原子性 的定义是:一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。
从上面提到的 讨论 ,可以发现:一个事务执行过程中,如果 Redis 宕机,导致 AOF Log 事务部分不完整(被截断),那么 Redis 在重启时应用日志时会发现这个问题,并跳过整个事务执行部分
如果我们认为事务执行过程中,唯一可能出现的错误就是 Redis 宕机(这符合 Redis 官方 的说法),那么,Redis 事务就满足维基百科定义的「执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态」
当然,在实际使用过程中,可能会有其它因素(例如 OOM)导致一条命令执行失败,而不仅仅是宕机
因此,这里给出的答案是:Redis 事务:
- 具有 提交原子性:事务中的所有命令在一起提交,如果 EXEC 成功,则所有命令按顺序依次执行
- 执行 非原子性:事务中的每个命令独立执行,某个命令失败不会回滚之前已经成功执行的命令
总结
- Redis 的事务是 原子操作,即在事务执行过程中,不会被其它事务干扰
- Redis 事务不具备 CI 性质,这意味着多个事务之间是 没有隔离性 的,如果要保证多个事务之间的一致性和隔离性,需要利用 WATCH 乐观锁
- Redis 事务成功提交后不支持回滚
- 如果事务执行过程中,Redis 宕机了,重启后会「回滚」到事务执行前的状态
- Redis 事务满足 提交原子性,不满足执行原子性
Redis 性能优化
批量发送数据
传统的 C/S 交互方式,通常是:
- Client 发一条消息,等待
- Server 接收到一条消息,处理
- Server 将结果返回给客户端
在这种交互方式下,一条命令,在 Server 端就需要一次 read syscall 和一次 write syscall
一条命令的情况还好,但是如果是很多命令,频繁的 syscall,会带来很大的开销
可以想到的一种优化方式是 一次性发送一批数据
在 Redis 中,经常使用 pipeline 来批量发送命令。在这种机制下,客户端发送完一条命令后,不是等待,而是接着发送第二条
这样,在 Server 端,调用一次 read,就可以读取很多命令,调用一次 write,就可以发送很多响应,节省了很多系统调用的开销
Pipelining is not just a way to reduce the latency cost associated with the round trip time, it actually greatly improves the number of operations you can perform per second in a given Redis server. This is because without using pipelining, serving each command is very cheap from the point of view of accessing the data structures and producing the reply, but it is very costly from the point of view of doing the socket I/O. This involves calling the read() and write() syscall, that means going from user land to kernel land. The context switch is a huge speed penalty.
When pipelining is used, many commands are usually read with a single read() system call, and multiple replies are delivered with a single write() system call.
Redis 认为,因为高效的数据结构,以及内存操作,Redis Server 执行命令的过程开销实际上不是很大,真正昂贵的操作是频繁的 read/write syscall
transaction、pipeline、lua 三者区别
transaction 与 pipeline
- 事务是原子操作,pipeline 是非原子操作。两个不同的事务不会同时运行,而 pipeline 可以同时 以交错方式 执行。
- Redis 事务中每个命令都需要发送到服务端,而 Pipeline 只需要发送一次,请求次数更少。
这里做了一个小实验,验证 pipeline 是不是原子操作:
先来看代码:
package main
import (
"context"
"fmt"
"strconv"
"sync"
"github.com/redis/go-redis/v9"
)
func main() {
// InitRedis()
var wg sync.WaitGroup
wg.Add(100)
for i := 0; i < 100; i++ {
rdb := redis.NewClient(&redis.Options{
Addr: "127.0.0.1:6379",
Password: "",
DB: 0,
})
pipe := rdb.Pipeline()
// pipe := rdb.TxPipeline()
key := "key" + strconv.Itoa(i)
go func() {
defer wg.Done()
for i := 0; i < 1000; i++ {
value := "value" + strconv.Itoa(i)
pipe.Set(context.TODO(), key, value, -1)
}
_, err := pipe.Exec(context.TODO())
if err != nil {
fmt.Println(err.Error())
}
}()
}
wg.Wait()
}
查看 aof 文件:
*4
$3
set
$5
key18
$6
value0
$7
keepttl
...
可以发现一个 set 命令占了 9 行
假设 pipeline 是原子操作,那么 1000 个命令应该占用 9000 行,那么是不是这样呢?
