Server State
要实现日志复制,Server 需要维护以下状态:
type Raft struct {
// ...
commitIndex int // index of highest log entry known to be committed
applyIndex int // index of highest log entry to be applied
nextIndex []int // for each server, index of the next log entry to send to that server (initialized to leader last log index + 1)
matchIndex []int // for each server, index of highest log entry known to be replicated on server (initialized to 0, increases monotonically)
applyCh chan ApplyMsg // a channel on which the tester or service expects Raft to send ApplyMsg messages.
}
- commitIndex:可以提交的日志的最大 Index
- applyIndex:已经提交的日志的最大 Index
- nextIndex[i]:要发送给 peers[i] 的起始日志 Index
- matchIndex[i]:peers[i] 已经同步的日志 Index
- applyCh:当一个日志被提交,Leader 将这个日志发送到 applyCh,相当于在本地执行命令
Start 方法
Leader 需要实现 Start 方法:
func (rf *Raft) Start(command interface{}) (int, int, bool)
Start 方法会被上层客户端调用,请求在 Raft 集群执行 Command
返回值:
- index:该 command 如果被提交,在整个 Logs 中的 Index
- Term:Leader 当前的 Term
- isLeader:自己是不是 Leader
具体步骤:
- 检查自己是不是 Leader,如果不是,直接返回
- 将 Command 封装成 Log,追加到 rf.logs 中
- 返回
为了提高性能,不要每次调用 Start 方法,都尝试发送一次 AE RPC,而是「批量」发送,真正的发送操作,在后台任务 startReplica 这里
AppendEntries RPC
参数与返回值:
type RequestAppendEntriesArgs struct {
Term int // leader's term
LeaderId int // leader's id
PrevLogIndex int // index of log entry immediately preceding new ones
PrevLogTerm int // term of prevLogIndex entry
LeaderCommitIndex int
LeaderCommitTerm int // term of lastCommitLog
Entries []*Entry // Logs
}
type RequestAppendEntriesReply struct {
Term int
Success bool
}
AppendEntries RPC 逻辑:
- 如果 term 小于自己的 term,直接 return false
- 如果 rf.logs[args.LeaderCommitIndex].Term == LeaderCommitTerm,更新 rf.commitIndex(建议只要 Term 合法,就更新 commitIndex,以便快速应用 Command 到本地)
- 如果自己的 Logs 中,在 prevLogIndex 处,Log 对应的 term 与 prevLogTerm 不一致,return false
基于 args.PrevLogIndex 截断本地日志- 判断 AE RPC 是否乱序,根据判断结果决定是否 append entries 到本地日志
- return true
2024.5.28 更新:AE RPC 也需要检查是否乱序的问题
这个问题之前测试一直没有发现,直到 Lab4A 才显现出来
实现时,需要检查每个 entry,如果 entry 不在 rf.Logs 中,或者 entry 在 rf.Logs 对应位置处的 Term 不相等,才从这条 entry 开始 append
否则,Follower 可能出现日志部分丢失的情况
2024.5.30 更新:如果是一个过期的 AE RPC,不应该更新 commitIndex!
假设原来的 commitIndex=106,如果收到过期的 AE,可能包含的 LeaderCommitIndex 比 commitIndex 小(例如 104)
如果 Follower 已经 apply 了 [0~106] 的日志,再将 commitIndex 更新为 104,显然不合理
如果 Follower 返回 false,Leader 怎么处理?
Follower 返回 false,说明还需要发送 entries 以外的数据给 Follower,Leader 需要给 nextIndex[i] 减一,然后再次尝试发送 AE,直到成功
「减一」,这样会不会发送很多次 RPC 以后,才能成功?能不能优化?
