缓存雪崩
缓存雪崩指的是大量 key 几乎同时过期,导致大量请求直接打到 DB,导致 DB 服务不可用,进而导致其它服务也不可用,就像雪崩一样
应对方式
给 Key 指定过期时间时,加上一个随机数
例如,对于 comment:likeset: 这一类 key 来说,假设预期过期时间为 120s,那么在设置 key 的 TTL 时,就可以在 120s 的基础上 +- 一个随机数,使得过期时间有略微偏差,不至于同时过期
缓存击穿
缓存击穿指的是热点 key(即访问很多的 key)过期,导致大量请求直接打到 DB,导致 DB 服务不可用,进而导致其它服务也不可用
缓存击穿是缓存雪崩的 子集
应对方式
除了缓存雪崩的应对方式外,对于缓存击穿,还可以使用「互斥锁」来应对
具体来说,读取数据时,先判断缓存是否过期,如果过期:
- 加锁
- 再次判断缓存是否过期:
- 如果过期,读 DB,重建缓存
- 否则,读缓存
- 解锁
这样,就只有一个线程真正执行了读 DB 的操作
例如,在 Go 的并发编程中,常常使用 singleflight 来防止缓存击穿
缓存穿透
缓存穿透指的是请求 不存在的数据,由于数据不存在,必然 cache miss,导致请求直接打到 DB
如果有恶意请求,随机生成一些 query condition,那么大量的请求打到 DB,导致 DB 服务不可用,进而导致其它服务也不可用
应对方式
通常有两种方式防止缓存穿透:
- 缓存空对象
- 布隆过滤
缓存空对象的思想是:如果访问了一个不存在的数据,那么将这个查询条件缓存起来,下一次请求就先判断数据是否存在,存在才访问 Cache、DB
这种方式无法解决恶意请求的问题,因为查询条件是随机的
布隆过滤器可以将存在的对象「放到」过滤器中,查询时,先根据布隆过滤器判断数据是否存在,存在才访问 Cache、DB
那么,如果将一个对象放到布隆过滤器中?
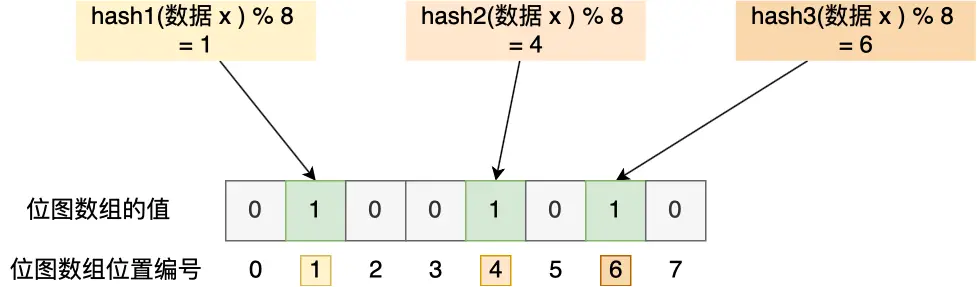
事实上:布隆过滤器使用了 位图 + hash function:
- 先使用「多个」不同的哈希函数计算对象的哈希值
- 计算存储到位图的位置:
hash_val % sizeof(bitmap)
在判断数据是否存在时:
- 使用「多个」不同的哈希函数计算对象的哈希值
- 计算存储到位图的位置:
hash_val % sizeof(bitmap) - 如果每一个位置都在位图中存在,那么认为这个对象存在,否则认为不存在
布隆过滤存在 误判 的可能,因为存在哈希冲突,不同对象可以有相同的哈希值
举个例子:
- 对象 A 的哈希值为 1、2、3
- 对象 B 的哈希值为 2、3、4
- 对象 C 的哈希值为 1、2、4
假设 A、B 在 DB 中存在,C 不存在,且位图的大小为 4
那么根据哈希值,可以得到位图为 1、2、3、4
由于 C 的哈希值为 1、2、4,每一位都在位图中存在,因此,布隆过滤器认为 C 存在,这就产生了误判
为了降低误判几率,可以增加哈希函数的数量,以及位图的大小