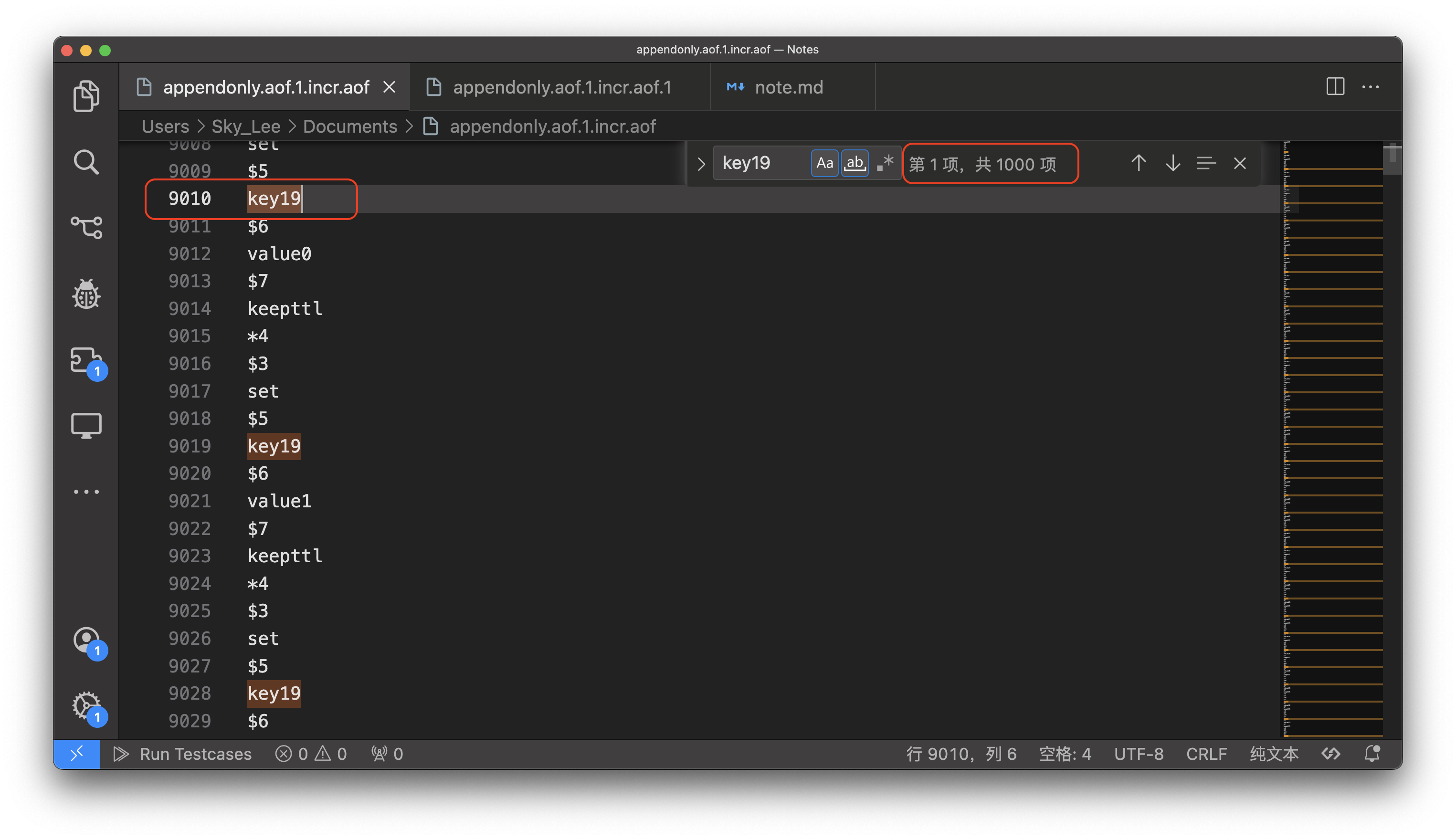
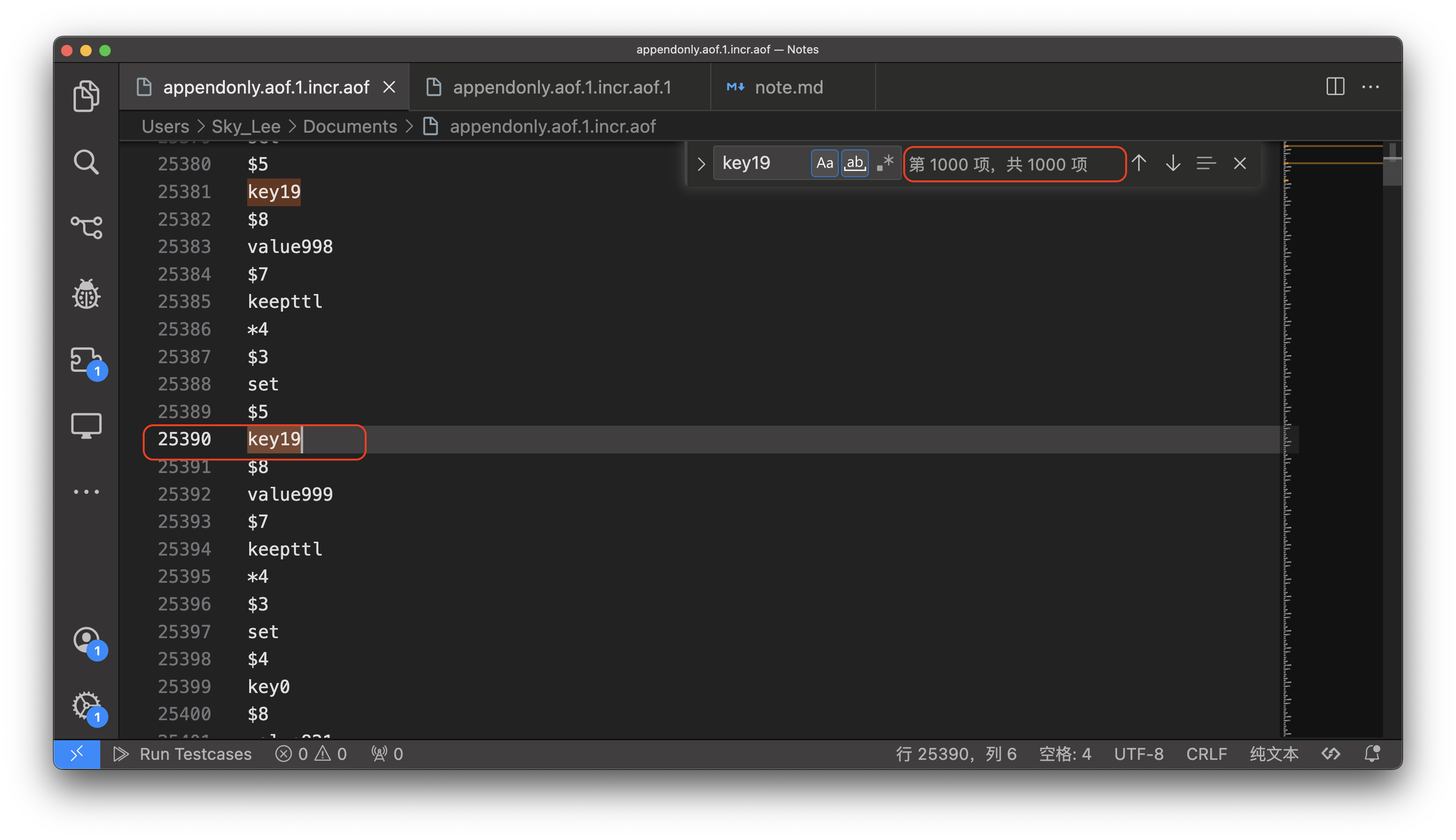
可以发现,从起始位置到结束位置之间的行数远大于 9000 行,说明 pipeline 不是原子操作
那 Redis 事务是不是原子操作呢?这里使用 TxPipeLine API 来验证:
pipe := rdb.TxPipeline()
结果如下:
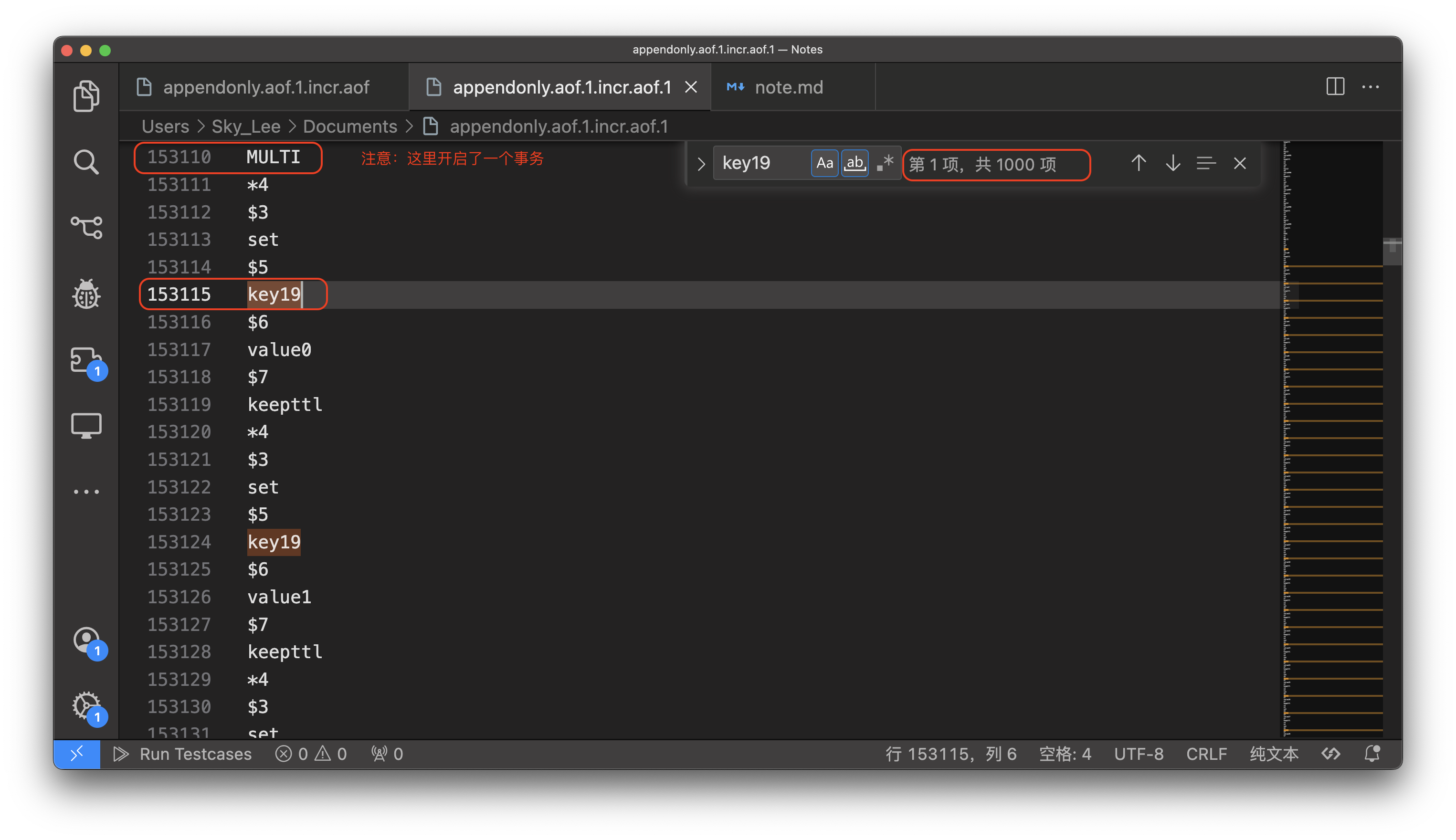
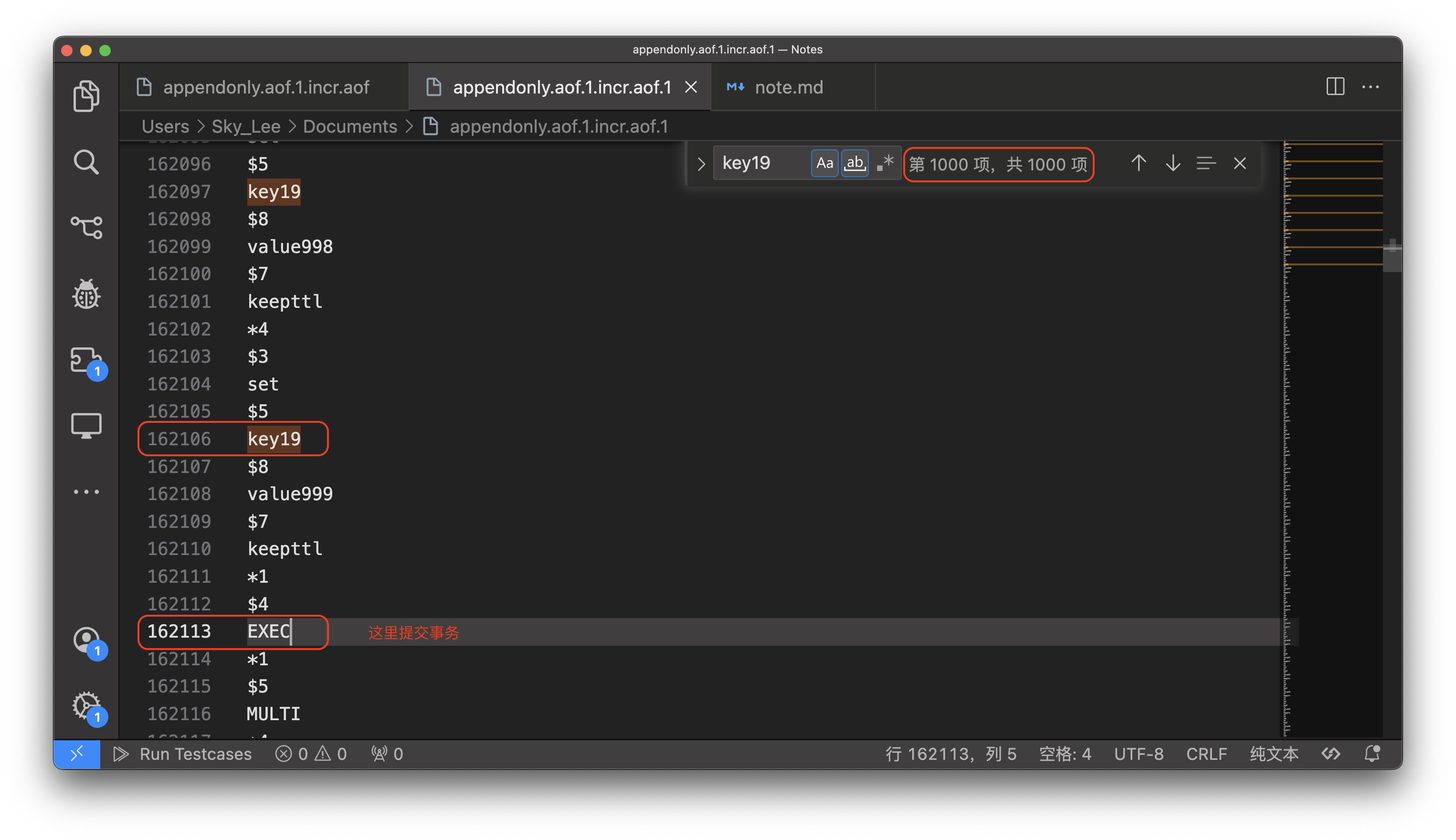
可以发现,使用事务以后,开始到结束位置的行数确实为 9000 行,说明事务是 原子操作