论文给出的解释是这样的:
如果需要的话,下面的协议可以用来优化被拒绝的 AppendEntries RPCs 的个数。
比如说,当拒绝一个 AppendEntries RPC 的时候,follower 可以包含冲突条目的任期号和自己存储的那个任期的第一个 index。借助这些信息,leader 可以跳过那个任期内所有的日志条目来减少 index。这样就变成了每个有冲突日志条目的任期只需要一个 AppendEntries RPC,而不是每一个日志条目都需要一次 AppendEntires RPC。
在实践中,我们认为这种优化是没有必要的,因为失败不经常发生并且也不可能有很多不一致的日志条目。
当然,我在实现时,还是做了一个相对简单的优化:
类似 TCP 的慢开始阶段,每次发送失败,rf.nextIndex[serverID] = max(rf.nextIndex[serverID] - offset, 0),其中,offset 会随着 AE 失败而 指数 递增,当 offset 超过门限值 threshold = 64 时,线性递增
当然这个方式存在一个小问题:无法准确找到第一个 Log 一致的位置,会存在多发送 Log 的情况,可以控制 threshold 的大小来减缓这个情况
不过,这个开销像较于多次发送 AE RPC 来说,还是比较小的
2024.5.19 更新:
实现 Lab3C 时遇到了 one(xxx) failed to reach agreement 的问题,于是将发送 AE 这个操作改成「异步」发送
修改过后,使用这个方式,不太好控制 offset(多个 goroutine 乱序,offset 很难修改正确)
于是,放弃了这个优化,最终采用论文提到的优化方式
Background Task
主要有两个后台任务:
- startApply
- startReplica
startApply
startApply 会定时将已经提交的日志应用到本地(无论是 Leader 还是 Follower)
步骤如下:
- 更新 commitIndex(如果是 Leader)
- 向 applyCh「提交」日志
怎么更新?
使用「二分」思想快速确定:
- L = commitIndex(旧的),R = len(rf.logs) - 1
- 检查 (L + R) / 2 这个 Index 是否可以提交
- 剩余二分逻辑…
而「检查」一个 Index 是否可以提交,需要看看 rf.matchIndex,如果超过半数的 rf.matchIndex 都大于等于该 Index,那么是可以被提交的
startReplica
Leader 在初始化时,会新建 len(rf.peers) - 1 个 startReplica 后台任务,分别处理与 Follower 的日志同步
步骤如下:
- 检查自己是不是 Leader,如果不是,休眠等待
- 封装 RequestAppendEntriesArgs
