介绍
Redis 主从复制(同步)是指将一个 Redis 服务器的数据复制(同步)到多个 Redis 服务器的过程。这样,当主服务器出现故障时,其他从服务器可以接管其工作,从而保证服务的稳定性。
第一次同步的过程
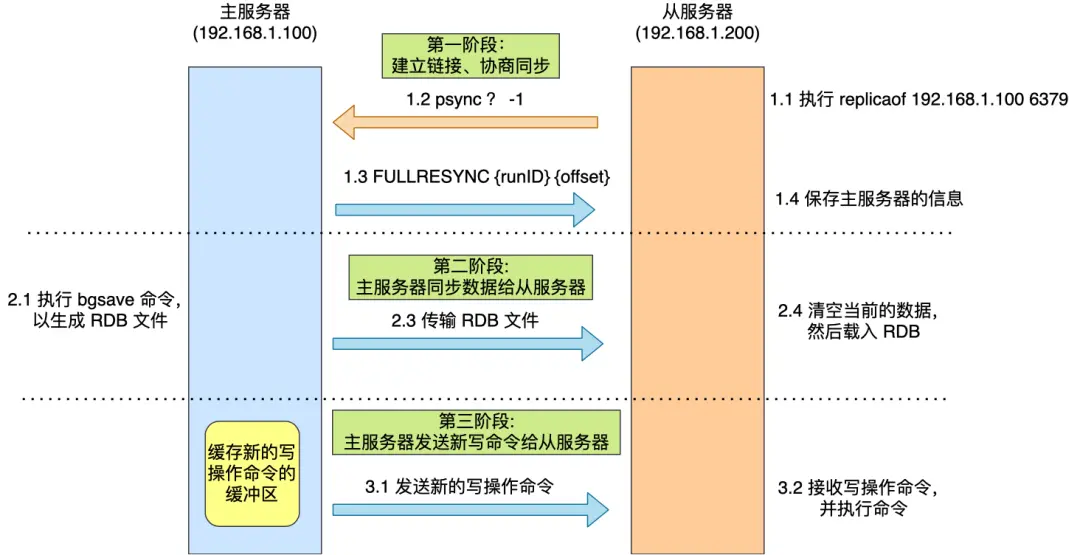
从节点第一次同步主节点的数据的过程如下:
- 从节点向主节点发起同步请求(PSYNC),并携带主服务器的 server_id(这里为?)、offset(这里为 -1)
- 主节点收到请求后,发送自己的 server_id 和 offset 给从节点
- 从节点记录下主节点的 server_id 和同步的 offset
- 主节点 fork 一个子进程后台生成 RDB 文件,发送给从节点
- 从节点收到 RDB 文件后,开始同步主节点数据
这个过程存在一个问题:在生成 RDB 期间,如果有新的写命令,是不会包含在 RDB 中的,那么从节点如何获取这些增量数据呢?
为了解决这个问题:
- 主进程会在生成 RDB 期间,将
增量写命令写到 replication buffer 中 - 从节点同步完 RDB 以后,会给主节点发送同步完成的消息
- 主节点收到同步完成的消息以后,会将 replication buffer 的命令发给从节点
- 从节点重放 replication buffer 的命令,第一次同步完成
多个从节点同时发起 SYNC 请求,Redis 如何处理?
