为什么要有哨兵
Redis 哨兵主要负责:
- 集群健康状态监测
- 集群故障转移
- 通知
可以说,Redis 的高可用离不开哨兵
如何判断主节点故障
主观下线
前面提到,哨兵具有集群健康状态监测的功能
每个哨兵会每隔 1s 给每个节点发送 Ping 命令,如果某个节点在规定时间内(down-after-milliseconds 参数决定)没有响应,那么这个节点会被认为下线了
这个就叫做主观下线:哨兵节点 主观认为 节点下线
客观下线
单个哨兵认为节点下线,这个结果的可信度较低,不能就直接认为某个节点下线了
当某一个哨兵认为某个节点下线,会给其它哨兵发一条消息,看看其他哨兵的意见:
- 如果超过 quonum 个哨兵认为该节点下线,那么哨兵集群就认为这个节点 客观下线
quonum 的值建议设为 n / 2 + 1,n 为哨兵的总个数
故障转移
由哪个哨兵进行故障转移
如果故障的是主节点,那么就要进行故障转移
那么该由哪个哨兵进行故障转移呢?
如果一个哨兵「主动」发现节点下线,那这个哨兵就是一个「候选者」
可能有多个哨兵都「主动」发现节点下线了,那么就会有多个候选者
每个候选者会给哨兵集群中的每一个哨兵发一个 leader 请求,表明自己想成为 leader,负责这一次故障转移:
- 每个哨兵仅有一票
- 候选者会自己给自己投一票
- 其他哨兵,只要收到一个 leader 请求,就给这个候选者投票
如果一个候选者的得票数 超过半数(n / 2 + 1),并且 大于等于哨兵配置文件中的 quorum 值,那么认为这个候选者就是 leader
经过上面哨兵内部的选举过程,成功选出了一个 leader,接下来,就由这个 leader 来负责故障转移的过程
过程
选择新的主节点
首先要排除网络不佳的节点
前面提到了一个 down-after-milliseconds 参数,如果一个节点在 down-after-milliseconds 内没有响应哨兵的请求,那么会被认为主观下线
主观下线的次数会由哨兵集群维护,如果一个节点主观下线的次数超过了 10 次,那么认为这个节点的网络不佳
排出了网络不佳的节点后,在剩余从节点中选择出新的主节点,选择的依据如下:
- 节点优先级(slave-priority,由用户配置):slave-priority 越低,优先级越高
- 同步偏移 offset:如果优先级相同,那么比较 offset,同步的数据越多,优先级越高(丢失的数据越少)
- server_id:如果节点优先级和 offset 都相同,server_id 越小,优先级越高
选择出新的主节点后,哨兵会给这个从节点发送一个 SLAVEOF no one 命令,让其独立成一个主节点
发送完 SLAVEOF no one 命令后,哨兵会监控这个节点的状态(每秒一次,INFO 命令),直到这个节点的状态为 master
将从节点指向新的主节点
当从节点成功升级为新的主节点后,哨兵会给其它从节点发送 SLAVEOF <new_ip> <new_port>,以让其它从节点修改自己的 master 为新的主节点
通知客户端主节点发生更改
现在,故障转移基本完成,只需要通知客户端最新的主节点是谁就可以了
怎么通知?
客户端与哨兵之间通过「发布-订阅」机制来实现通信
客户端会订阅 +switch-master 频道,当故障转移完毕后,哨兵会向这个频道发送新的主节点的 IP 和 Port,这样客户端就能知道新的主节点的信息了
监视原来的主节点的上线情况
哨兵还需要监视原来的主节点是否上线,如果上线,需要发送一个 SLAVEOF <new_ip> <new_port>,将其降级为从节点
为什么要部署多个哨兵节点,一个不行吗?