- 向自己负责的 peer 发送 AE 请求,异步 等待响应
- 如果发送失败,休眠等待下一次重试
- 检查 peer 的响应结果:
- 如果成功,更新 nextIndex[i] 为 len(logs),matchIndex[i] 为 len(logs),
offset = 1 - 如果失败:
- 如果 Follower 的日志太短,更新 nextIndex[i] 为 Follower 的 len(logs)
- 否则,更新 nextIndex[i] 为本地最后一条 Term 为 XTerm 日志的 index(核心思想是跳过一整个 Term,而不是 nextIndex[i]–,具体可以看我在 Lab3C 部分提到的:如何应对 Follower 拒绝 AE 请求 , 上面 也有提到)
- 如果成功,更新 nextIndex[i] 为 len(logs),matchIndex[i] 为 len(logs),
- 重置休眠计时器
正确性验证
单次测试结果:
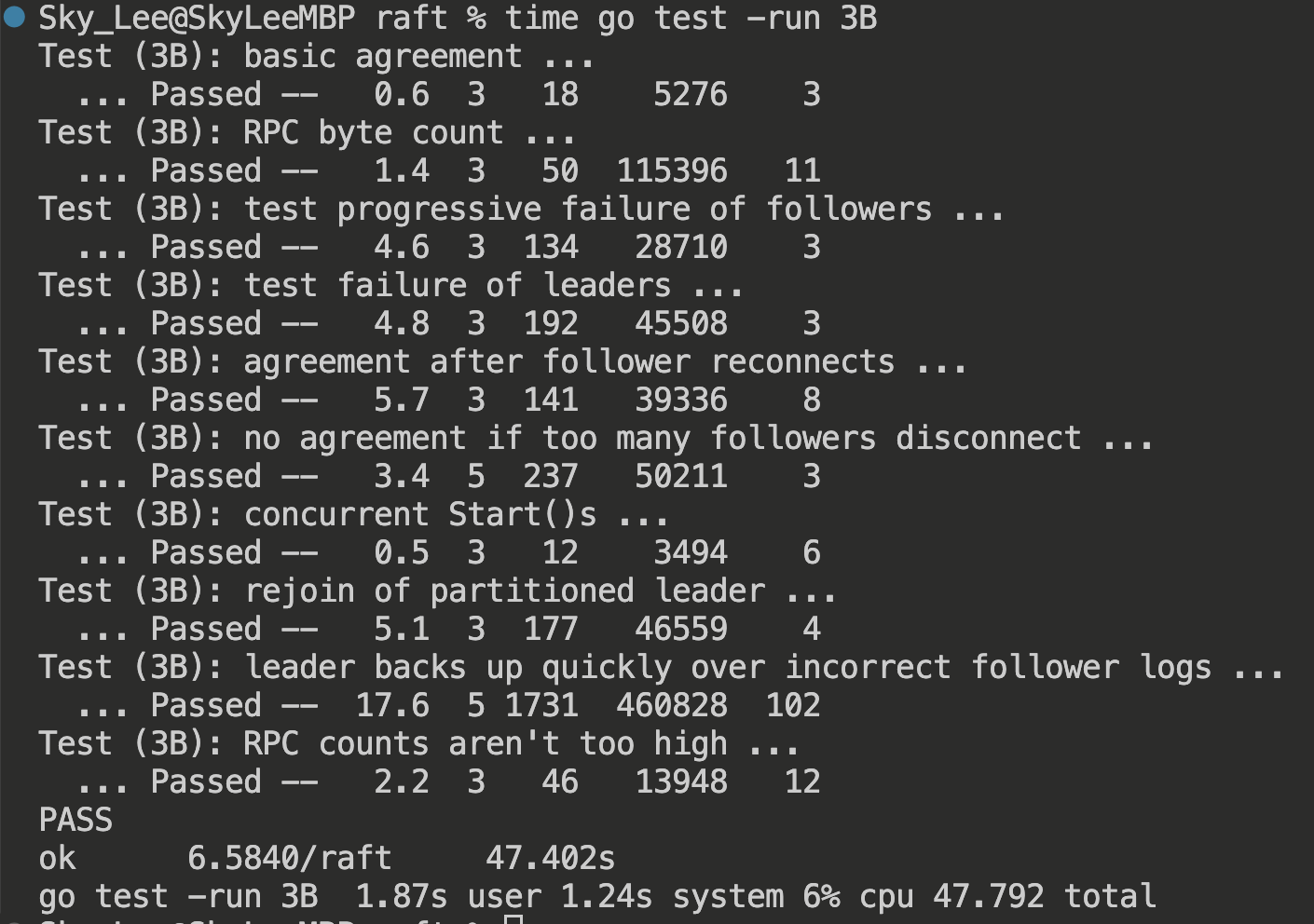
循环测试 100 次结果:
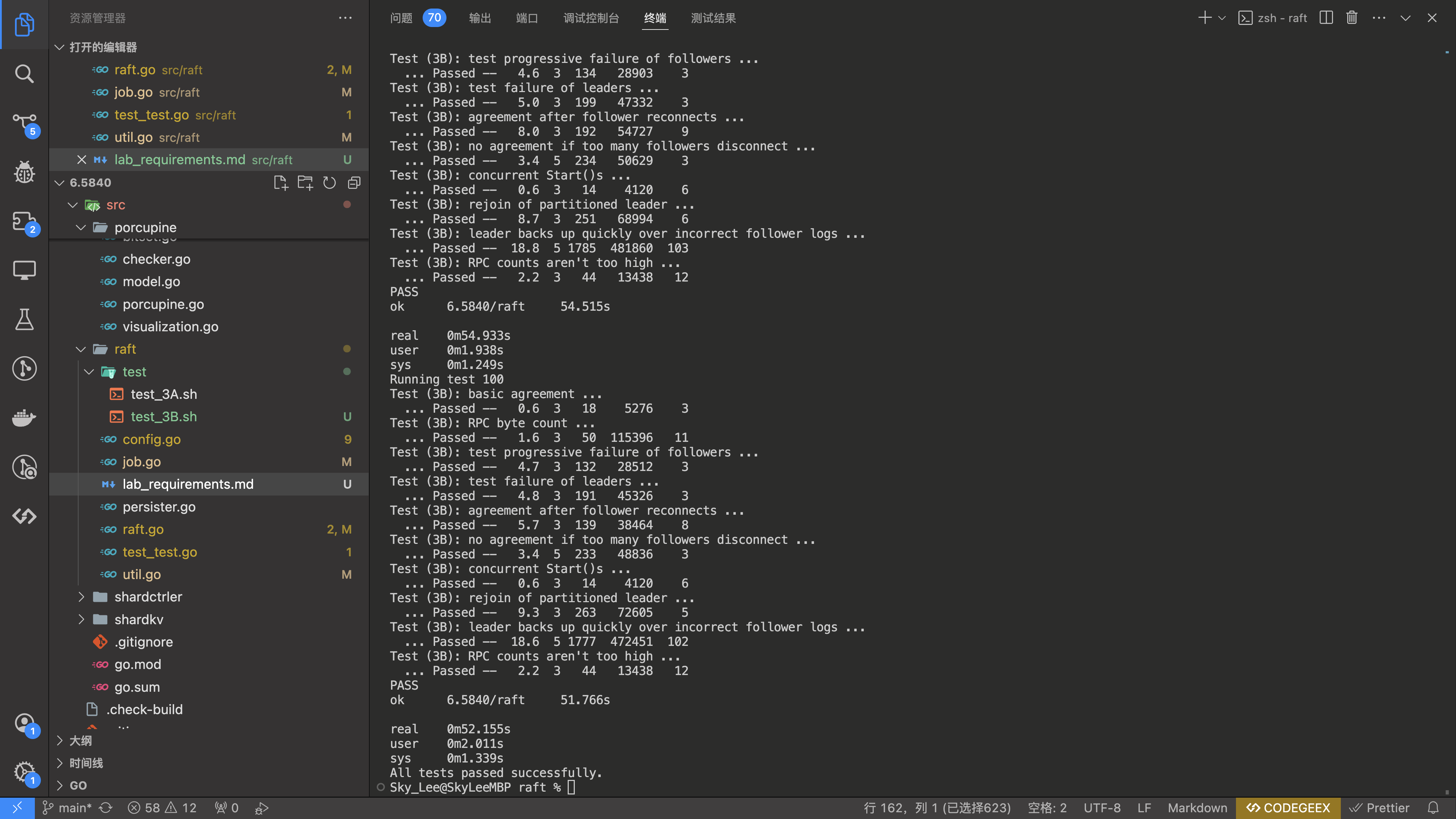
踩的坑
Log 的 Index 从 1 开始,而不是 0
lab 提供的 test_test.go 文件认为 Log 的 Index 从 1 开始,实现时需要注意封装 ApplyMsg 时,将 index 设置为 1 开始,而不是 0
2024.5.20 更新
可以引入一个「哨兵日志」来解决这个问题
同时减少冗余代码
日志不一致问题
测试用例是 TestRejoin3B 函数
func TestRejoin3B(t *testing.T) {
servers := 3
cfg := make_config(t, servers, false, false)
defer cfg.cleanup()
cfg.begin("Test (3B): rejoin of partitioned leader")
cfg.one(101, servers, true)
// leader network failure
leader1 := cfg.checkOneLeader()
cfg.disconnect(leader1)
// make old leader try to agree on some entries
cfg.rafts[leader1].Start(102)
cfg.rafts[leader1].Start(103)
cfg.rafts[leader1].Start(104)
// new leader commits, also for index=2
cfg.one(103, 2, true)
// new leader network failure
leader2 := cfg.checkOneLeader()
cfg.disconnect(leader2)