Redis 事务是怎么保证操作是原子的?
当开启一个事务以后,接下来的所有操作都会被放到一个「独立」的队列中
当调用 EXEC 命令时,Redis 会单线程地处理队列中所有的命令,只有当前事务的命令处理完毕以后,才会处理其它事务的命令
而 PipeLine 实际上是一种 网络优化的手段,只是批量的发送数据到 Redis Server,没有隔离保障,其它客户端的数据可能与 pipeline 的数据混在一起
pipeline 与 lua 脚本
Using Redis scripting, available since Redis 2.6, a number of use cases for pipelining can be addressed more efficiently using scripts that perform a lot of the work needed at the server side. A big advantage of scripting is that it is able to both read and write data with minimal latency, making operations like read, compute, write very fast (pipelining can’t help in this scenario since the client needs the reply of the read command before it can call the write command).
当涉及到需要快速执行并且依赖于前一个命令输出的场景时,Redis 脚本比管道更高效。例如,如果你需要读取一个键的值,基于这个值做一些计算,然后将结果写回到数据库,使用 Lua 脚本会是一个非常快速的解决方案。整个读取、计算和写入的过程在 Redis 服务器上作为一个单独、原子性的操作执行,客户端只需要发送脚本并接收最终结果。
此外,lua 脚本在服务端执行,可以保证原子操作,这也是 pipeline 做不到的
补充:如何在 Redis 中使用 lua 脚本?