前面提到:单纯一个哨兵主观认为一个节点下线,这个是不可信的
因为完全有可能是哨兵自己出现了问题,而非主节点出问题
因此,为了保证可靠性,部署的是多个哨兵节点组成集群(至少大于等于 3 个)
此外,只部署一个哨兵节点,如果哨兵都挂了,整个集群都没有“领导者”了,成了一盘散沙,故障转移无法实现
哨兵集群的组成
哨兵间如何通信
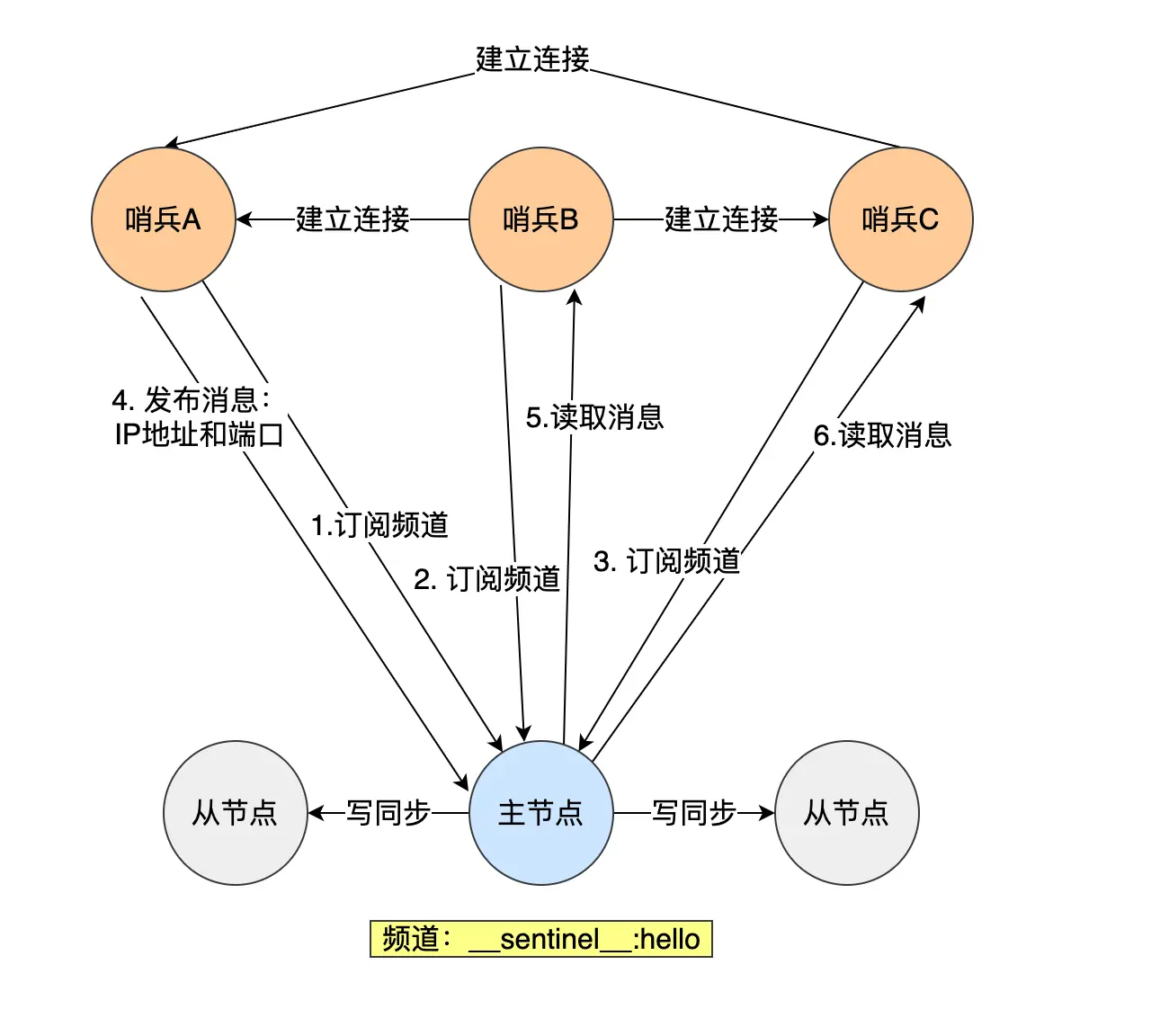
在哨兵的配置文件中,并没有配置其它哨兵的 IP 和 Port,那哨兵是如何发现彼此的呢?