// old leader connected again
cfg.connect(leader1)
cfg.one(104, 2, true)
// all together now
cfg.connect(leader2)
cfg.one(105, servers, true)
cfg.end()
}
该函数的执行逻辑:
- 先在 Raft 集群中确认 Command = 101
- 让 Leader1 离线
- 调用 Leader1 的 Start 方法,在 Leader1 本地追加 102、103、104 三条 Command(因为已经离线,无法得到 Follower 的 ACK,只能调用 Start 而不是 one)
- 剩余的两个 Follower 选举成功,在 Raft 集群中确认 Command = 103
- 让 Leader2 离线
- 让 Leader1 上线
- 在 Raft 集群中确认 Command = 104
- 让 Leader2 上线
- 在 Raft 集群中确认 Command = 105
主要问题在 index=2 处,出现了数据不一致的问题
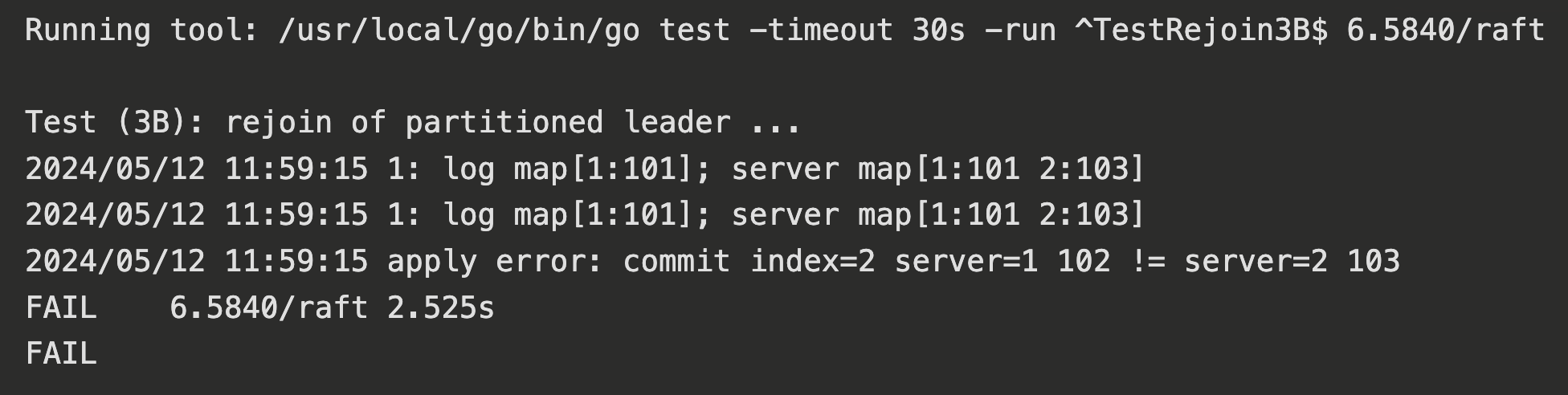
逐步分析一下问题在哪:
起初,三个 Server 都在线,状态如下:

然后,Leader1 离线,客户端在 Leader1 执行三次 Start:

然后,集群选举出新的 Leader(Leader2),客户端在集群确认 Command = 103(确认成功,然后 apply,此时,就已经确定了 index=2 处,Command = 103 了):

然后,让 Leader2 离线,Leader1 上线,Leader1 在给 Server3 发送心跳时,会发现 Server3 的 Term 比自己大,于是 Leader1 切换状态为 Follower
现在,整个集群就一个 Leader2,并且离线,自然选出新的 Leader
假设 Server3 选举成新的 Leader(Leader3)

Leader3 会给 Server1 发送心跳,于是,Server1 无条件 更新 rf.commitIndex = min(args.LeaderCommitIndex, len(rf.logs) - 1),即更新为 2
更新以后,后台任务 startApply 自然会提交 Index=2 处的日志(Command = 102)
但是 Index=2 的日志已经被 Server2 提交过了,这里就出现了 数据不一致
如何解决?
问题出现在 Server1 在没有依靠新的 Leader(即 Leader3)覆盖本地日志前,提交了 过期 的 Log
我们只需要 添加更新 CommitIndex 的条件 即可:
if args.LeaderCommitIndex >= 0 && args.LeaderCommitIndex < len(rf.logs) && rf.logs[args.LeaderCommitIndex].Term == args.LeaderCommitTerm {