在 Redis 中使用 Lua 脚本的步骤相对简单。Redis 内置了对 Lua 脚本语言的支持,这使得你可以在 Redis 服务器上执行原子操作的复杂逻辑。Lua 脚本在 Redis 服务器端运行时,可以保证脚本内的多个命令作为原子操作执行,不会被其他客户端的命令中断。
以下是在 Redis 中使用 Lua 脚本的具体步骤:
编写 Lua 脚本
首先你需要编写 Lua 脚本。一个简单的例子如下,这个脚本会检查一个键是否存在,如果不存在,则设置它的值:
if redis.call("EXISTS", KEYS[1]) == 0 then
redis.call("SET", KEYS[1], ARGV[1])
return "Key was set"
else
return "Key already exists"
end
使用 EVAL 命令执行 Lua 脚本
使用 EVAL 命令将 Lua 脚本发送至 Redis 服务器执行。EVAL 命令的第一个参数是 Lua 脚本的文本,第二个参数指定了脚本中的KEYS数组参数的个数,后续的参数是被脚本使用的 Redis 键和附加的参数。
以前面的 Lua 脚本示例为例,你可以这样调用:
EVAL "if redis.call('EXISTS', KEYS[1]) == 0 then redis.call('SET', KEYS[1], ARGV[1]) return 'Key was set' else return 'Key already exists' end" 1 your-key your-value
这里:
your-key是 Lua 脚本中KEYS[1]的值。your-value是 Lua 脚本中ARGV[1]的值。- 数字
1指的是脚本中只访问一个键。
使用 EVALSHA 命令执行预加载的脚本
如果你多次执行同一脚本,可以先使用 SCRIPT LOAD 命令加载脚本到 Redis 服务器并获取返回的 SHA1 校验和。之后可以通过 EVALSHA 命令和这个 SHA1 校验和来执行脚本,而不是每次都传输整个脚本代码:
EVALSHA sha1-checksum 1 your-key your-value
总结
- Redis 认为的原子性:一批操作,要么 执行,要么 不执行,且不会被其他客户端的命令中断
- Redis 事务是一个原子操作,不支持回滚,不具备关系型数据库的原子性
- pipeline(管道)更像是一种网络 IO 的优化手段,操作不具备原子性
- lua 脚本结合了 Redis 事务与 pipeline 的优点,操作具备原子性,并且网络 IO 开销很低
bigkey 优化
bigkey 对 Redis 的影响主要在:
- RDB 持久化、AOF 重写:fork 时间会变长,阻塞 Redis 服务
- 网络 IO:假设一个 bigkey 的 value 大小为 1M,QPS 为 1k,那么 1s 产生的流量为 1G,直接把千兆网卡打满
- 删除操作:删除一个 bigkey,在内存还给 OS 后,OS 要对空闲内存管理,即将对应的页放到 free_list 中,如果页太多,这个过程也会比较耗费性能
如何优化?
- 尽量不用 bigkey
- 如果要用,可以将其拆分成若干个子 key
- 删除时,不直接用 DEL,而是用 UnLink 异步删除,或者分批次删除
DEL 是一个阻塞操作,而 UnLink 只是将 key 从哈希表中移除(unlink),真正释放内存的操作是另外一个线程去 异步 地操作的,不会阻塞 Redis 的服务
This command is very similar to DEL: it removes the specified keys. Just like DEL a key is ignored if it does not exist. However the command performs the actual memory reclaiming in a different thread, so it is not blocking, while DEL is. This is where the command name comes from: the command just unlinks the keys from the keyspace. The actual removal will happen later asynchronously.
hotkey 优化
热点 key 指的是 QPS 相对整个 keyset 来说较高的 key,如果不对热点 key 妥善处理,很有可能因为频繁访问将 Redis 服务干掉
常见的优化方式:
- 读写分离:可以部署多个从节点来分摊主节点的读压力
- Redis Cluster:集群模式,保障可用性
- 多级缓存:应用程序可以实现自适应热点发现,将热点数据缓存到本地,避免访问 Redis
内存碎片问题
内存碎片这个问题并不陌生,在 OS 的内存管理就有遇到这个问题
在 Redis 中也有内存碎片的问题,发生的原因主要有两种:
申请内存,并不是按需申请
To store user keys, Redis allocates at most as much memory as the maxmemory setting enables (however there are small extra allocations possible).