还是依靠「发布-订阅」机制
在 Redis 的集群中,会有一个频道 __sentinel__:hello,每个哨兵都会订阅这个频道:
- 当一个哨兵上线,会向这个频道发送自己的 IP 和 Port
- 其它哨兵订阅这个频道,就可以读取到这个哨兵的 IP 和 Port,进而建立通信
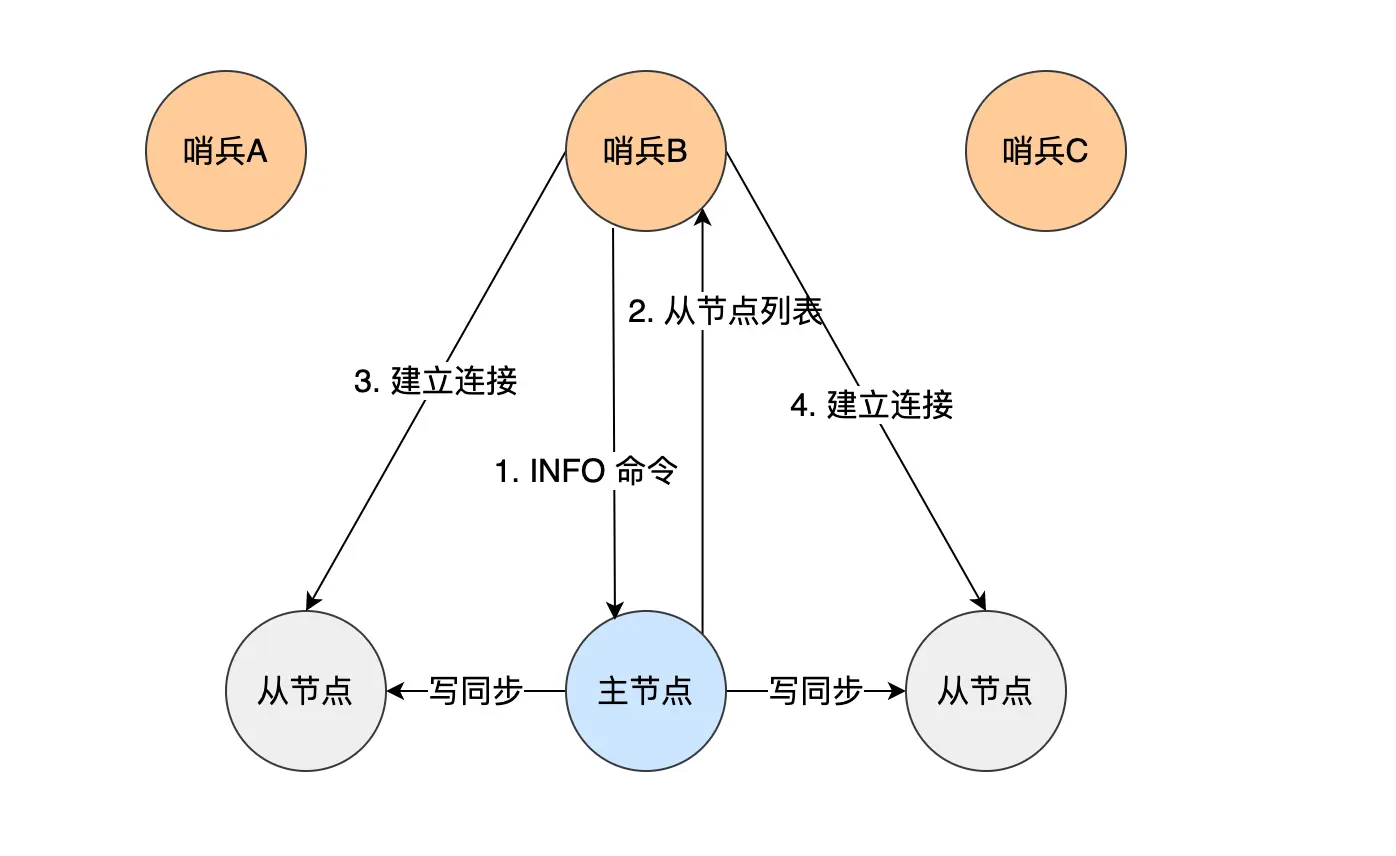
哨兵如何获取其它子节点的信息
哨兵会定期向主节点发送 INFO 信息,获取子节点列表,这样,哨兵就可以知道其它子节点的 IP 和 Port 了