SYNC 请求的到达肯定有个先后顺序
主节点收到第一个 SYNC 请求,会执行上述步骤
接下来的 SYNC 请求,会被缓存到一个队列中,当 RDB 生成完了以后,发给剩余的从节点
这里引用小林的 一篇文章 的图片来展现整个过程:
第一次同步结束后的过程
第一次同步结束后,从节点与主节点会建立 TCP 长连接,用于 同步实时写命令
当主节点执行了一个写命令后:
- 主节点将该命令添加到 repl_backlog_buffer 中;
- 主节点通过已经建立的 TCP 长连接,将这个写命令发送给所有的从节点;
- 从节点接收到这个命令后,会将其放入自己的本地队列中,然后按序执行这个命令来更新自己的数据集;
- 主节点在发送命令后不会等待从节点的响应,它会继续处理自己的操作请求。
这种同步的方式叫做「基于长连接的命令传播」
推 VS. 拉
在 Redis 的主从复制机制中,主要采取的是 从节点主动拉取数据 的方式。
虽然主节点在一定程度上向从节点推送数据(例如实时写命令),但整个同步过程始终是从节点发起并控制的。
因此,Redis 的复制机制可以概括为“从节点拉取数据,而主节点推送增量更新”的混合模式,但主体过程是由从节点拉取数据驱动的。
增量同步
如果从节点到主节点的网络发生了 延迟,那么从节点无法及时获取到主节点最新的数据
当网络恢复以后,从节点的同步过程如下:
从节点向主节点发起同步请求(PSYNC),并携带主服务器的 server_id(这里为第一次同步获得的 server_id)、offset(这里为同步的进度)
主节点收到同步请求,如果:
- server_id 与自己的 id 一致
- offset 对应后续的数据仍存在 repl_backlog_buffer 中
就会执行 增量同步,不会生成新的 RDB 文件,而是直接将 repl_backlog_buffer 中要同步的数据发给从节点
repl_backlog_buffer 是一个 环形 的缓冲区,一个主节点只有一个 repl_backlog_buffer,默认大小为 1M,如果写满了,就会从头开始写数据(即覆盖原数据)
如果覆盖了从节点要同步的数据,就只能走全量同步了
因此,如果从节点同步速度比较慢,可以适当增加 repl_backlog_buffer 的大小,防止全量同步
举个例子,如果主节点每秒产生 1M 数据,从节点同步 1M 数据需要 5s 时间,那么 repl_backlog_buffer 至少要大于 5M 才能避免全量同步
为了应对突发情况,可以设置为此基础上的 2 倍
如何判断一个节点是否正常工作
主从节点互相基于「心跳检测」机制来判断对方是否下线
如果半数以上的节点 ping 一个节点都没有 “pong” 回应,redis 集群会认为这个节点客观下线,会断开与这个节点的连接
而主节点与从节点的 ping 的时间间隔也有所不同:
- 主节点默认每隔 10s(repl-ping-slave-period) 会向从节点发送 ping,判断从节点的健康情况
- 从节点默认每隔 1s 向主节点发送 replconf ack{offset} 命令,上报自己的 offset 情况,可以:
- 检测主节点是否掉线
- 自己的同步进度是否落后
如何应对主从不一致
首先需要保证主从之间的网络情况比较好,可以将主从节点部署在同一个机房中,走内网通信
此外,可以监控从节点的同步情况,如果落后比较多,那么就不在这个从节点上读取数据,防止读到过期数据
数据丢失
主节点宕机
考虑这种情况:
- 主节点正在发送增量数据给从节点
- 在发送过程中,主节点宕机
- Redis 哨兵发现主节点宕机,于是执行故障切换,选出新的主节点
- 原来的主节点上线,降级为从节点,向新的主节点同步数据
这个过程发生了 数据丢失
从节点还没有收到增量数据,主节点就挂了,那么整个集群就会丢失这一部分增量数据
主节点伪宕机
这种情况与上面的有所不同,主节点并不是真的宕机,而是由于网络延迟,被哨兵误认为宕机了
- 主节点正在发送增量数据给从节点
- 由于网络延迟,从节点未能成功收到增量数据
- 由于长时间的网络延迟,哨兵集群认为主节点客观下线,于是执行故障切换,选出新的主节点
然后,网络恢复了,整个集群就出现了两个主节点,这就是常说的「脑裂」现象
由于已经选出了新的主节点,原来的主节点会被降级成从节点,向新的主节点同步数据,于是增量数据就丢失了
如何 减小 脑裂带来的数据丢失
Redis 中有两个参数:
- min-slaves-to-write x,主节点必须要有至少 x 个从节点连接,如果小于这个数,主节点会 禁止写数据。
- min-slaves-max-lag x,主从数据复制和同步的延迟不能超过 x 秒,如果主从同步的延迟超过 x 秒,主节点会 禁止写数据。
当发生网络延迟,主节点会 误认为从节点下线了(ping 不通),会禁止写数据
此外,由于网络延迟,主从复制的延迟也会增加,当延迟超过 min-slaves-max-lag,也会禁止写数据
合理配置这两个参数,可以有效 减少 丢失的数据
这里一直在强调是 减少 丢失数据,而不是 避免 丢失数据
因为检测到从节点下线,或者主从延迟超过 min-slaves-max-lag,这个过程是需要时间的
如果这段时间内,主节点写入了新的数据,并且网络迟迟不恢复,那哨兵还是进行故障转移,这些数据还是会丢失
如何实现主节点宕机后的故障转移
故障转移的过程是由哨兵集群来实现的,具体内容可以查看 这篇文章