在申请 size 大小的内存时,通常还要额外申请一小部分内存,这不难理解:如果接下来要使用,就不需要在分配一次内存,直接用就可以(这个思想在 malloc 中也有体现)
当然,如果接下来要申请的内存空间大于预分配的内存,那还是要申请的,这部分内存就成为了内存碎片(当然只要申请的内存小于等于某一块碎片,还是可以用的)
释放内存,并不是立即释放
Redis will not always free up (return) memory to the OS when keys are removed. This is not something special about Redis, but it is how most malloc() implementations work. For example, if you fill an instance with 5GB worth of data, and then remove the equivalent of 2GB of data, the Resident Set Size (also known as the RSS, which is the number of memory pages consumed by the process) will probably still be around 5GB, even if Redis will claim that the user memory is around 3GB. This happens because the underlying allocator can’t easily release the memory. For example, often most of the removed keys were allocated on the same pages as the other keys that still exist.
这是因为删除的 key 所在的内存页,可能还有其它 key 的数据,那么这些页就不能归还给 OS
如果这些页无法得到利用,就成为了内存碎片
如何解决
在 Redis 中,可以执行 info memory 查看内存使用情况
root@a6950a95dd7a:/data/appendonlydir# redis-cli -p 6379
127.0.0.1:6379> info memory
# Memory
used_memory:1546648
used_memory_human:1.47M
used_memory_rss:4300800
used_memory_rss_human:4.10M
...
mem_fragmentation_ratio:2.82
mem_fragmentation_bytes:2774824
mem_not_counted_for_evict:640
mem_replication_backlog:0
...
其中 mem_fragmentation_ratio 的值可以反映内存碎片的情况
mem_fragmentation_ratio = used_memory_rss (操作系统实际分配给 Redis 的物理内存空间大小)/ used_memory(Redis 内存分配器为了存储数据实际申请使用的内存空间大小)
因此,mem_fragmentation_ratio 越大,说明碎片率越高
当 mem_fragmentation_ratio > 1.5 就可以考虑做碎片整理了
mem_fragmentation_ratio 小于 1 是什么情况?
这说明 Redis 实际使用的内存量大于 OS 分配给 Redis 的内存,通常来说是因为内存不足,发生了 swap
启用碎片整理
#
# 1. This feature is disabled by default, and only works if you compiled Redis
# to use the copy of Jemalloc we ship with the source code of Redis.
# This is the default with Linux builds.
#
# 2. You never need to enable this feature if you don't have fragmentation
# issues.
#
# 3. Once you experience fragmentation, you can enable this feature when
# needed with the command "CONFIG SET activedefrag yes".
#
# The configuration parameters are able to fine tune the behavior of the
# defragmentation process. If you are not sure about what they mean it is
# a good idea to leave the defaults untouched.
# Enabled active defragmentation
# activedefrag no
# Minimum amount of fragmentation waste to start active defrag
# active-defrag-ignore-bytes 100mb
# Minimum percentage of fragmentation to start active defrag
# active-defrag-threshold-lower 10
# Maximum percentage of fragmentation at which we use maximum effort
# active-defrag-threshold-upper 100
# Minimal effort for defrag in CPU percentage, to be used when the lower
# threshold is reached
# active-defrag-cycle-min 1
# Maximal effort for defrag in CPU percentage, to be used when the upper
# threshold is reached
# active-defrag-cycle-max 25
Redis 默认关闭了碎片整理,因为这个功能只有在使用 Jemalloc 分配内存才有效,并且碎片整理需要耗费一定性能
Redis 生产问题
缓存雪崩、击穿、穿透与缓存一致性
可以查看 这篇文章
常见阻塞情况
- RDB 持久化,AOF 重写时的 fork
- RDB 持久化,AOF 重写时的「写时拷贝」
- AOF 的刷盘(fsync)
- bigkey 的修改
- bigkey 的删除
- 慢查询
- 内存淘汰
- Redis Server 压力大
- 主从复制:主进程需要将 RDB 快照发送给从节点,发送过程在其它客户端看来,Redis 服务是阻塞的
- 故障转移:在故障转移的过程中,写操作可能阻塞