// Update commitIndex
// Need to pay attention to the situation when LeaderCommitIndex is greater than len(rf.logs) - 1
rf.commitIndex = min(args.LeaderCommitIndex, len(rf.logs) - 1)
}
复制时间太长
在最后一个测试 TestBackup3B 中,复制日志的时间太长导致超时无法通过
后面使用 前文 提到的 RPC Call 优化方法,就 ok 了
总测试时间太长
6.824 Lab3B 的提示说到了:
The “ok 6.5840/raft 35.557s” means that Go measured the time taken for the 3B tests to be 35.557 seconds of real (wall-clock) time. The “user 0m2.556s” means that the code consumed 2.556 seconds of CPU time, or time spent actually executing instructions (rather than waiting or sleeping).
If your solution uses much more than a minute of real time for the 3B tests, or much more than 5 seconds of CPU time, you may run into trouble later on. Look for time spent sleeping or waiting for RPC timeouts, loops that run without sleeping or waiting for conditions or channel messages, or large numbers of RPCs sent.
一开始通过全部测试用例,总用时为 80s 左右,比较慢
后面发现 startReplica 和 startApply 每一轮的睡眠时间较长,均为 200ms
修改为:
func getApplyTimeout() time.Duration {
return time.Millisecond * 25
}
func getReplicaTimeout() time.Duration {
return time.Millisecond * 50
}
即可将总用时平均控制在 50s 以内
2024.5.25 更新
Lab4A 要求 Service Operation 的速度比较快,50ms 执行一次 replica 还是太慢了,后面均改成了 10ms